
谷歌DeepMind强化学习微调技术,重构了大语言模型决策范式

谷歌DeepMind与LIT AI实验室的研究通过强化学习微调技术显著提升语言模型的决策能力,引发对未来AI新纪元的关注。该研究采用内在奖励机制和惩罚-塑造机制增强模型在真实世界中的应用效果,并探索人机共生、道德涌现等前沿议题。
谷歌DeepMind与LIT AI实验室的研究通过强化学习微调技术显著提升语言模型的决策能力,引发对未来AI新纪元的关注。该研究采用内在奖励机制和惩罚-塑造机制增强模型在真实世界中的应用效果,并探索人机共生、道德涌现等前沿议题。

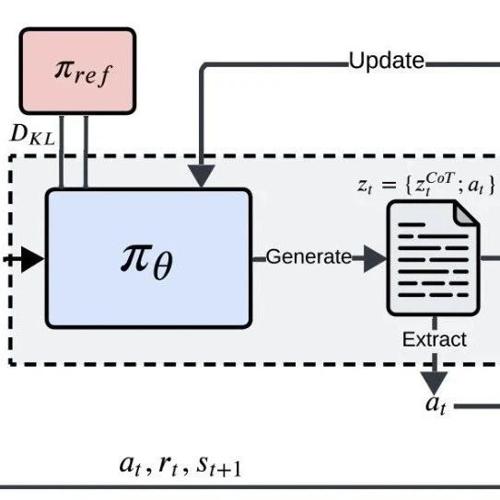
AI决策能力不足成为行业关注的问题。谷歌DeepMind与LIT AI实验室的研究通过强化学习微调技术提升了语言模型500%的决策能力。该方法利用思维链作为训练信号,并设计了惩罚-塑造机制,使模型能够在动态环境中做出可持续决策。研究显示单一增加模型规模无法突破执行鸿沟。
MLNLP社区是国内外知名的机器学习与自然语言处理社区,旨在促进学术界、产业界和爱好者的交流与进步。最新论文揭示了大模型决策中的三大缺陷,并通过强化学习微调结合思维链技术提升其决策能力。
