
作者 | 王闻宇,PPIO 派欧云联合创始人兼 CTO
责编 | 梦依丹
545% 的成本利润率,是 DeepSeek 抛出的诱人数字,还是触手可及的未来?这场由开源所引发的 AI 技术平民化浪潮,又将如何重塑 AI Infra 的格局?
3 月 5 日,PPIO 派欧云联合创始人兼 CTO 王闻宇做客「CSDN AI 进化论」,深度剖析 DeepSeek 开源周背后的技术逻辑与生态影响,揭示了这场技术盛宴中蕴藏的机遇与挑战。王闻宇认为:
-
DeepSeek 声称的 545% 成本利润率虽难以完全复现,但揭示了 AI Infra 盈利能力的巨大潜力,指引我们不断逼近这个目标;
-
DeepSeek 类似于 AI 领域的瓦特,通过降低技术门槛和开源策略,预示着 AI 应用的平民化和算力需求的爆发式增长;
-
DeepSeek 在现有硬件限制下,充分发挥软件和集群能力,是典型的“硬件定义软件”案例,也为未来软硬件结合发展提供了新思路;
-
虽然未来大小参数模型将并存,但 DeepSeek 开源的 MoE 架构在超大参数模型部署上具有天然优势,可能会引领超大模型发展方向;
-
DeepSeek 带火一体机,其背后逻辑在于简化交付、避免硬件异构性问题,提升商业模式效率,也反映了 AI 服务交付模式的转变。
以下是对王闻宇直播内容的部分提炼:
“大模型开源与传统开源不同,大模型主要开源模型、权重和技术细节。“
DeepSeek 通过开源模型、降价以及声称的高利润率备受瞩目。而这些的背后都离不开其技术创新,DeepSeek 提前公开的 P&D 分离技术是例证,通过将推理的 Prefill 与 Decode 两个阶段分别部署在不同的硬件上,从而能实现最大化的利用资源。
在 2024 年 12 发布的技术报告中,DeepSeek 官方提到 Prefill 需要 4 个节点(32 张 H800),Decode 需要 40 个节点(320 张 H800):


但是 DeepSeek 在开源周 Day6 的知乎文章做了一些优化,推荐了 4+18 的方案,把综合性能调到最优:


在理解 P&D 分离之前,首先要理解 QKV 和 KV Cache。所有大模型的根基都是基于 Attention(注意力机制),这个算子的核心要素是请求(Query)、键(Key)和值(Value),即 QKV。
Profill 就是一个生成 KV Cache 的过程。通常,第一个 Token 甚至靠前的 Token,会使用 Profill 的生成过程来输出;之后产生的 Token 都使用 Decode 的方式,即通过 KV Cache 和 Input 来生成后续的文本。
DeepSeek 模型在部署时候的最大特点是,多台机器集群化部署,并非实施 P&D 分离:

注:图片来自开源项目 mooncake
DeepSeek 的 P&D 分离有着其独特之处。首先,每台机器会使用多张卡,它们通过 NVLink 高速互联。机器之间还会使用 RDMA 这类高速网络,在每张卡之间、每台机器之间形成高速内网,进行密集、大吞吐量的信息交换,从而形成集群化的推理。与以往不同之处在于,DeepSeek 推理不再是单机推理,而是动用集群的力量,通过高速网络与卡进行分工,部分卡参与 Profile,部分卡参与 Decode,最终形成动态推理。
在 DeepSeek 开源周的各个项目中,都展现了这种基于负载的分布式策略和并行计算思路。除了之前公布的 P&D 分离,我先来讲讲第二天的 DeepEP 、第四天的 EPLB 以及 DualPipe。

开源周 Day2:DeepEP
为了解释 EP(Expert Parallelism,专家并行),得首先说说 MoE。
在大型模型领域,存在两个主要流派:一种是 MoE(Mixture of Experts,即多专家混合模型);另一种是 Dense(即稠密模型)。各大厂商在模型发展路线上各有侧重。例如,Dense 模型的代表包括 Facebook 的 Llama 和阿里的千问早期 等,它们基本上走的是 Dense 路线。而 MoE 模型的代表则有 Mixtra、 Grok。DeepSeek 从 V2,一直坚定选择了 MoE 路线。
再说说 EP,这是一种 MoE 模型在训练和推理中的并行化技术。它的核心思想是将模型中的“专家”(Experts)分布到不同的设备(如 GPU)上,通过并行计算来加速模型的训练和推理过程。

上图形象地展示了 EP 的几代演进。第一代 EP 架构以 Mixtral 为代表。在开源模型中,Mixtral 是首个公开的 MoE 模型。简单来说,第一代 MoE 使用较少的专家数量和简单的负载均衡策略。这是 Mixtral 当时的架构,包含八个专家,每次推理激活其中两个。
随着技术发展,人们发现可以增加专家数量,从而提升模型性能。因此,后续的 MoE 模型增加了专家数量,并采用了更复杂的路由机制(选择专家的策略)。更复杂的路由机制使得模型能够容纳更多参数,并取得更好的效果。DeepSeek V2 就代表了 MoE 架构的第二代演进。
到了 DeepSeek V3,将专家分为两种类型:共享专家和路由专家。共享专家不经过路由选择,直接参与计算。这意味着,所有推理请求都必然会经过共享专家(我的理解是,DeepSeek 结合了 Dense 模型的优势,这个共享专家和 Dense 模型的理念很像)。而剩余的路由专家则会根据输入数据的实际内容,通过路由机制选择并激活。路由机制会根据权重匹配,选择 K 个专家(K=1 到 3),即选择 1 到 3 个专家参与推理,并根据权重进行加权。最后,将共享专家和路由专家的输出进行合并,得到最终的推理结果。这就是 DeepSeek V3 的 EP 过程。
DeekSeek V3/R1 的 MoE 架构,采用了 1 个共享专家,256 个路由专家,它的 EP 架构在每次部署的时候,每张卡确保有一个共享专家,和多个不同的路由专家。

开源周 Day4:EPLB & DualPipe
为了解决专家并行中专家与 GPU 之间的负载均衡问题,Day4 发布了 EPLB (Expert Parallelism Load Balance)。既然 DeepSeek 采用了 EP 专家并行的方式,为了实现整体各个 GPU 的计算负载均衡,它推荐在多张 GPU 上分别部署不同的专家。具体而言,对于负载高的专家,会部署在多张卡上;而负载低的专家,则部署在一张卡上。

针对 DeepSeek V3 模型中的大量专家,EPLB 的目标是合理分配专家到各个 GPU,使整体工作负载更均衡。EPLB 通过分析专家使用频率,结合部署环境信息,生成专家分配矩阵,确保每张 GPU 卡的计算资源得到充分利用。
除此之前,Day4 还发布了 DualPipe 技术以配合 EPLB。其核心思想很简单,就是在训练过程中,尽量减少多个 GPU 出现空闲等待的时间,即减少 “bubble”(气泡)时间。

注:如图,图片中的空白部分就是“气泡”,表示 GPU 的计算单元这时候限制,空白部分越少,GPU 的利用率越高
DualPipe 的核心目标是提高 GPU 利用率。其借鉴了之前两种主流的流水线并行思路。一种是 1F1B(One Forward, One Backward),即一次前向传播,一次后向传播,将训练过程划分为前向和后向两个阶段。
后来,又发展出一种名为 Zero Bubble 的单向流水线技术,它在 1F1B 的基础上,进一步细化了粒度,将后向传播过程又细分为计算梯度和更新权重两个阶段。因此,Zero Bubble 将训练过程划分为前向传播、计算梯度和更新权重三个阶段。
DeepSeek 的 DualPipe 技术则更进一步,将训练过程划分为四个阶段:前向传播(Forward)、后向传播(Backward)、仅输入的后向传播(Backward Input Only)和权重更新(Weight Update)。

开源周 Day5:Fire-Flyer File System(3FS 文件系统)
3FS 是一种高性能分布式文件系统,其目的是应对训练和推理工作负载的挑战。它利用 SSD 和 RDMA 网络,以提供一个共享存储层,从而简化分布式应用程序的开发。DeepSeek 还同时发布了基于 3FS 的框架 Smallpond。

3FS 可以在集群化的分布式架构,实现高性能的数据存储和访问,具备强制一致性,而且兼容常见文件接口的特点。DeepSeek 在开源部署中,集群化部署是其核心重点。而支撑起这种集群化部署核心的关键,正是 P&D 分离、EP 以及 EPLB 这三者的组合。
大规模集群训练和推理天然会带来大量的跨卡、跨机缓存和存储访问需求。为了应对这些挑战并实现极简化的部署方案,3FS + Smallpond 不仅支撑了 DeepSeek 的极简部署,更被广泛应用于数据预处理、加载、检查点保存、向量搜索和推理优化等多个关键场景。
DeepSeek 开源周,说明了 DeepSeek 充分利用 MoE 模型推理的时候只激活部分参数的特性,把 671B 大参数模型的推理,相当于变成了“小参数模型部署 + 负责均衡”来实现。

开源周 Day1: FlashMLA
我首先说说 MLA(Multi-Head Latent Attention,即多头潜在注意力机制),要理解 MLA,首先和之前的 MHA(Multi-Head Attention)对比。传统的 MHA 因而需要大量的显存空间去存储 KV Cache,而 MLA 通过信息注入的方式,将 KV 不同头上的公共信息压缩到 Q 上,将非共享信息转化为只有一个头的 C,再通过旋转位置编码的方法在实际计算的时候,只要很小的计算量,就可以还原出 KVCache,从而实现与 MHA 相同的效果。
MLA 对比之前的 MHA,其本质是用时间换空间的方式,牺牲一点计算时间,但是可以把 KV Cache 做较大的压缩,节约出大量的显存空间来做其他用途。

其实从 MHA 到 MLA 并非一蹴而就,而是经历了多次迭代演进。

以最初的 MHA 为例,其采用 Cache Inference 机制,所有相关部分都需要缓存。随后,出现了分组优化技术,通过对 Query 进行分组并合并 Query Cache,减小了缓存体积。之后,MQA 在分组的基础上进一步对内容进行合并,形成了更紧凑的结构。然而,这两种方法在 KV Cache 方面仍存在一定的效率损失。
Latent Query 是一种更为精巧的方案,采用了 Latent Query 转换机制。简而言之,该机制通过数学方法将 KV 序列转换为一个紧凑的表示 C,显著降低了存储空间。而 C 又可以通过相对简单的计算实时还原中间过程,这就是潜在机制的核心思想。

开源周 Day3: DeepGEMM

DeepGEMM 是专为 FP8 混合精度打造的通用矩阵乘法(A*B=C)加速引擎。它采用 CUDA 框架内的汇编语言 PTX 编写,核心代码仅几百行,却能支持 Hopper 架构和八位精度浮点,并可及时编译,灵活调整 Block Size 以充分利用 GPU 的计算单元(SM),从而提升计算效率,注意的是,DeepGEMM 不仅仅适用于 DeepSeek 的 MoE 模型,传统 Llama 的 Dense 模型也可以使用。
DeepSeek 模型成本率达到 545% 背后的真正秘密是什么?我认为关键不仅在于其开源的各种技术库,更在于其背后的思维理念:极致发挥硬件性能。DeepSeek 的底层逻辑是充分结合模型特点,力求在存储、带宽和计算等各个环节都充分利用硬件资源,实现极致优化。
例如,DeepSeek 采用双倍气泡通信方案,将计算和通信紧密交错,最大限度地减少资源闲置。
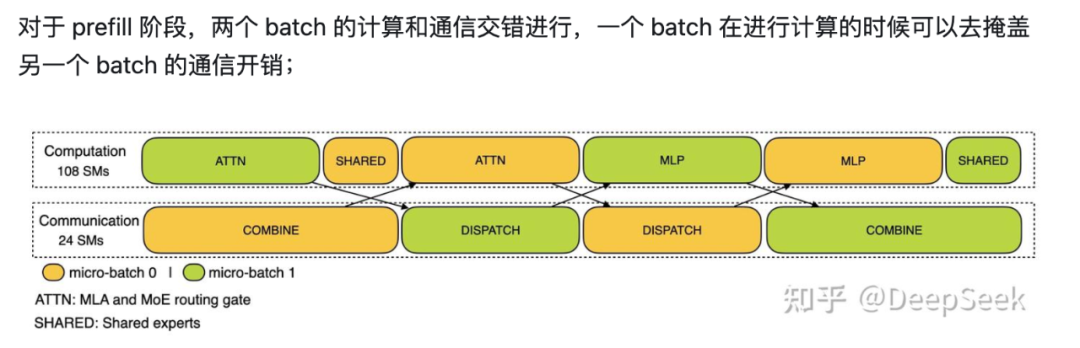
这种理念贯穿 DeepSeek 的整体架构,正是对硬件性能的极致挖掘和优化,成就了 DeepSeek 技术的卓越表现。
以下是部分对话实录:
CSDN:DeepSeek 的 545% 成本利润率,自己部署能复现吗?
王闻宇:关于 DeepSeek 545% 成本利润率,首先我认为这更多是一个理论值,实际应用参考意义有限。DeepSeek 在报告中展示的资源占用图显示资源几乎 24 小时满负荷运行,这意味着高峰期可能存在用户请求排队或响应慢的问题,影响用户体验。要确保良好的用户体验,算力需要留有冗余,实际利润率可能无法达到 545%。但这个数字揭示了 AI Infra 盈利能力的巨大潜力,指引我们通过技术复现不断逼近这个目标。

要复现 DeepSeek 的技术,需要满足以下三个条件:
1. 稳定的集群:基于 H800 甚至 H100 等更高级的 GPU 集群。
2. 足够大的用户量:充分利用集群资源,避免卡闲置。
3. 极致的优化:强大的并行计算技术能力。
即使满足以上条件,实际商业场景仍面临诸多限制,如稳定的集群不易搭建,用户量难以保证,Infra 技术实现复杂。此外,实际在商业的服务中常见的性能指标约束(如 TTFT、TPOT、TPS、RPS 等),从而导致更多 GPU 的冗余,也会限制复现的可能性。
CSDN:DeepSeek 之后,算力竞赛结束了吗?
王闻宇:我对此持乐观态度,认为 DeepSeek 并非算力竞赛的终结者,反而可能推动算力需求的进一步爆发。
回顾历史,瓦特改良蒸汽机提高了热效率,虽然初期导致煤炭价格下跌,但由于蒸汽机成本降低,应用场景更加广泛,最终推动了第一次工业革命。DeepSeek 类似于瓦特(注意历史真相:瓦特只是改良蒸汽机,不是发明蒸汽机),它改良了 AI 推理,大幅降低了成本。短期内可能导致 GPU 算力空闲,但长期来看,一定会催生大量 AI 应用,带来更大规模的算力需求。DeepSeek 的开源降低了 AI 技术门槛,提出了一种特殊的推理部署方法,最终大大降低推理成本,并加速 AI 平民化。长期看,必然带动算力需求的爆发式增长。
CSDN:DeepSeek 的 MoE 架构路线会引领未来吗?Dense 模型还有戏吗?
王闻宇:开源周后,我对大参数 Dense 模型的前景感到不太乐观。DeepSeek 虽然部署了 671B 的超大参数模型,但实际上是通过并行方式,每次激活约 37B 的参数,相当于用部署中型参数模型的机制和成本实现了超大模型的部署。MoE 在超大参数模型部署上具有天然优势,因为它可以并行激活小参数,降低部署成本。
但是,AI 发展至今,并非所有场景都需要超大参数模型。未来,大、中、小参数模型都将并存,并应用于不同场景。在不需要超大参数的场景下,Dense 模型仍有发挥空间。
中等和小参数模型可能会延续过去的单机部署,甚至微型参数模型可以做到端侧推理。因此,我认为未来的场景是多样的,超大参数模型可能会走向 MoE,但 Dense 模型仍有存在的价值。
CSDN:英伟达亲自下场优化 R1,降本 20 倍,意味着什么?
王闻宇:我们也在尝试复现英伟达的方案,因为单机部署比集群部署容易。虽然还没有完全达到他们给出的数值,但理论上是完全可行的。
首先,英伟达使用了 B200 这种最强的 Blackwell 新一代架构 GPU,并采用了 FP4 技术,将 FP8(8bit 的浮点数)量化到 FP4(4bit 的浮点数)。B200 在参数上比 H800 甚至 H200 都要强大很多:更大的显存(192G)、更强的浮点性能(FP4 18P vs H200 3.9P),NVLink5.0 带宽翻倍(从之前 900G 提高到 1800G),并提供支持 FP4 精度的 Tensor Core 2.0。
我认为英伟达在底层硬件和上层软件都已经努力了,很可能确实达到他们所说的 25 倍加速和 20 倍降本。但英伟达的优化原理与 DeepSeek 不同。DeepSeek 做的是 AI Infra 层的优化,本质上是软件公司做的事情。而英伟达是硬件公司,在更底层的硬件层面。长期看,这两层的优化都很重要,并不矛盾,最终人类一定享受这 2 层优化的结果。
未来的趋势是这两层技术都会持续进步和迭代,最终一定是英伟达甚至国产卡,在硬件层加速迭代,再结合 AI 异构计算的加速迭代。降本之后还会再持续降本。伴随推理成本的降低,以及底层硬件和软件的迭代,一定会加速整个行业的发展,让更多人更长时间地享受 AI 带来的全面福利。
CSDN:DeepSeek 开源周会催生怎样的 AI 新生态?海外开发者怎么看?
王闻宇:海外开发者对 DeepSeek 感到震惊,因其以十分之一的成本,且基本媲美 OpenAI 的效果,受到广泛关注和积极部署。
DeepSeek 出现后,海外大厂也意识到大模型的门槛不高,开始发布自己的模型。我认为 AI 发展会加速,并带来以下几点:
1. 开源受到更多关注:未来会有更多国内外模型公司考虑开源模型。
2. 对 Infra 的关注度提高:之前其他公司虽然也在做推理优化,但更多没有站在集群角度,充分发挥集群综合能力。未来会逐步走向这种思路,推理引擎会开源更多推理 Infra 服务。DeepSeek 开源对整个 AI 生态,包括模型、AI Infra 和应用都非常有帮助,加速了行业的发展。海外开发者也更关注中国的产品,加速了行业的发展。

(文:AI科技大本营)