记录一次Langgraph流式返回的问题处理过程——以及智能体debug的心得体会
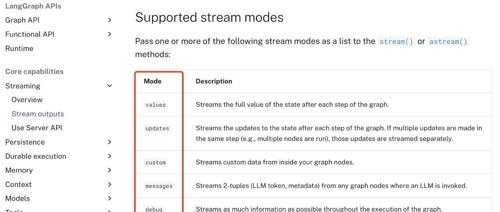
最近在做智能体的过程中遇到了流式返回的问题。作者通过调试发现是模型部署版本问题导致的。在智能体开发中,解决问题的最佳方式是一个功能点一个功能点的测试。
最近在做智能体的过程中遇到了流式返回的问题。作者通过调试发现是模型部署版本问题导致的。在智能体开发中,解决问题的最佳方式是一个功能点一个功能点的测试。
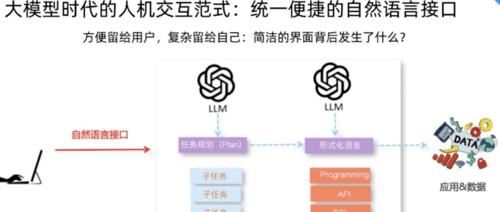
最近发现智能体能力有限,尤其在复杂真实场景中存在边界理解、工具调用限制等问题。为弥补缺陷,建议人机协同模式:智能体负责快速自动化处理,人力负责最终决策和责任兜底。
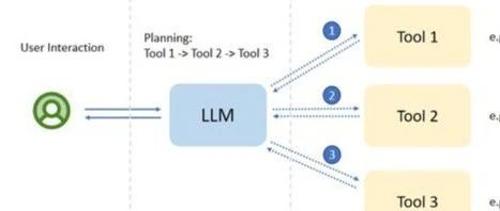
企业级智能体架构存在单智能体和多智能体两种模式。单智能体开发主要面临工具调用链路长、提示词过长及工具响应错误等问题,而多智能体开发则需解决不同智能体之间数据格式不一致及调度问题。总体而言,智能体开发理论简单但实现复杂。
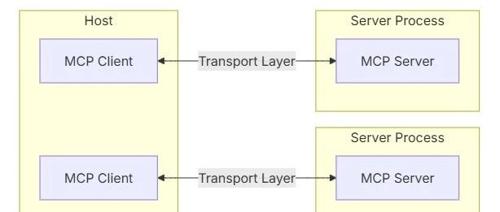
文章介绍了MCP协议的核心组件和其基于JSON-RPC2.0的传输方式,强调了MCP协议的灵活性以及开发者可以通过自定义报文格式来实现数据传输。

MCP协议是智能体开发中的标准协议,用于统一工具调用方式。FastMCP框架简化了协议实现过程,通过定义tools、resources和prompts等概念实现了简单而强大的接口。
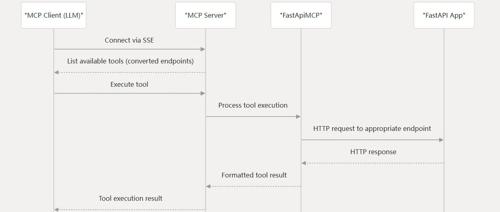
使用MCP协议解耦智能体和工具开发,通过动态配置提示词、记忆模块及功能实现快速调整智能体能力,同时支持独立部署或挂载到原应用。
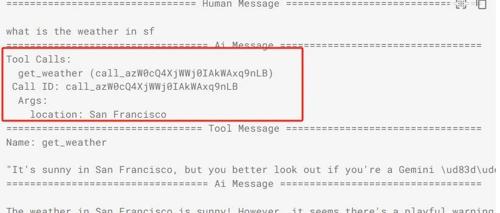
ReAct Agent基于思考-行动-观察的智能体,核心是通过提示词操作大模型完成任务。多种提示词范式如ICL、CoT、Self-Consistency等通过不同方式注入信息以优化模型能力。

Agent(智能体)是一种能够自主决策的系统,而Workflow(工作流)则是一个标准化固定流程的系统。二者虽然存在区别,但在某些场景下可以结合使用,并且随着技术的发展可能会逐渐融合。