奥特曼YC硬核访谈:走ChatGPT之路必死,世界差点没有OpenAI!

奥特曼在YC访谈中分享了OpenAI的创立历程、技术突破以及对未来的展望,强调推理模型的重要性,并鼓励创业者不要模仿ChatGPT。他提到了未来可能会集成的推理和多模态模型,并对未来十年充满期待。
奥特曼在YC访谈中分享了OpenAI的创立历程、技术突破以及对未来的展望,强调推理模型的重要性,并鼓励创业者不要模仿ChatGPT。他提到了未来可能会集成的推理和多模态模型,并对未来十年充满期待。

国产大模型推出DeepSite V2版本,实现网页生成的‘聊天式’体验,支持多语言指令、细粒度编辑和Diff Patching技术,简化前端开发流程,目前免费开放使用。
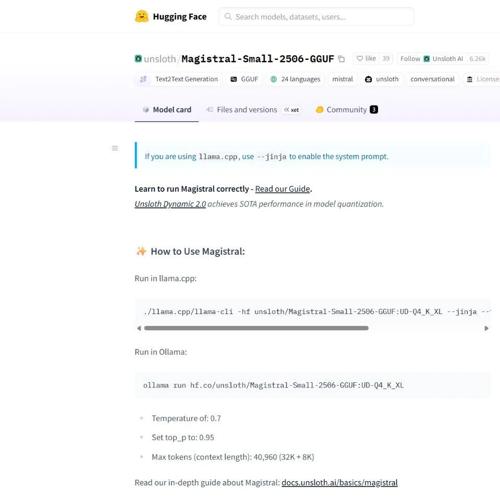
Mistral发布Magistral-Small-2506小模型,与Qwen3-4B类似大小且推理能力强,适合单卡32G运行,分数略高于Qwen3-4B。
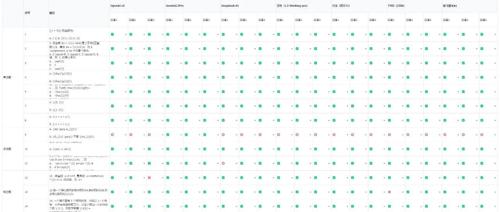
这篇文章描述了作者利用多个推理模型进行了一场数学高考的模拟测试,并详细介绍了测试规则。最终结果显示,Gemini表现最突出,而DeepSeek和Qwen3则表现较弱。通过这次测试,作者认为对于AI模型来说,数学高考并非特别难,但识别错误会影响结果。文章强调了考试公正性和严谨性的重要性。

沃顿商学院研究发现,奥特曼喜爱的直接回答提示词会显著降低模型准确率。同时,思维链(CoT)命令的效果也有限,并且可能导致答案不稳定增加计算成本。

ic 的首届开发者大会上,Anthropic CEO Dario Amodei 宣布 Claude