Transformer架构

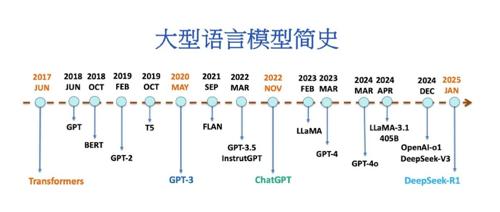
小米入局大模型赛道!开源MiMo-7B,性能超o1-mini

小米发布大模型MiMo-7B,参数70亿,在数学和代码测试中表现优异。MiMo-7B架构简单且效率高,通过MTP模块加速推理。训练数据集包含多种合成推理任务生成的数据,采用三阶段混合策略优化分布。后训练阶段通过SFT调整预训练模型,并使用高质量的强化学习数据提升性能。
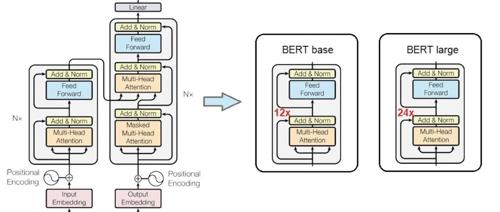


围观!斯坦福最火AI课全球免费开讲,顶级大佬亲授Transformer精髓,课表全放送

斯坦福推出免费在线课程CS25: Transformers United V5,涵盖Transformer架构及其应用,包括语言模型、强化学习、AGI等前沿话题。
大模型是怎么“思考”的?五分钟看懂大模型的底层逻辑!
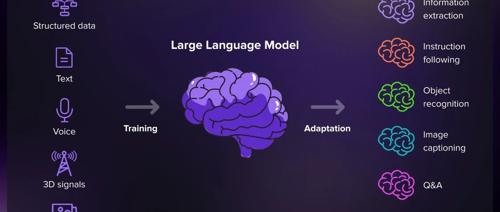
近年来ChatGPT爆火,让大语言模型走进大众视野。本文系统梳理了其原理、训练方式及其应用,涵盖数据、架构和训练三大要素,并展示了微调与实际应用场景,如客户服务、内容创作等。
阿里开源几秒内用人物照片3D建模跳舞,人人都可以是会跳舞的网红。

阿里开源的LHM项目基于Transformer架构,能够在几秒内从单张图像重建高保真、可动画的3D人体模型,提升重建准确性、泛化能力和动画一致性。