
SOTA
huggingface发布了3B参数里的SoTA模型 smollm3
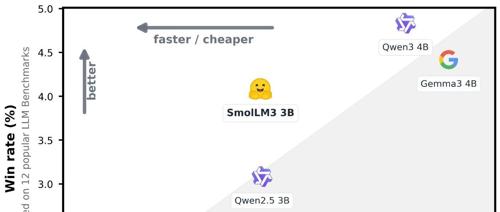
Hugging Face 发布了3B参数的SOTA模型 Smollm3,支持Think/No-Think模式,默认不支持汉语,未来将发布其详细信息及构建方法。
ICCV 2025 南开等提出REG方法,直接、高效地利用判别性信息,几十倍加速扩散模型训练!

本文提出了一种名为REG的方法,通过将低级图像潜在表示与高级类别令牌进行‘纠缠’来加速扩散模型的训练,并在ImageNet上实现了高达63倍的训练加速。
赶超DeepSeek、阿里Qwen!百度文心4.5系列模型正式开源,性能出色但领跑有点难

百度正式宣布开源文心4.5系列模型,该系列包含多模态异构MoE预训练、可扩展高效的基础设施以及针对特定模态的后训练技术。模型在多个基准测试中表现优异,覆盖了文本和多模态任务。


AgentAuditor: 让智能体安全评估器的精确度达到人类水平

LLM 智能体自主决策能力提升带来安全性评估难题,研究者提出 AgentAuditor 解决方案,显著提升 LLM 评估器精确度至人类水平。
网页编程众测排名:DeepSeek-R1超越Claude 4加冕全球第一

DeepSeek新版R1-0528在编程能力测试中表现突出,能在网页编程上击败Claude Opus 4。实测显示其能快速生成太阳系动画、AGI主题网站及俄罗斯方块游戏代码,并且对国内用户更为友好。
字节开源视觉-语言多模态大模型,AI理解现实世界的能力越来越强了。

字节开源的Seed1.5-VL是视觉-语言多模态大模型,支持多种复杂任务如盲人判断红绿灯和智能导盲。其包含5.32亿参数视觉编码器和200亿激活参数混合专家大语言模型,已在多个公开基准中表现出色。
智源3款向量模型发布!代码检索及多模态维度刷新多项SOTA

智源研究院发布三款向量模型,包括代码向量模型BGE-Code-v1、多模态向量模型BGE-VL-v1.5和视觉化文档向量模型BGE-VL-Screenshot,它们在代码及多模态检索中取得了最佳效果,并登顶多项测试基准。这些模型目前已向社区开放,支持各类应用场景。