
一手实测让马斯克睡帐篷的Grok4,DeepSeekR2又多一位可笑的对手

马斯克的Grok4发布会因推迟和低效表现引发关注。尽管新套餐价格高昂,但其在数学、物理等领域表现亮眼,但在代码编写和多模态任务上存在局限性。作者分享了使用基础版Grok4的经验,并提出了一些改进意见。
马斯克的Grok4发布会因推迟和低效表现引发关注。尽管新套餐价格高昂,但其在数学、物理等领域表现亮眼,但在代码编写和多模态任务上存在局限性。作者分享了使用基础版Grok4的经验,并提出了一些改进意见。

字节开源的Seed1.5-VL是视觉-语言多模态大模型,支持多种复杂任务如盲人判断红绿灯和智能导盲。其包含5.32亿参数视觉编码器和200亿激活参数混合专家大语言模型,已在多个公开基准中表现出色。

文章介绍了字节跳动发布的新模型豆包1.5和视觉版Doubao-1.5-thinking-pro-vision,并展示了它们在推理位置、根据冰箱内容定制食谱、判断车祸原因以及家居改造建议等方面的出色表现,对比了与OpenAI o3的差异。
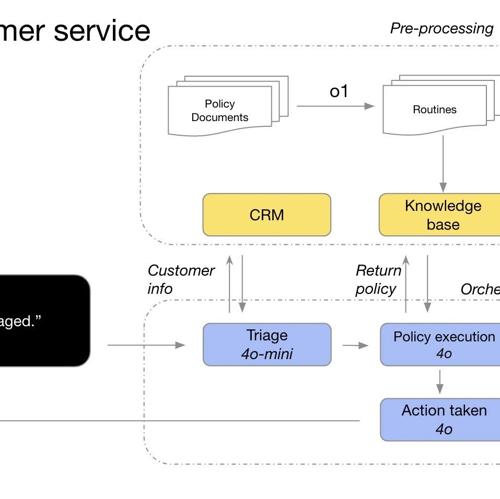
OpenAI发布了推理模型的最佳实践,包括何时使用这些模型(如模糊任务、大海捞针)、如何有效利用以及一些基本原则和技巧。
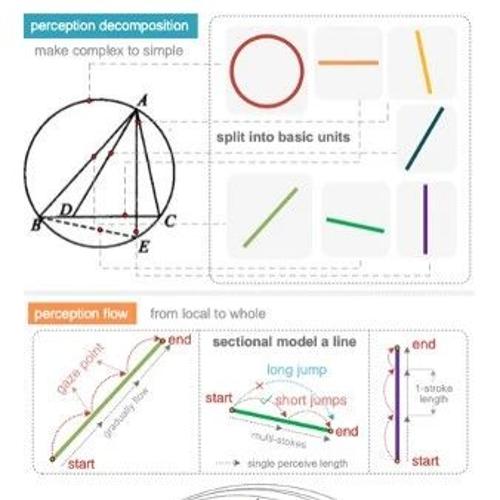
StepFun多模态团队提出慢感知概念,通过感知分解和感知流动两个阶段实现几何图形精细感知。该方法在几何parsing任务上取得显著效果,展示了视觉系统2的优势。




