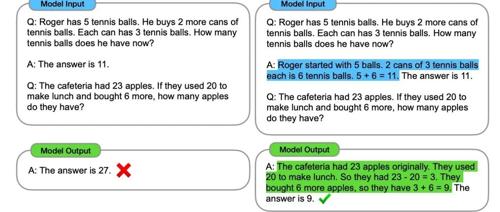
概率统计机制下,LLM 推理真的「理解世界了」吗?

本周会员通讯解读了2个AI & Robotics业内要事。首先讨论了概率统计机制下LLM推理的真实情况,涉及简单复读和显性路径在推理中的角色、Next Token Prediction的动态建模过程以及因果理解的表达。其次探讨了企业如何使用AI采购预算,并分析了从自行构建转向购买第三方应用的原因。通讯还包含2项专题解读及31个要事速递。
本周会员通讯解读了2个AI & Robotics业内要事。首先讨论了概率统计机制下LLM推理的真实情况,涉及简单复读和显性路径在推理中的角色、Next Token Prediction的动态建模过程以及因果理解的表达。其次探讨了企业如何使用AI采购预算,并分析了从自行构建转向购买第三方应用的原因。通讯还包含2项专题解读及31个要事速递。

沃顿商学院研究发现,奥特曼喜爱的直接回答提示词会显著降低模型准确率。同时,思维链(CoT)命令的效果也有限,并且可能导致答案不稳定增加计算成本。
DeepSeek 团队发布新版本 DeepSeek R1-0528,性能提升,支持长时间推理和复杂问题解决。模型基于 DeepSeek-V3-0324 模型,架构不变但进行了改进的训练方法和更透明的推理机制。

研究提出Soft Thinking方法,让模型在连续的概念空间中进行“软推理”,打破基于离散token的推理瓶颈。相比标准CoT,最高提升Pass@1平均准确率2.48%,减少token使用量22.4%。

谷歌DeepMind与LIT AI实验室的研究通过强化学习微调技术显著提升语言模型的决策能力,引发对未来AI新纪元的关注。该研究采用内在奖励机制和惩罚-塑造机制增强模型在真实世界中的应用效果,并探索人机共生、道德涌现等前沿议题。

最近的大语言模型在数学和编程等领域展示了强大的推理能力,通过强化学习使用思维链逐步分析问题。本文介绍了一种新的方法将这种策略应用于图片生成任务中,提出了两种不同的层次的思维链(CoT):Semantic-CoT负责设计图像的整体结构,而Token-CoT则专注于逐块生成细节。通过使用强化学习优化这两个层次的CoT,并引入多个视觉专家模型作为奖励模型来评估生成的图片质量,最终提出了一种新的文生图模型T2I-R1,显著提高了模型生成符合人类期望的结果的能力。

谷歌在I/O开发者大会上发布了新版Gemini 2.5 Pro Preview,该模型已在网页版、App端和开发者平台全面上线,并提供免费的25次每日使用额度。它被认为目前是地表最强且免费的多模态模型,尤其擅长编程任务。此外,新版还支持100万 tokens 上下文,具备强大的推理能力和前端UI优化能力。

OpenAI发布o3和o4-mini模型,具备连续调用超过600次工具的能力,超越人类工程师。主要特点包括全面工具访问与推理能力、图像推理能力的突破以及主动式工具使用。