于是我带着强烈的好奇走上了这条一波三折的测评之路。
我一开始测试了好几个Case,有写作的,有代码的,有数学的。
初步觉得效果确实有提升,程度比官方说的高一点,但是离顶尖模型Claude4还是有明显差距。
左边是新版DeepSeek R1,右边是Claude4
左边是新版DeepSeek R1,右边是Claude4
是不是看起来还是有明显差距捏,而且Claude生成的网页是真的有数据交互的,会变化。新版DeepSeek R1的几乎没有
当时看到其他几位博主发的文章都是在吹DeepSeek的,瞬间感觉他们吹的有点过了?
测着测着,才发现不太对劲,DeepSeek R1是推理模型,我不应该给跟Claude4一样的复杂提示词呀!
卧槽!才想起来DeepSeek R1是不需要结构化复杂提示词的。
我呐个豆,这提示词搞复杂了是得多限制R1的发挥呀,改成一句话之后效果提升非常多。
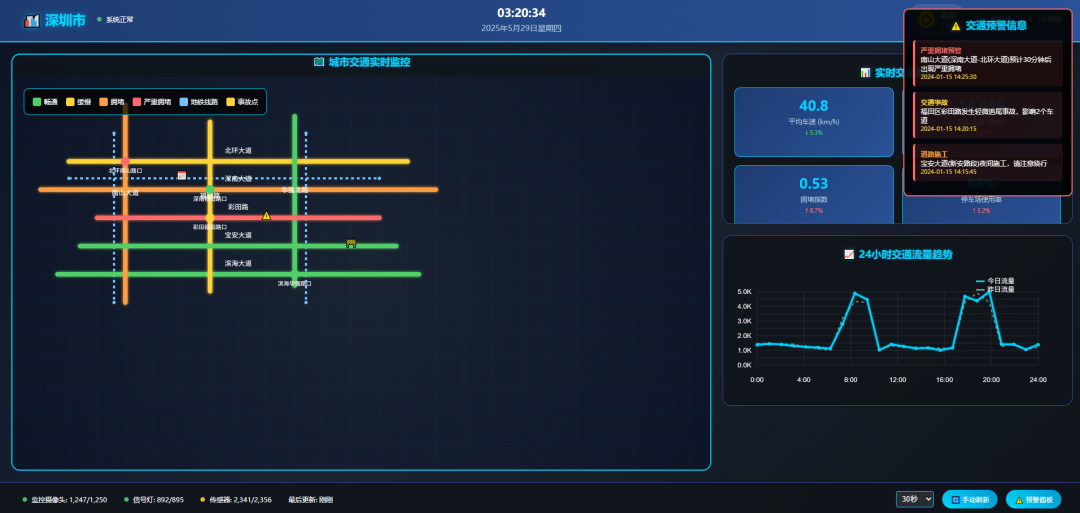
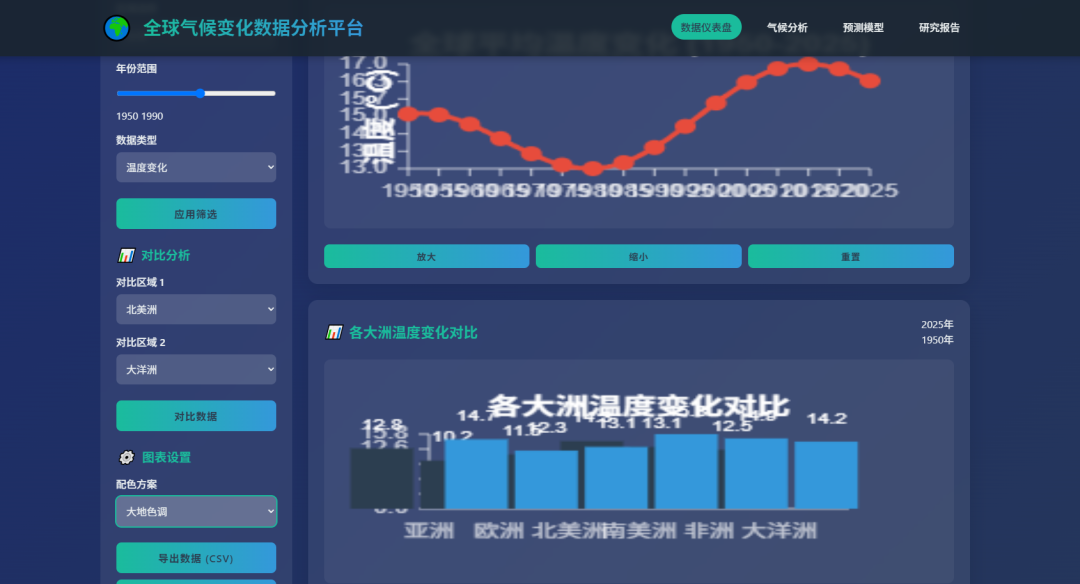
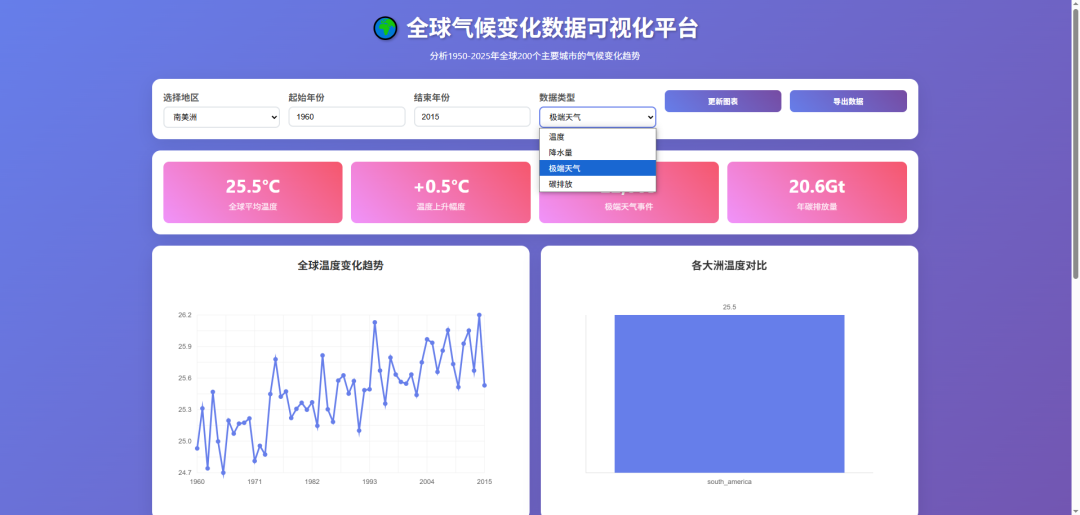
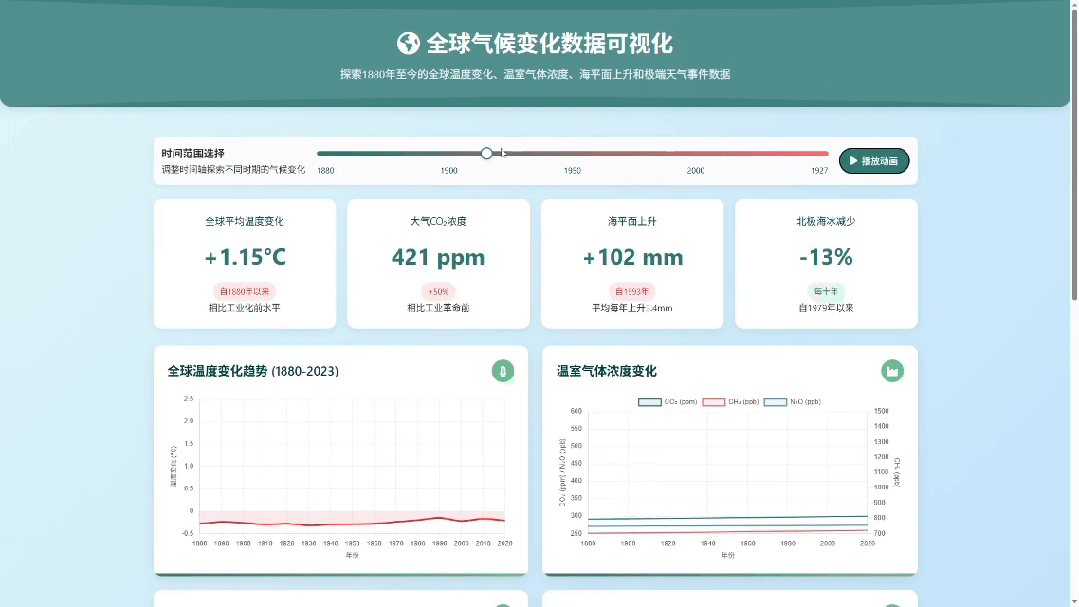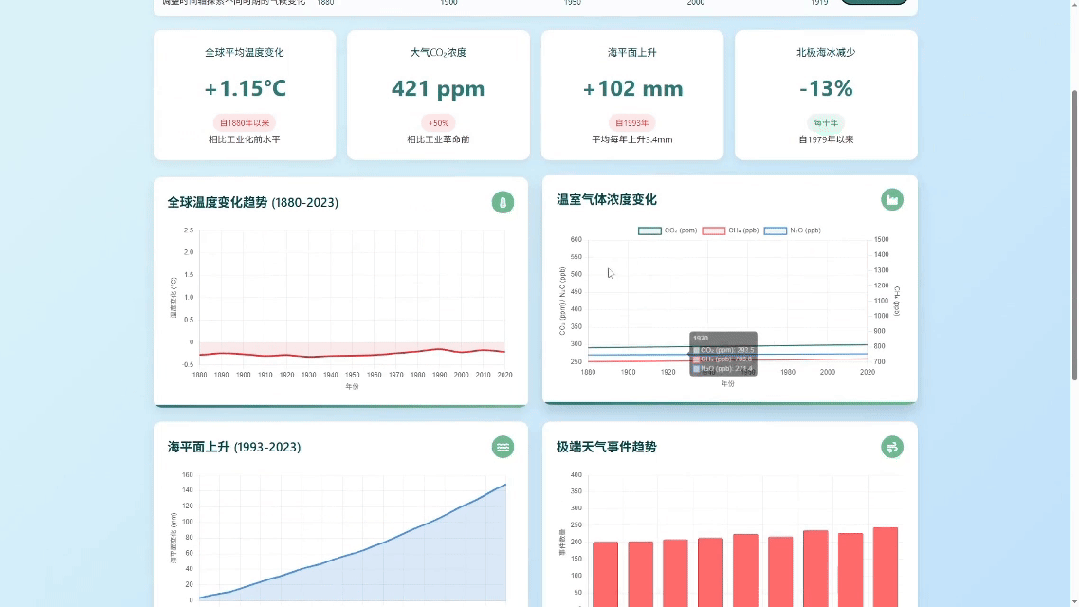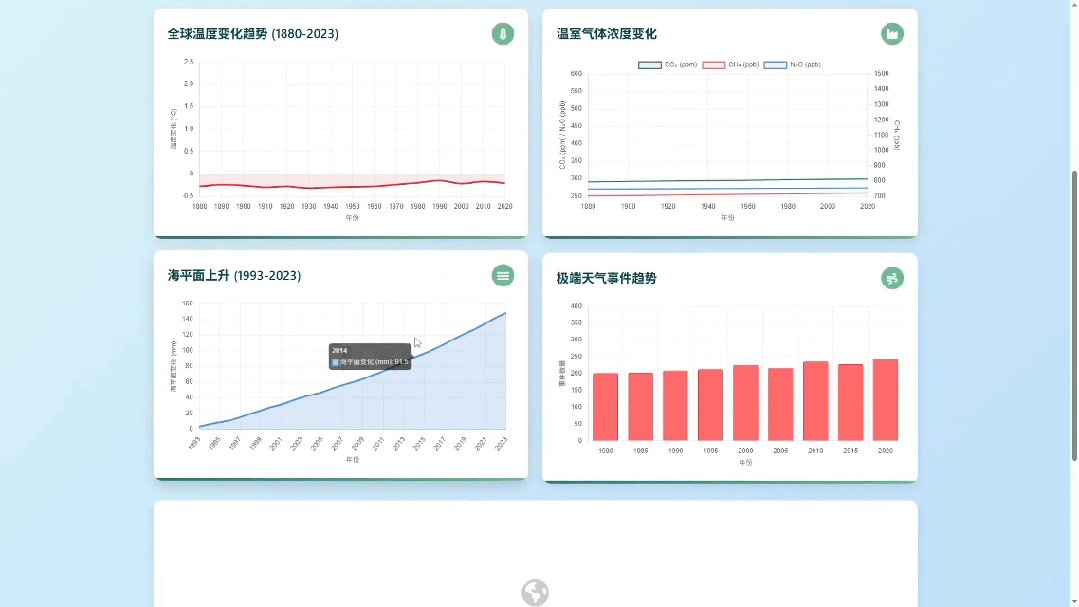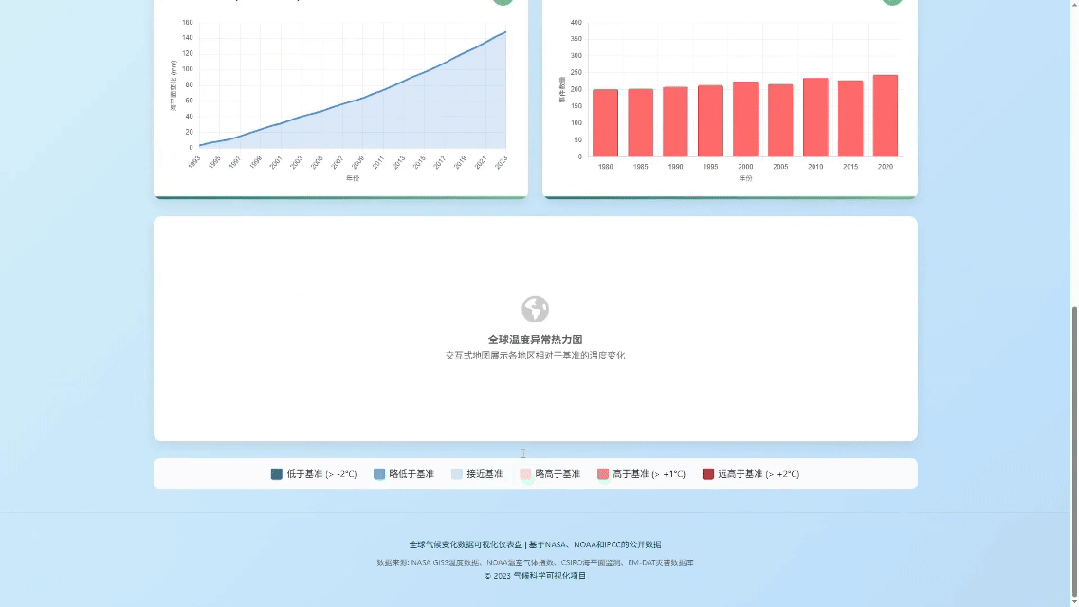
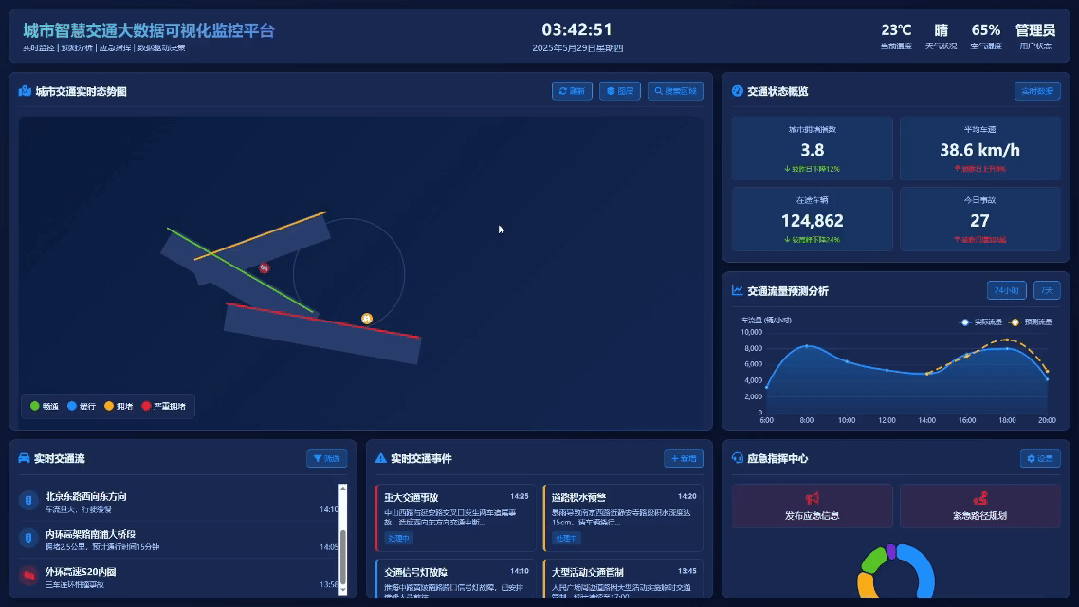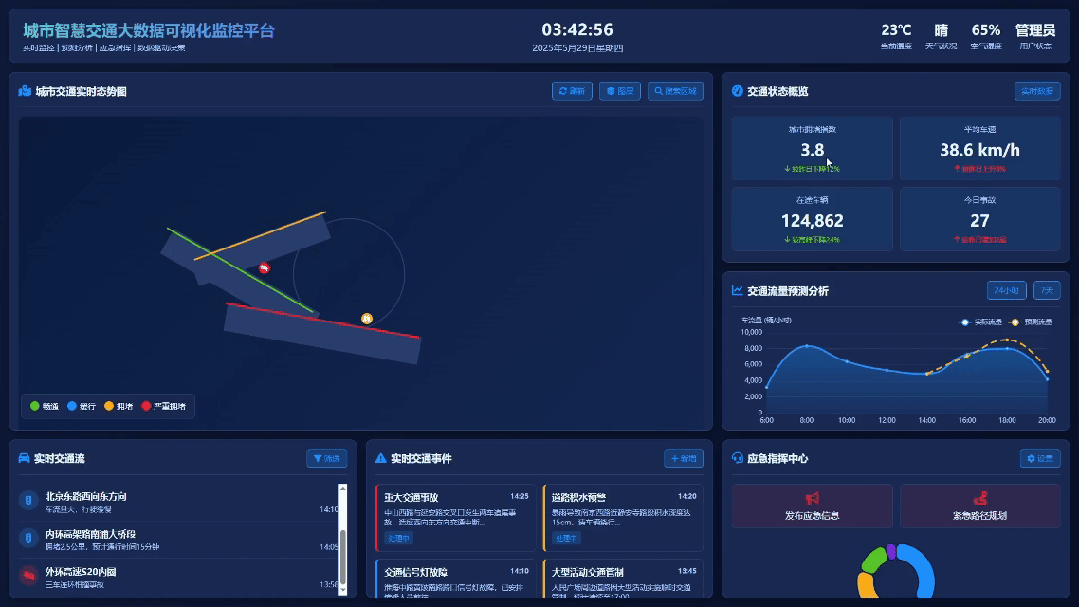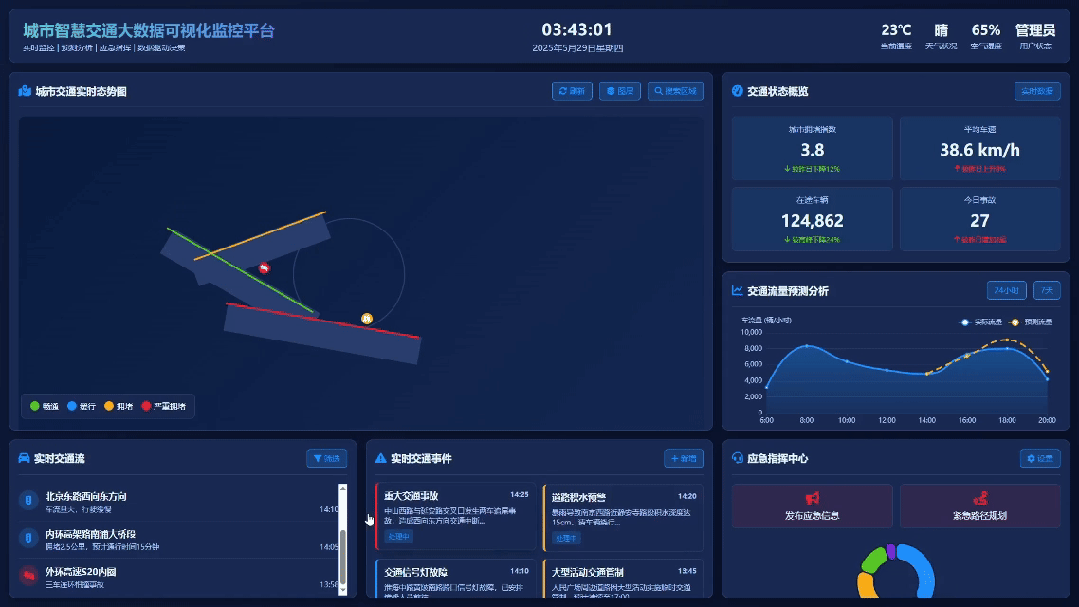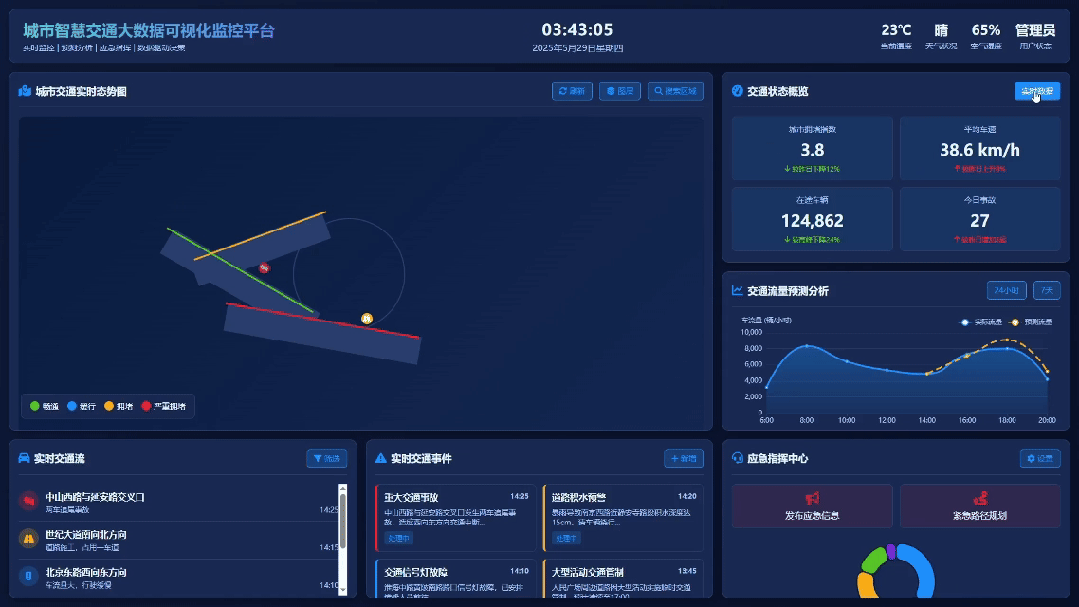
为了防止是偶然现象,我又跑了城市智慧交通大数据可视化监控平台的Case,还是一句话
对比一下之前的生成效果,这档次和审美是不是瞬间都上去了
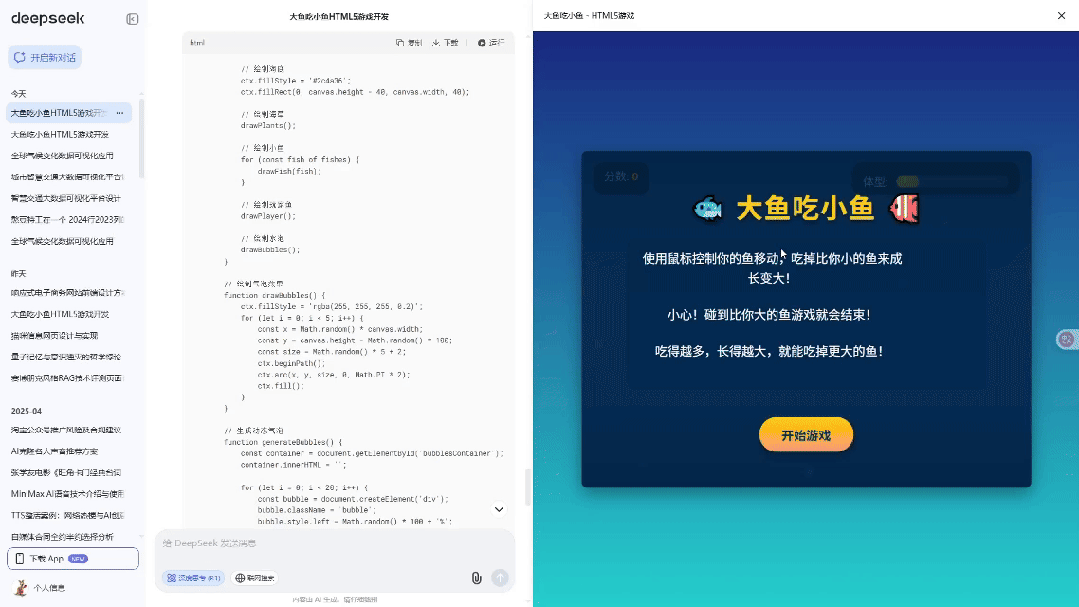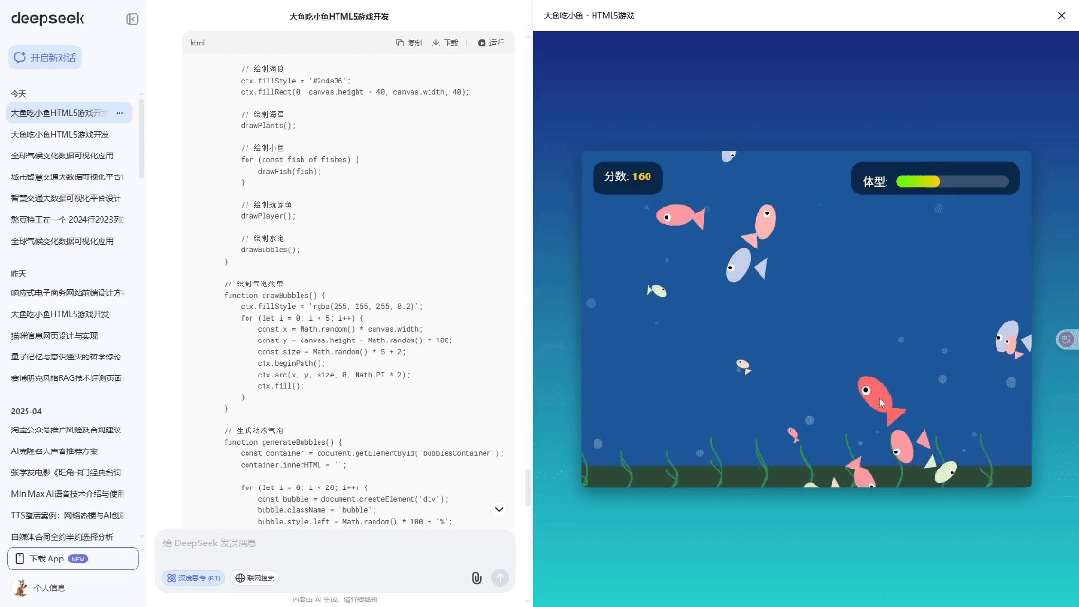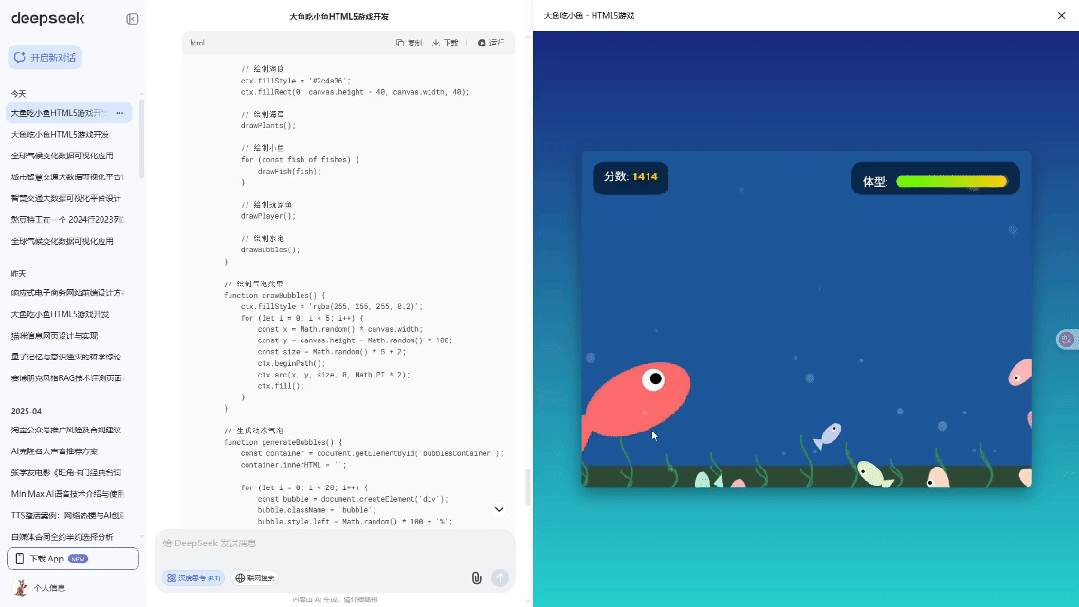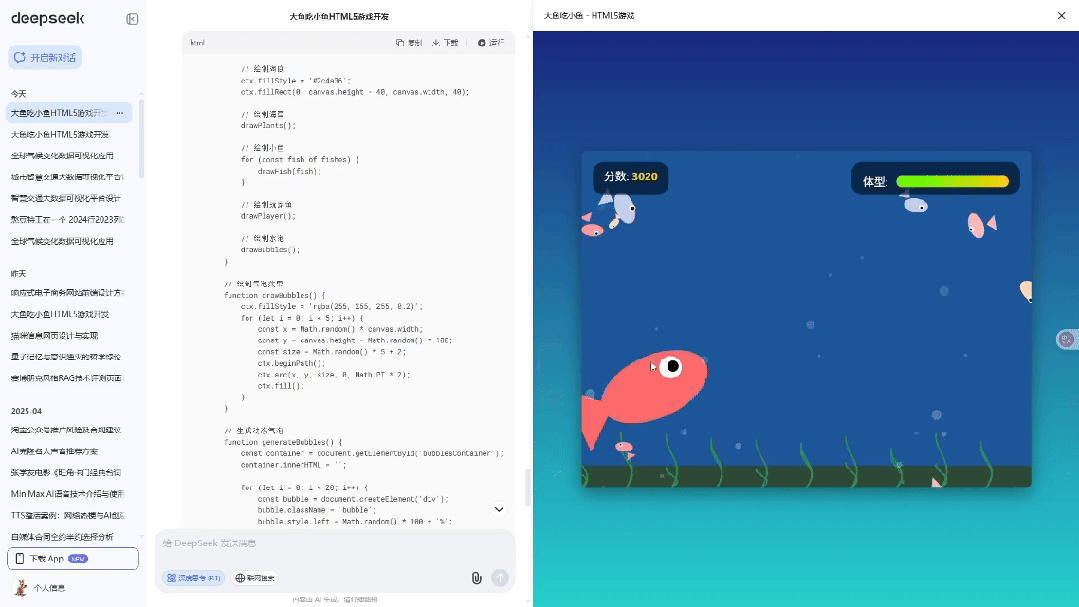
请为我开发一个简单但有趣的"大鱼吃小鱼"HTML5网页游戏
最近都去用gemini2.5 Pro和Claude4去了,好久没用DeepSeek R1,把R1的这个提示词平权能力忘了。
实测下来我的结论是代码能力大幅提升,确实不输Claude4了,可能还差那么一丢丢,但是已经非常接近。
大概率是用3月新发布的DeepSeek-V3-0324升级的R1,V3的0324就是代码能力大幅增强,所以这次的新版R1,代码和审美上的增强非常明显。
写作能力感觉有小幅提升,然后数学能力貌似提升不大,因为给了之前测过的一些比较难的奥数题,跑了半天还是没有给出正确答案。
不过,说实话,拿一个推理模型跟人家的基座模型Claude4比,其实已经输了…
但是我相信DeepSeek不久之后还会再创辉煌,静静等待R2的到来吧~
(文:开源星探)