


新智元报道
新智元报道
【新智元导读】OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?
最多一年,推理模型就会撞上训练算力的「天花板」。
OpenAI的o3这样的推理模型,诞生还不到一年,能力已经突飞猛进。OpenAI的研究人员非常乐观地认为,这种趋势会持续下去。
但问题来了:推理模型到底还能进步到什么程度?
Epoch AI是一个独立的AI研究团队,专注于对大模型的发展速度、发展轨迹以及可能产生的社会影响进行前瞻性研究。
他们认为,推理模型确实还有进步空间,但想让OpenAI或者其他顶尖AI公司实现「指数级大飞跃」,基本不太可能。
按现在的节奏,每几个月计算能力翻10倍(就像o1到o3那样),估计最多一年就会撞墙。
到2026年,扩展速度将会放缓,回落到每年4倍的增速水平,模型的升级速度也会跟着变慢。

如果类似o1到o3这样的规模提升持续下去,推理计算资源增长的可能轨迹
研究的主要线索如下:
-
o3的训练算力是o1的10倍,基本是指推理训练阶段,o3在o1发布4个月后就推出了。
-
虽然不知道o1具体用了多少算力,但DeepSeek-R1可以用来参考。
-
英伟达的Llama-Nemotron、微软的Phi-4-reasoning,也透露出一些训练细节。
-
Anthropic CEO Dario Amodei也发表过相关看法。

OpenAI的o3和其他推理模型,都是从传统大语言模型发展而来的。
最开始,模型会用海量人工标注数据进行「预训练」;然后进入强化学习阶段,通过反馈优化模型解决难题的能力,这就是「推理训练」。
从历史上看,算力是AI发展的关键。
所以得搞清楚:现在推理训练到底用了多少算力?还能增加多少,这又会怎么影响模型的能力?
虽然推理模型在AI圈火得一塌糊涂,但推理模型的推理训练算力的公开信息却很少。

OpenAI发过一张图,对比o1和o3在AIME基准测试的表现,横轴是推理训练的算力。
它表明,o3的训练算力是o1的10倍。
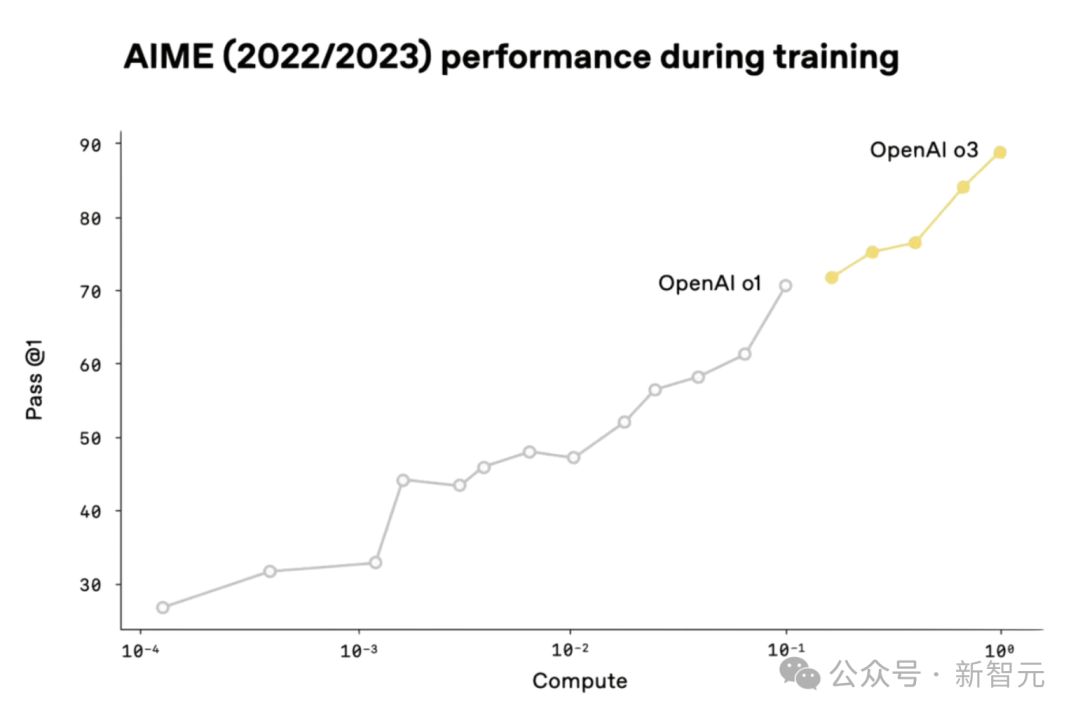
摘自OpenAI的o3直播发布会
为啥说横轴不是总算力?
因为o1早期版本的算力比o3少4个数量级,但AIME得分也有25%,要是算总算力,这个成绩就太离谱了。
此外,如果横轴是总计算资源,就意味着OpenAI训练了许多预训练阶段高度不完整的o1版本。
OpenAI研究员最近也透露,公司接下来打算重点发展强化学习,投入的计算资源会比训练初始模型时还要多。
o3具体用了多少算力?目前没实锤,得从其他模型和业内人士的话里找线索。
大部分AI公司都把训练细节捂得严严实实,但DeepSeek大方公开了R1的数据:
DeepSeek-R1在强化学习阶段花了6×10²³次浮点运算(成本约100万美元),生成了2万亿个token,大约是基础模型DeepSeek-V3预训练成本的20%。
这个数据虽然有误差,但仍然很有帮助,DeepSeek-R1和o1水平差不多,可作为基准。
不过,由于各种原因,DeepSeek-R1的推理算力可能与o1不同。两个模型参数量、计算效率都不一样,所以结果仅供参考。
英伟达的Llama-Nemotron Ultra 253B和微软的Phi-4-reasoning也公开过数据:
-
Llama-Nemotron Ultra:强化学习阶段用了14万小时H100算力(约1×10²³次浮点运算),不到基础模型预训练成本的1%。
-
Phi-4-reasoning:推理阶段规模更小,生成4.6亿个token,计算成本不到1×10²⁰次浮点运算,算力消耗不到预训练的0.01%。
这两个模型在基准测试中都取得了出色的成绩,Llama-Nemotron的成绩与DeepSeek-R1和o1相当。
但它们在强化学习阶段之前都做了「监督微调」,用了大量其他推理模型生成的高质量推理链示例,和o1、o3这种前沿模型的训练逻辑不太一样,参考价值有限。
总体而言,这些信息对于了解o1或o3的训练算力规模帮助有限。
有一点可以确定:像Phi-4这样的某些模型,推理训练计算资源(至少在强化学习阶段)可能相对较少。
这并不意味着o3也是用同样少的计算资源进行训练的,但这确实表明,仅从一个推理模型在基准测试中表现良好,很难判断其推理算力的规模。
此外,传统的监督微调在推理模型的开发中可能发挥着重要作用。由于训练方法多种多样,在没有公开训练细节的情况下,很难猜测推理模型的推理训练规模。
Anthropic CEO Dario Amodei今年1月提到:
现在的强化学习训练还在「新手村」,花100万美元就能比花10万美元强很多。大家都在拼命砸钱扩大训练规模,把这个阶段的投入提到数亿、数十亿,我们正处在一个关键转折点,新范式刚起步,所以增长特别快。

无法确定10万美元或100万美元是否反映了他对特定模型(如o1、o3或DeepSeek-R1)的训练成本的估计。
但能看出他觉得,目前推理模型的训练成本,还没到烧钱烧到飞起的程度,远低于数亿美元,即1×10²⁶次浮点运算。
总体而言,这些估计表明,o1和o3的推理算力规模和「算力天花板」的差距可能不会达到多个数量级,毕竟已经有模型(如DeepSeek-R1和Llama-Nemotron Ultra)在推理阶段用到1×10²³次浮点运算以上,o1、o3用的计算资源可能更多。
推理模型目前的算力水平,对AI短期发展有重要影响。
o3靠10倍算力碾压o1,数学、编程、写代码全面升级,至少在这些领域,训练算力和模型能力挂钩,砸越多算力,效果越明显。
这些模型可以对问题进行更多计算,从而提高其性能,但缺点是它们完成任务所需的时间比传统模型更长。
虽然目前还没有像预训练规模定律那样关于推理训练规模定律的严谨研究,但OpenAI展示的规模曲线与经典的对数线性规模定律颇为相似。
DeepSeek-R1论文中的图表也显示,随着推理训练步数的增加,准确率大致呈对数线性增长。
这表明,至少在数学和编程任务上,推理模型的性能与推理训练之间的关系,和预训练类似,存在一定的规模效应。
因此,在接下来的几次规模扩展中,可能会看到模型性能出现显著且快速的提升。
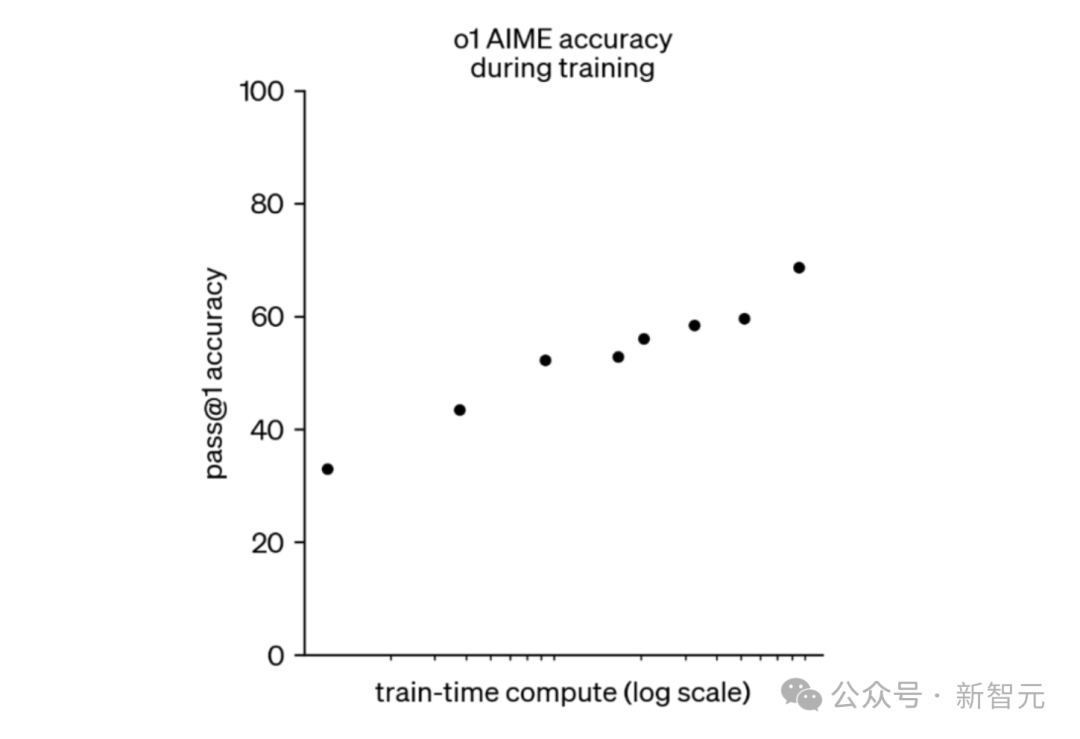
o1在AIME测试中的表现与训练计算资源的关系
但推理算力一旦摸到天花板,增长速度可能就会从「几个月翻10倍」掉到「每年翻4倍」。
如果推理训练和整体前沿算力差距只有几个数量级(如小于三个数量级),估计一年内增速就得放缓。
现实没那么简单。光堆显卡可不够,数据才是卡脖子的关键。
推理训练需要大量难题数据,但高质量的题目不是无限的,找题、编题、生成数据都不容易。
在数学、编程以外的复杂场景里,比如理解人类复杂情感,推理模型能不能同样好用,目前还是未知数。
开发推理模型,真正花钱的可能不是训练本身,而是大量的试错实验——测试不同的题目、打分规则、训练方法,这些成本目前没人公开。
虽然随着技术成熟,成本可能会降下来,但这些隐藏成本可能限制模型的扩展。
对AI行业来说,任何暗示推理模型在短期内可能会触及发展瓶颈的消息,都让人心里一紧。
毕竟,AI行业为了开发这类模型,砸进去了大量资源。
已有研究表明,运行推理模型的成本极高,相比某些传统模型,更容易出现幻觉。
不过也有好消息:即使算力增长放缓,模型说不定还能靠数据、算法创新接着变强。但无论如何,算力增长依然是关键,值得重点关注。
毕竟,OpenAI和行业大佬们都信心满满,o3大概率没触达极限,后面肯定还有惊喜!
(文:新智元)