
MoE
ICLR 2025 Oral IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识

京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文
智元机器人发布首个通用具身大模型

智元机器人发布首个通用具身基座大模型——智元启元大模型(Genie Operator-1),基于Vision-Language-Latent-Action(ViLLA)框架,由VLM和MoE组成,实现小样本快速泛化。


DeepSeek一口气开源3个项目,还有梁文锋亲自参与,昨晚API大降价

DeepSeek 发布了DualPipe和EPLB两个新工具以及训练和推理框架的分析数据,旨在帮助社区更好地理解通信-计算重叠策略和底层实现细节。
DeepSeek开源第二天,目标就是榨干GPU的所有性能,国产AI猛兽比年前OpenAI发布会更凶猛。

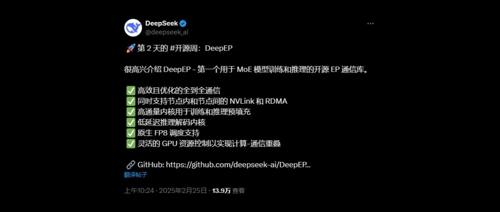
昨天DeepSeek开源第一天即收获9000颗星,今日其新项目DeepEP发布两天后已获3900颗星星。支持低精度计算、优化NVLink和RDMA数据转发等特性,专为混合专家(MoE)和专家并行(EP)设计的高效通信库。
DeepSeek开源第二天,主打一个硬核开源。
今天是DeepSeek开源周的第二天,Alibaba的QwQ-Max预览版引起了关注。DeepEP项目在GPU上实现了显著性能提升,并且已获1000+ GitHub星。DeepSeek强调硬件效率和低延迟通信,其新开源技术让数据传输和计算实现重叠。
DeepSeek开源放大招:FlashMLA让H800算力狂飙!曝光低成本秘笈

DeepSeek发布FlashMLA开源库,支持英伟达Hopper GPU。FlashMLA针对变长序列进行优化,显著提高推理速度和性能。