
-
• Qwen3 是通义千问最新发布的系列开源大模型 (Apache 2.0),包含多款 MoE 和密集模型,覆盖从 0.6B 到 235B 参数。 -
• 核心亮点在于 MoE 架构带来的高效率(如 30B-A3B 以 3B 激活参数实现卓越性能,显著降低推理成本),以及创新的 混合思考模式(用户可控的推理深度与响应速度)。同时具备 119 种语言支持和强化的 Agent 能力。 -
• 基于 36 万亿 Tokens 的海量、高质量多源数据,采用优化的 三阶段预训练 和 四阶段后训练 流程构建。发布即提供对主流框架和社区的广泛 Day 1 支持。 -
• Qwen3 的发布显著降低了高性能 AI 的部署和使用门槛,推动 AI 向更高效费比、更可控、更面向任务执行(Agent 化)的方向发展,对本地部署、边缘计算及复杂工作流自动化具有重要价值。
AI 演进新篇章,Qwen3 的关键信号
人工智能大模型的演进正以前所未有的速度进行,新模型的发布不断刷新着性能基准,也带来了新的技术范式思考。在这样的背景下,通义千问团队发布的 Qwen3 系列模型引发了业界的广泛关注。Qwen3 的意义不仅在于其参数规模或基准测试成绩,更在于它在模型效率、智能交互形态和生态开放性上发出的强烈信号。其采用的 MoE (Mixture of Experts) 架构和独特的 混合思考模式 (Hybrid Thinking Modes),预示着大模型发展可能的新方向,旨在实现“思深致远”的智能深度与“行速争先”的响应效率之间的更优平衡。
核心模型矩阵与开放策略:赋能全球创新生态
Qwen3 系列并非单一模型,而是一个包含多款模型、覆盖广泛应用需求的组合。本次发布包括了两款备受瞩目的 MoE 模型和六款不同规模的密集模型。
-
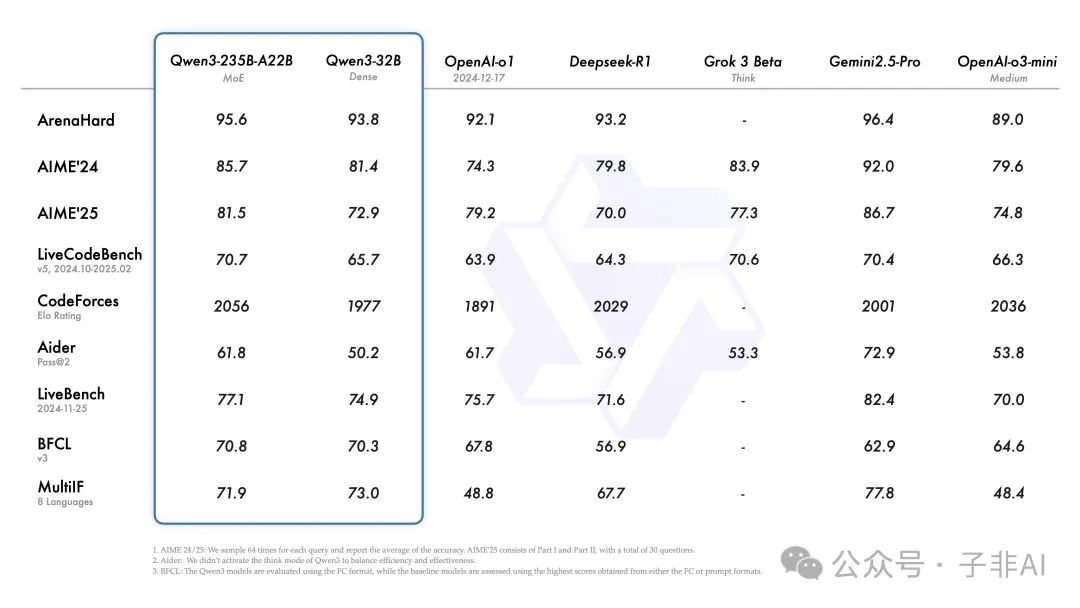
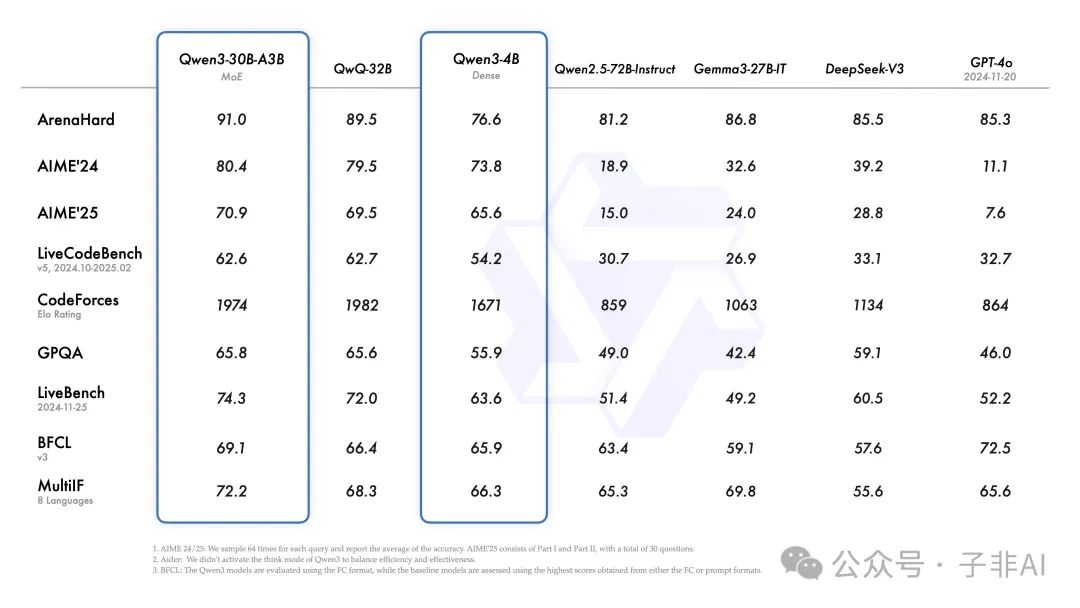
• 旗舰 MoE 模型 Qwen3-235B-A22B:拥有 2350 亿总参数,但推理时仅激活约 220 亿参数。其设计目标是在保持极高能力的同时,显著提升推理效率,面向需要顶尖性能的复杂任务场景。 -
• 高效率 MoE 模型 Qwen3-30B-A3B:总参数 300 亿,推理激活参数仅约 30 亿。这款模型因其出色的性能功耗比而备受关注,官方数据显示其性能超越了激活参数多 10 倍的 QwQ-32B,对资源敏感型应用极具吸引力。
-
• 密集模型系列 (0.6B 至 32B):包括 Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B 六款模型。这些模型为不同硬件能力和任务需求提供了丰富的选择。值得注意的是,即使是 Qwen3-4B 这样的小模型,其性能据称也足以媲美前代 Qwen2.5-72B-Instruct,显示出基础架构和训练技术的显著进步。
至关重要的是,Qwen3 全系列模型均遵循 Apache 2.0 许可证进行开源。这一开放策略极大地降低了全球开发者、研究机构和企业使用先进 AI 技术的门槛,鼓励基于 Qwen3 进行二次开发、研究和商业应用,为整个 AI 开源生态注入了新的活力。
目前,模型已在 Hugging Face, ModelScope, Kaggle 等平台上线。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Qwen3密集模型参数概览
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Qwen3 MoE模型参数概览
MoE 架构:驱动效率革命的核心引擎
MoE (Mixture of Experts) 架构是 Qwen3 实现高效率的关键。其核心在于模型内部包含多个“专家”子网络,并通过一个“门控”网络动态选择在处理特定输入时激活哪些专家。这意味着,虽然模型的总参数量(代表其潜在知识容量)可以非常大,但单次推理所需的实际计算量(由激活参数量决定)可以显著降低。
Qwen3 的 MoE 模型充分利用了这一优势。以 Qwen3-30B-A3B 为例,其拥有 128 个专家,但每次推理仅激活其中 8 个。这使得它能在仅需 30 亿激活参数计算量的情况下,展现出远超同等计算量密集模型的性能,甚至逼近参数规模大得多的模型。开发者社区的反馈也印证了这一点,指出其在相同硬件上的推理速度(tokens/秒)相比密集模型有数量级的提升。
MoE 带来的效率优势是多方面的:
-
• 更快的推理速度:在同等硬件上,激活参数更少意味着计算更快。 -
• 更低的硬件门槛:推理所需的显存/内存主要与激活参数相关,使得高性能模型能在更广泛的硬件(包括消费级 GPU、CPU)上运行成为可能。 -
• 更高的吞吐量:在云端部署时,可以在单位时间内处理更多请求,降低服务成本。
Qwen3 MoE 模型的成功实践,证明了通过精巧的架构设计,可以在不牺牲性能的前提下,大幅提升 AI 模型的能效比,这对于 AI 技术的广泛部署和普惠化具有重要意义。
混合思考模式:赋予 AI 可控的“深思”与“速行”
传统大模型在面对不同复杂度的任务时,往往难以灵活调整其“思考”深度。Qwen3 引入的 混合思考模式 (Hybrid Thinking Modes) 则试图解决这一问题,它将模型的推理过程本身设计为一种可控的行为模式。
Qwen3 支持两种核心模式:
-
1. 思考模式 (Thinking Mode):模型会进行内部的逐步推理(类似 Chain-of-Thought),生成中间步骤,适用于需要深度分析、逻辑推演的复杂任务。 -
2. 非思考模式 (Non-Thinking Mode):模型倾向于直接给出答案,减少内部推理开销,适用于简单查询或对响应速度要求高的场景。
这一模式的核心价值在于其 可控性 和 适应性。开发者和用户可以通过多种方式引导模型的行为:
-
• API 参数控制:通过设置 enable_thinking参数 (True/False) 来选择默认模式。 -
• 动态软切换:在多轮对话中,可以通过在输入中添加特殊指令(如 /think或/no_think)来临时改变模型当轮的思考模式。 -
• 思考预算管理:模型性能与分配给思考过程的计算资源(“思考预算”)正相关。如下图所示,增加思考预算可以带来性能的提升。这允许在任务需求(质量)和资源消耗(成本、延迟)之间进行精细权衡。
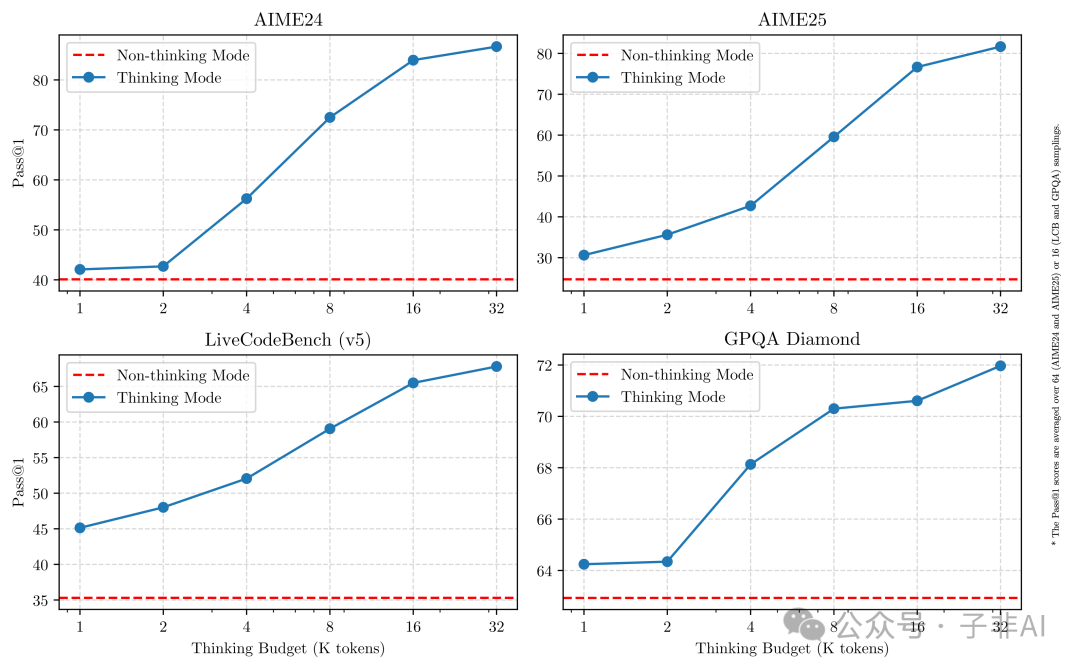
这种将“思考”过程显性化、可量化、可控制的设计,使得 AI 模型不再是一个黑箱,而是可以根据具体场景进行智能调优的工具。它提升了用户体验(该快则快,该慢则慢),也提高了资源利用效率,是 AI 交互设计理念上的一次重要探索。
坚实基础:海量数据、精细训练与性能验证
卓越性能的背后是扎实的基础工作。Qwen3 在数据和训练方法上都进行了显著投入。
-
• 数据规模与质量:预训练数据集达到了 36 万亿 Tokens,是前代的两倍。数据来源广泛,除了网页数据,还利用 多模态模型 (Qwen2.5-VL) 从 PDF 等文档中提取高质量文本,并使用 语言模型 (Qwen2.5) 进行清洗和优化。同时,通过 模型生成合成数据(使用 Qwen2.5-Math, Qwen2.5-Coder)的方式,补充了在数学、代码等领域的高质量训练语料。 -
• 三阶段预训练策略: -
1. 基础构建 (S1):>30T Tokens, 4K 上下文,建立通用语言能力和知识。 -
2. 能力增强 (S2):+5T Tokens,增加 STEM、代码、推理等知识密集型数据比例。 -
3. 长上下文扩展 (S3):高质量长文本数据,将上下文窗口扩展至 32K/128K。 -
• 四阶段后训练流水线:为了实现混合思考模式和强大的 Agent 能力,设计了包括 长 CoT 冷启动、基于推理的强化学习 (RL)、思考模式融合、通用能力 RL 在内的精细后训练流程。
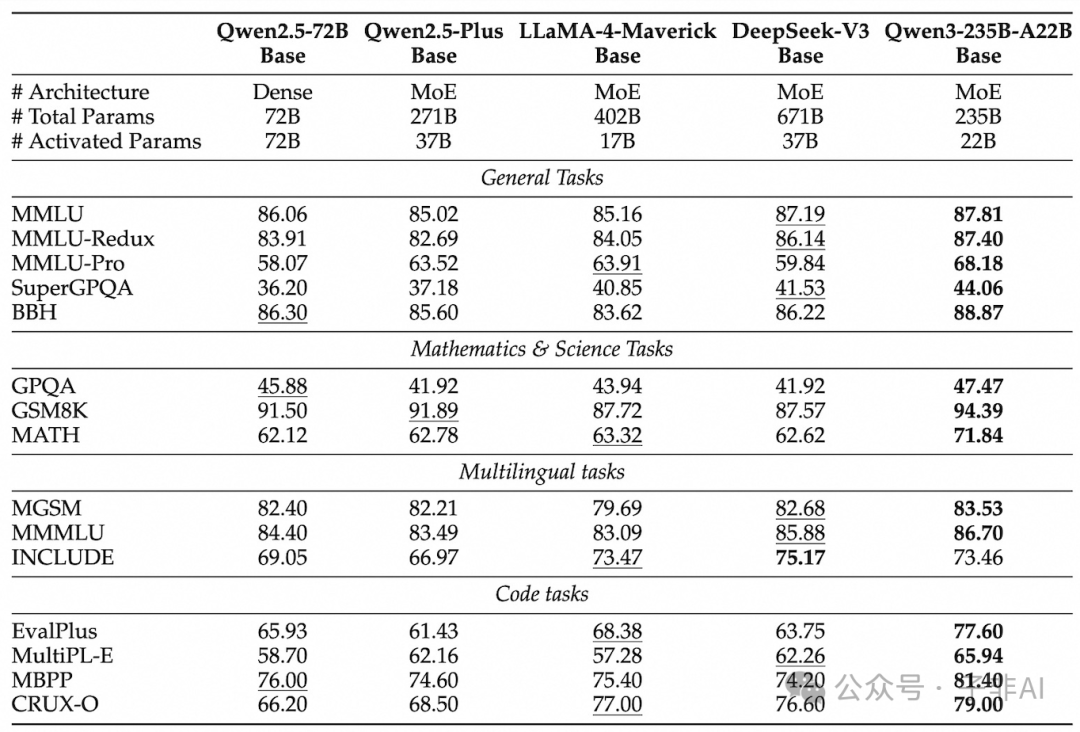
图5:Qwen3 基础模型在多个基准上展现出比前代更高的参数效率。
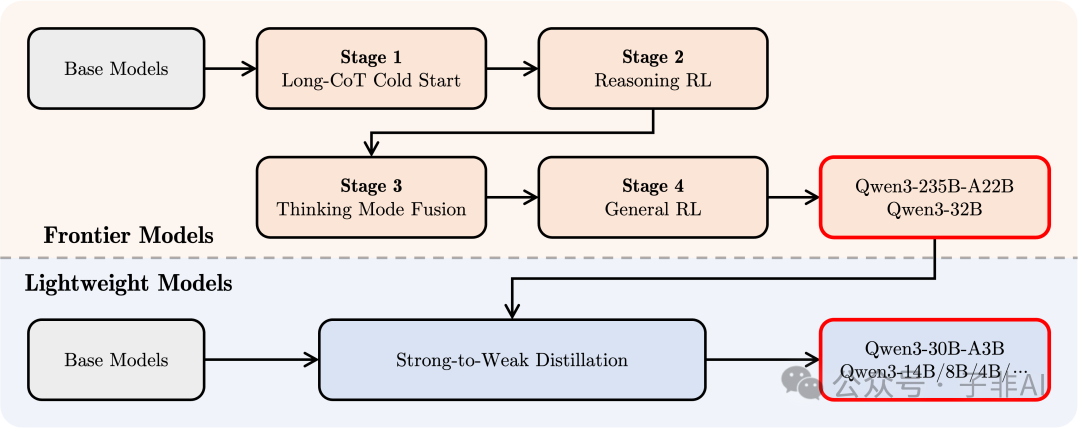
图6:构建混合思考能力的四阶段后训练流程示意。
这些投入带来了显著的成效。Qwen3 模型不仅在基准测试中表现优异,更重要的是展现了更高的参数效率。例如,Qwen3 的密集模型普遍达到了比前代更大参数模型相当甚至更好的性能。而 MoE 模型则以更低的计算成本实现了与顶尖模型的性能竞争。
Agent 潜力:迈向更自主的 AI
AI 的未来趋势之一是从被动的“语言模型”进化为能够主动执行任务、与环境交互的“智能体”(Agent)。Qwen3 在这方面展现了清晰的布局和强大的潜力。
-
• 广泛的多语言能力:支持 119 种语言和方言,为构建面向全球用户的 Agent 应用奠定了基础,使其能够理解和处理来自不同文化背景的指令和信息。 -
• 强化的 Agent 相关能力:模型在编码、工具使用(Tool Calling)和遵循复杂指令方面进行了优化。特别提到了对 MCP (可能指 Multi-agent Communication Protocol 或类似概念) 的支持,这暗示了模型在理解和参与更复杂、可能涉及多方协作或遵循特定交互规范的任务上的潜力。这不仅仅是简单的 API 调用,而是向着能够理解和执行包含上下文、依赖关系和条件的复杂工作流迈进。 -
• 官方 Agent 框架支持:推荐使用 Qwen-Agent 框架来简化 Agent 应用的开发。该框架封装了工具调用的模板和解析逻辑,降低了开发者构建能够利用外部工具(如搜索引擎、计算器、代码执行器等)完成任务的 Agent 的复杂度。
Qwen3 在 Agent 能力上的投入,反映了行业内的一个重要趋势:AI 需要超越文本生成,具备感知环境、做出规划、执行动作的能力。支持 MCP 和提供 Agent 框架,是为构建能够自主完成目标、适应环境变化的下一代 AI 系统铺设必要的基础设施。正如 Qwen 团队所述,行业正在从“训练模型”向“训练 Agent”过渡,Qwen3 正是这一转变的积极践行者。
生态融合与开发者友好性
技术再好,如果使用门槛过高,也难以发挥最大价值。Qwen3 在开发者生态建设方面的投入值得称道。
-
• 全面的 Day 1 支持:在模型发布首日,就确保了对主流推理框架(如 vLLM, SGLang, llama.cpp, Ollama 等)的兼容性。这是通过与框架开发者提前协作实现的,极大地便利了用户在各种环境中部署和使用 Qwen3。 -
• 社区量化合作:提前与社区中活跃的模型量化开发者合作,使得 Qwen3 的各种低比特量化版本(如 GGUF, AWQ, GPTQ 等)能够快速推出,满足了在资源受限设备(如个人电脑 GPU)上运行的需求。 -
• 清晰的文档与示例:提供了详尽的官方文档和使用示例,帮助开发者快速上手。
开发者社区对此反响积极,普遍认为 Qwen3 的发布流程考虑周全,对开发者非常友好。这种对生态的投入,加速了 Qwen3 的普及和应用落地。
关于本地运行,Qwen3 提供了多种选择。30B-A3B MoE 模型因其高效率成为本地部署的热门选项,理论上在拥有中高端消费级 GPU (如 16GB+ VRAM) 的设备上可以实现较流畅的运行。社区也开始分享在不同硬件上的实际性能数据和量化策略。而 0.6B/1.7B/4B 等更小尺寸的模型,则可以在更低配置的硬件上运行,或用于 投机解码 等加速技术中。
Qwen3——驱动 AI 效率与智能范式演进的新力量
Qwen3 的发布无疑推动了 AI 开源领域的发展,其在 MoE 效率、可控推理 和 Agent 能力 上的探索,代表了行业向更实用、更高效 AI 形态演进的重要方向。与其他所有大模型一样,使用者需关注其输出的可靠性,并在具体应用中进行评估。Qwen3 的加入将进一步激发技术创新和良性竞争,共同探索通往 AGI 的可能路径。

Qwen3 以其 MoE 架构带来的效率革命、混合思考模式赋予的可控智能、以及对 Agent 未来的清晰布局,为 AI 领域树立了新的标杆。结合其彻底的开源策略和开发者友好性,Qwen3 不仅是一个强大的技术工具,更是加速 AI 创新与普及的重要催化剂。它所代表的“思深行速”理念,正驱动着 AI 向更高效、更智能、更开放的未来加速前进。
推荐阅读
-
• 体验 Qwen3 在线聊天: Qwen Chat https://chat.qwen.ai/ -
• 探索 Qwen3 代码和模型: QwenLM GitHub https://github.com/QwenLM/Qwen3
(文:子非AI)