
A Visual Guide to Mixture of Experts (MoE)
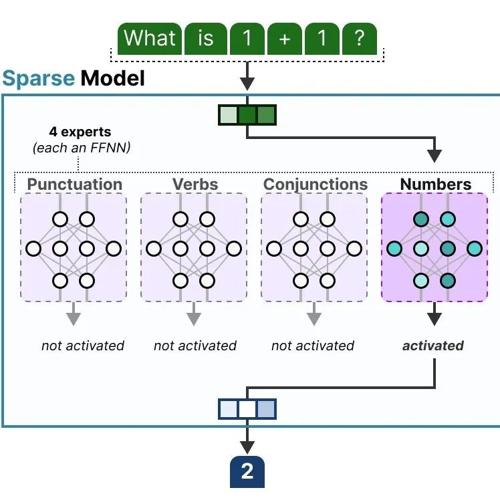
混合专家模型(MoE)通过动态选择子模型处理不同输入,显著降低计算成本并提升表现,核心组件包括专家网络、路由机制和稀疏激活。
混合专家模型(MoE)通过动态选择子模型处理不同输入,显著降低计算成本并提升表现,核心组件包括专家网络、路由机制和稀疏激活。

字节跳动豆包团队提出UltraMem架构,通过分层动态内存结构、Tucker分解检索和隐式参数扩展三项创新突破MoE架构的瓶颈,推理成本降幅最高83%,速度提升6倍,入选ICLR 2025。

