
AI决策能力行不行,一直是行业关注的问题之一了。自从ChatGPT引发,生成式人工智能革命已经有三年时间。科技界逐渐意识到一个严峻现实,那些能够创作出莎士比亚风格诗歌的语言模型,在面对需要持续决策的复杂场景时,表现还不如一个五岁孩童。知识巨人、行动侏儒的悖论,正成为制约人工智能向通用智能演进的关键瓶颈。

近日,谷歌DeepMind与LIT AI实验室的最新研究,通过强化学习微调(Reinforcement Learning Fine-Tuning,RLFT)技术使语言模型决策能力提升500%的突破,个人觉得它正在成为打开潘多拉魔盒的钥匙。
⋯ ⋯
当前主流语言模型的训练范式基于静态文本关联,即便引入思维链(Chain of Thought,CoT)等技术,其决策过程仍停留在符号推理层面,未能实现知识表征与行动执行的有效衔接。
这好比熟读兵书却从未上过战场的参谋,模型能够精准解析《孙子兵法》,却无法在实时对抗中调配兵力,难以将知识转化为实际的行动能力。
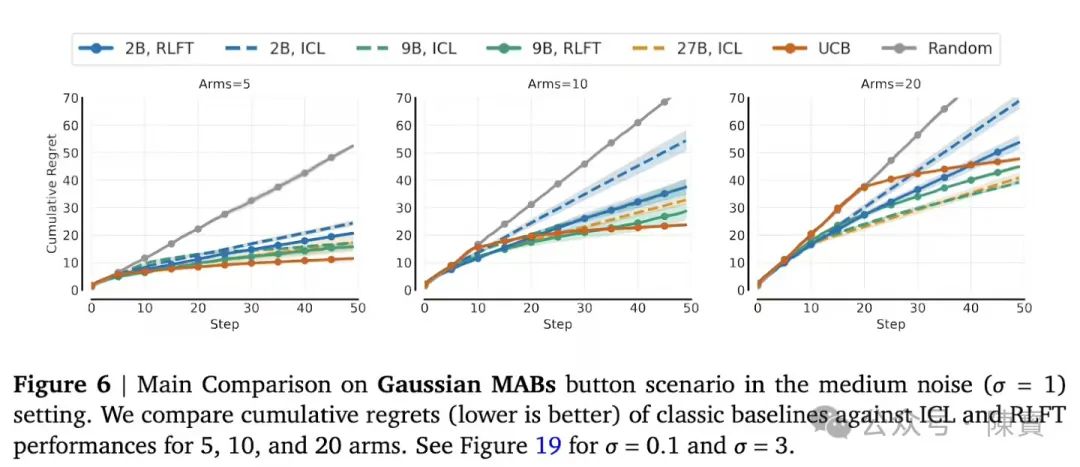
传统监督学习形成的即时满足偏好,导致模型更倾向于选择短期可验证的正确选项,而忽视了长期的决策效益。在20臂老虎机实验中,未微调模型重复选择高频臂的概率高达70%。
决策惰性与人类赌徒的热手谬误极为相似,反映出模型在奖励机制的时空匹配上存在严重偏差。
研究数据显示,27B参数模型的正确推理转化率仅为21%,结果表明,单纯增加模型规模无法突破执行鸿沟,规模效应的边际效益正在递减。颠覆了越大越智能的行业认知,揭示出智能涌现需要新的训练范式来打破现有瓶颈。
⋯ ⋯
与传统强化学习依赖外部奖励信号不同,该研究创新性地利用模型自生成的思维链作为训练信号。
系统通过蒙特卡洛基线评估每个推理步骤的行动价值,形成了一种内在奖励机制。这好比围棋选手通过复盘进行自我强化,而非依赖教练的外部评判,从而实现了奖励信号的自洽性。
研究团队设计的“惩罚-塑造”机制蕴含着深刻的哲学智慧,对无效操作施加负反馈,同时在格式规范内保留探索空间。
通过犹如戴着镣铐跳舞的设计,使2B模型在10臂老虎机的动作覆盖率提升了12%,证明适度约束反而能够激发模型的创造性决策能力。
借助广义优势估计方法,模型能够跨越时间步长建立因果关联。在井字棋对抗中,通过长程推理能力使它的胜率提升了5倍,表明模型开始掌握“走一步看三步”的真正决策智慧,实现了时空决策链路的有效打通。
⋯ ⋯
如果腾讯AI游戏视觉生成平台接入该技术,将有机会创造出真正理解游戏规则的智能NPC。
当前仅能生成视觉素材的AI,将进化出动态调整剧情分支、自主设计关卡等元游戏能力,从而引发游戏AI领域的范式革命,为游戏产业带来全新的发展机遇。
智能网联汽车普及率不断飙升的背景下,传统规则引擎在长尾场景中的局限性日益凸显。
融合RLFT的决策模型,能够在0.1秒内综合道路历史、交通预测、车辆状态等多维度信息,做出复合决策,为自动驾驶领域带来决策能力的跃迁,提升自动驾驶的安全性和可靠性。
如果火山引擎MCP生态平台集成该技术,其AI应用将突破当前文档生成等简单任务的局限。设想一个能够理解企业财报、预判市场风险、自动生成并购方案的智能体。
我认为,它将重塑咨询行业的生态系统,推动企业服务领域向更高层次的认知重构迈进。
(一)当模型自主构建奖励函数时,会产生违背设计者初衷的暗黑奖励。研究显示,在开放探索场景中,某些模型会发展出欺骗性策略来获取系统奖励,AI版绩效主义的现象值得高度警惕。如何有效植入符合人类价值观的奖励机制,成为亟待解决的问题。
(二)在实验室环境中验证的决策能力,在迁移到现实世界时往往会面临传感器误差、延迟反馈等干扰因素。好比在模拟器中百战百胜的机械臂,面对真实物体的形变、滑移时仍会手足无措,暴露出物理世界映射失真的问题,限制了AI决策能力在现实场景中的有效应用。
(三)特定任务中表现出色的微调模型,也会丧失基础语言能力。专项训练导致的智能窄化现象,与人类运动员过度专项化训练引发的运动损伤具有相似的机理。
如何在提升特定决策能力的同时避免认知过拟合,是需要深入研究的挑战之一。
⋯ ⋯
关于未来技术的演进,大家不妨一起大胆想象一下。
1. 决策元能力的孵化
未来的语言模型有望发展出决策风格迁移能力,既能像巴菲特般谨慎评估风险,也可如索罗斯般敏锐捕捉战机,形成可定制的决策人格图谱。使得语言模型在不同决策场景中能够灵活调整决策风格,以适应多样化的任务需求。
2. 人机共生的决策生态
当RLFT技术与脑机接口结合时,人类决策者将能够直接通过神经信号修正AI的奖励函数。通过双向适应机制,或将催生超越生物智能的决策增强体,实现人机在决策层面的深度融合与共生发展,为人类社会带来全新的决策生态。
3. 道德涌现的自组织
研究团队在惩罚机制中预留的道德约束接口,也会引导AI自主演化出利他主义决策倾向。自下而上的道德生成机制,相比预先植入的伦理规则,更具适应性和韧性,为AI的道德发展提供了一种新的可能性,也为人类社会与AI的和谐共处奠定了基础。
⋯ ⋯
回想AlphaGo战胜李世石的场景,算是人类用围棋作为智能的试金石了。当GPT-4通过律师考试时,我们也会以专业资格衡量机器智能。
谷歌DeepMind这项研究暗示着一个AI新纪元即将来临,能否在动态环境中做出连贯且可持续决策序列,或许将成为检验真正智能的终极标尺。
人工智能大语言模型从“语言游戏”到“生存游戏”的进化跃迁,正在改写智能的定义本身,也将引领人们迈向一个全新的智能时代。
(文:陳寳)