新版 Kimi 突然发布!首个万亿开源模型不是 R2 是 K2,OpenAI 临时推迟开源 附实测体验

不到半年,国产开源大模型经历了显著变化。DeepSeek凭借高性能和性价比迅速崛起并主导了这一领域。目前,Kimi 推出的 K2 模型在多任务中表现出色,并通过官方部署支持主流推理引擎。
不到半年,国产开源大模型经历了显著变化。DeepSeek凭借高性能和性价比迅速崛起并主导了这一领域。目前,Kimi 推出的 K2 模型在多任务中表现出色,并通过官方部署支持主流推理引擎。

国内大模型独角兽月之暗面发布并开源了其最新一代MoE架构基础模型Kimi K2,总参数量达到1万亿(1T),并在SWE Bench Verified、Tau2和AceBench三项基准测试中取得SOTA成绩。

专注AIGC领域的专业社区分享了DeepSeek R1增强版Chimera的进展及其优越性能。该版本相较于R1-0528版本推理效率提升200%,同时在MTBench、AIME-2024等测试基准中表现出色。
DeepSeek 团队发布新版本 DeepSeek R1-0528,性能提升,支持长时间推理和复杂问题解决。模型基于 DeepSeek-V3-0324 模型,架构不变但进行了改进的训练方法和更透明的推理机制。
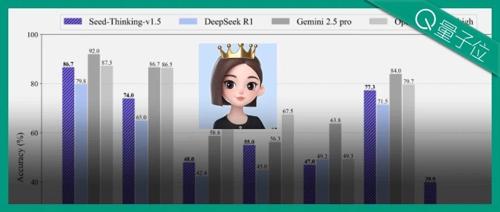
字节最新研发的Seed-Thinking-v1.5模型在数学、代码推理任务中表现优异,参数规模较小。该模型通过创新的数据处理方法、强化学习算法及基础设施优化提升了性能,并与其他领先模型进行了对比分析。
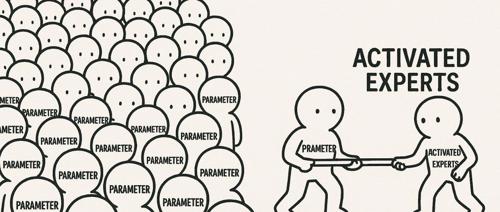
文章介绍了Gemma-3和DeepSeek V3在参数量上的对比,并指出模型效果不仅仅取决于参数大小。通过详细解释Dense和MoE架构的区别及其实际应用效果,强调了参数数量并不能直接反映模型性能优劣的观点。同时讨论了知识蒸馏技术如何让小模型继承大模型的能力,而不仅仅是关注模型的规模大小。