
近一阶段,强化学习成为进一步提升大模型能力的共识路径,这时候,你是不是也觉得,给大模型套上强化学习(RL)的缰绳,再用上那些能自动验证对错的奖励机制(RLVR),就能让它们像打了鸡血一样,推理能力蹭蹭往上涨,实现模型自我进化,“左脚踩右脚”不断飞升。
然而,清华大学近期的一项研究《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?(强化学习真的会激励 LLMs 基模型之外的推理能力吗?)》为这一乐观预期泼了一盆冷水。该研究通过深入分析指出,尽管RL训练能够显著提升模型在特定基准(如pass@1)上的表现,但可能并未从根本上拓展模型推理能力的边界。

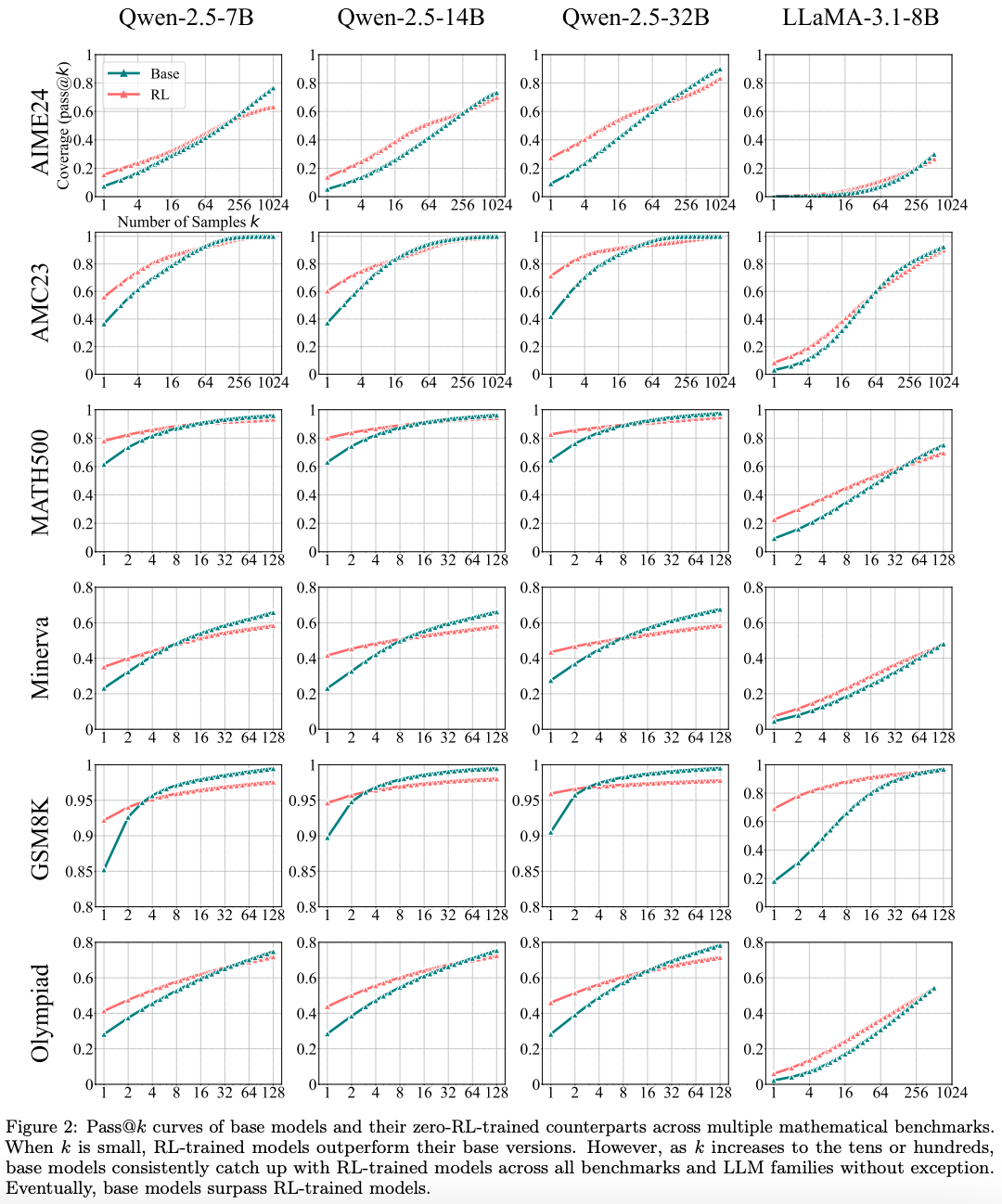
研究采用了pass@k(模型在k次尝试内解决问题的成功率)作为核心评估指标。结果显示,虽然经过RL训练的模型在少量尝试(低k值)下表现优于基础模型,但当给予充足的尝试机会(高k值)后,未经RL训练的基础模型不仅能够追赶上来,解决同样的问题,甚至在某些任务中展现出相当乃至更高的潜力上限。
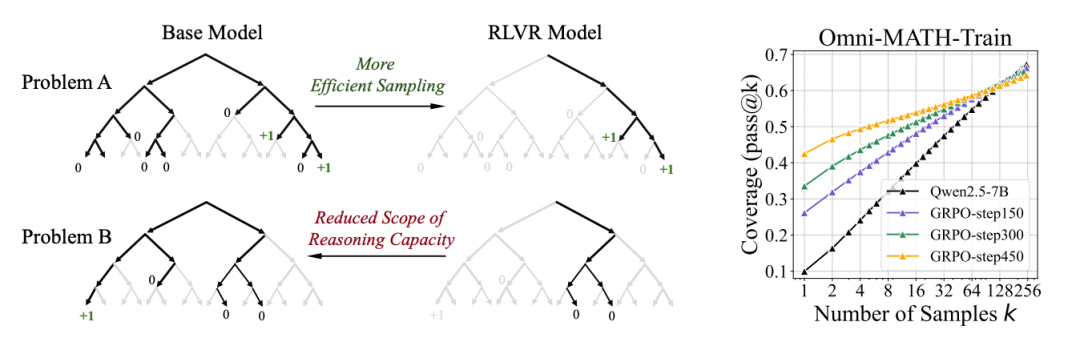
这一发现表明,当前RLVR技术的核心作用可能更多体现在提升“采样效率”,即更快速、更稳定地找到模型知识体系中已经存在的、能够获得奖励的正确推理路径。这类似于提高了模型针对已知类型问题的“应试技巧”。
但效率的提升可能伴随着代价。研究观察到,RL训练在强化特定路径的同时,可能限制了模型的探索性,降低了其生成不常见或全新正确解法的概率,从而可能导致整体推理能力的“覆盖范围”收缩。这意味着,模型的世界观非但没有拓宽,反而可能在某种程度上变窄了。
因此,该研究对“LLM通过RL实现持续自我进化”的普遍观点构成了挑战。RLVR当前的作用,或许更接近于一种高效的优化或压缩机制,而非真正意义上的“认知能力催化剂”。它擅长挖掘和巩固基础模型已有的潜能,但在激发全新推理范式方面可能存在局限。值得注意的是,研究也对比指出,知识蒸馏等其他技术,通过学习更强教师模型的模式,反而能够有效地为模型引入新知识,拓展其能力边界。
这篇论文让我们不得不反思,让大模型真正实现推理能力的飞跃,光靠现在的RL“鞭策”可能还不够,需要认识到它的固有局限。要实现推理能力的根本性突破,还是需要进一步探索新方法,这样才有可能有更大的突破。
公众号回复“进群”入群讨论。

(文:AI工程化)