
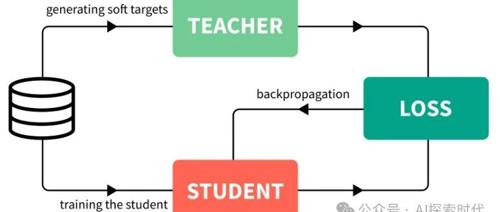
知识蒸馏
52页PPT,谷歌Gemini预训练负责人首次揭秘!扩展定律最优解

谷歌Gemini 2.5 Pro在模型训练和推理优化方面取得突破,Vlad Feinberg揭秘其核心技术。通过经典扩展定律、推理优化扩展定律以及知识蒸馏技术,谷歌找到了最优解,在资源有限的情况下实现了性能提升。
Transformer原作、斯坦福、清华交大三篇论文共识:基座模型边界锁死RL能力上限

MLNLP社区是国内外知名的人工智能社区,致力于促进学术交流。该领域内的三篇论文讨论了强化学习在大模型训练中的作用,并指出模型的推理能力大部分已在预训练阶段形成,RL更多起到优化选择路径的作用。
大模型靠强化学习就能无限变强?清华泼了一盆冷水
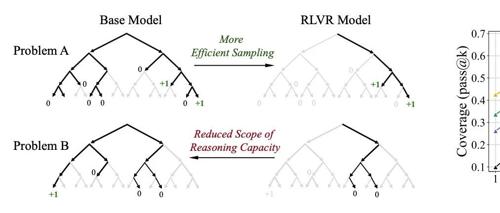
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。

大,就聪明吗?论模型的“尺寸虚胖”
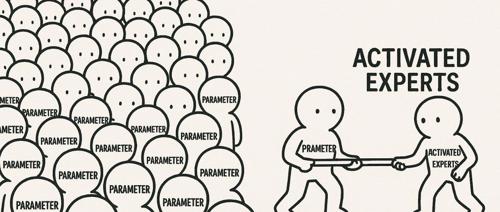
文章介绍了Gemma-3和DeepSeek V3在参数量上的对比,并指出模型效果不仅仅取决于参数大小。通过详细解释Dense和MoE架构的区别及其实际应用效果,强调了参数数量并不能直接反映模型性能优劣的观点。同时讨论了知识蒸馏技术如何让小模型继承大模型的能力,而不仅仅是关注模型的规模大小。
地平线提出AlphaDrive,首个基于GRPO强化学习和规划推理实现自动驾驶大模型

OpenAI的o1和DeepSeek的R1模型在复杂领域达到人类专家水平,AlphaDrive提出一种强化学习和推理训练框架用于自动驾驶规划,显著提升规划准确率并降低成本。
8张GPU训出近SOTA模型,超低成本图像生成预训练方案开源

港科大Harry Yang团队联合Everlyn AI提出LightGen模型,仅需8张GPU训练即可实现近SOTA的高质量图像生成效果。该模型采用数据蒸馏和直接偏好优化策略,显著降低了数据规模与计算资源需求。
【榜单征集】AI共潮生·2025甲子引力X科技产业新风向|甲子引力X

2025年中国AI产业逐浪者榜单启动征集,旨在评选在多领域创新和落地的先锋企业。涵盖AI芯片、算力基础设施、大模型等七个子领域,要求公司主营业务属上述细分领域的非上市公司,并满足成立时间、融资情况及商业化进展等条件。
精度效率双冠王!时序预测新范式TimeDistill:跨架构知识蒸馏,全面超越SOTA

新智元报道
编辑:LRST
近期,来自美国埃默里大学、澳大利亚格里菲斯大学等多地的华人科研团队提出了一种跨架构知识蒸馏框架TimeDistill,将MLP作为学生模型,其他复杂先进架构(如Transformer和CNN)作为教师模型,通过蒸馏复杂模型的优势至轻量级模型,实现计算负担大幅降低的同时显著提升预测精度。