
昨天 Open AI 发布 o3 之后,早上尝试的的时候被 OpenAI 的降智快要折磨的砸电脑了。
刚好字节给开放了今天发布的豆包1.5深度思考模型,包含一个语言模型Doubao-1.5-thinking-pro,还有一个视觉版Doubao-1.5-thinking-pro-vision使用权限。
顺手用一些案例测试了一下,结果发现这俩玩意相当可以啊。
语言模型作为一个总大小 200B 激活参数 20B 的 MoE 模型,从规模上差 o3 很远。
但是 o3 可以完成的一些日常任务,Doubao-1.5-thinking-pro在给了一些提示后都能完成而且完成的不错。
这要再整个规模大点的模型,又可以不受 Open AI 的气了。更令人好奇的是视觉版Doubao-1.5-thinking-pro-vision,目前还没披露详细的技术报告。
我们还是来看一下测试结果。
根据照片推理位置
o3 最著名的一个用例就是根据图片推论图片拍摄的位置,我从小红书找了一个徒步路线的图片,想试试豆包模型能不能搞定,这是河北的易水湖景区,没想到真的可以,离谱了。
发给豆包模型之后他根据湖水、植被类型、山脉特征判断大致位置,之后有根据我的徒步路线这个信息思考了华北的类似区域和徒步路线最后确定了徒步线路的位置。
后面根据这个信息给出了这条路线的详细信息,还有徒步需要准备的东西和注意事项。


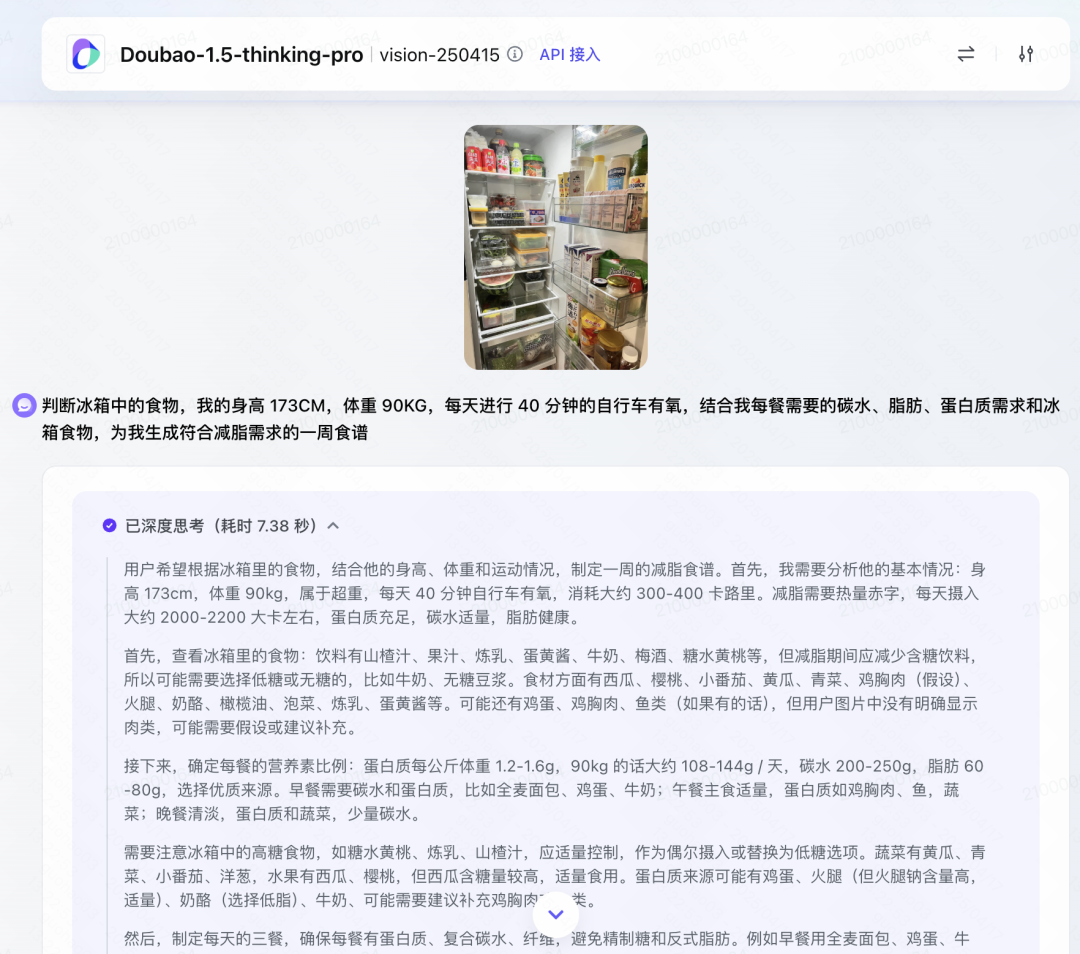
根据冰箱内容定制食谱
是不是想减肥但不知道每天应该怎么吃,Doubao-1.5-thinking-pro-vision 帮你识别冰箱中的所有食物并且结合你的身高、体重和运动量量确定每天的三大营养素摄入指标,身为你定制减肥食谱。
他还会提醒你冰箱里哪些需要少吃,另外会推荐最优的方案,也可以提供了冰箱食物的替代版本。

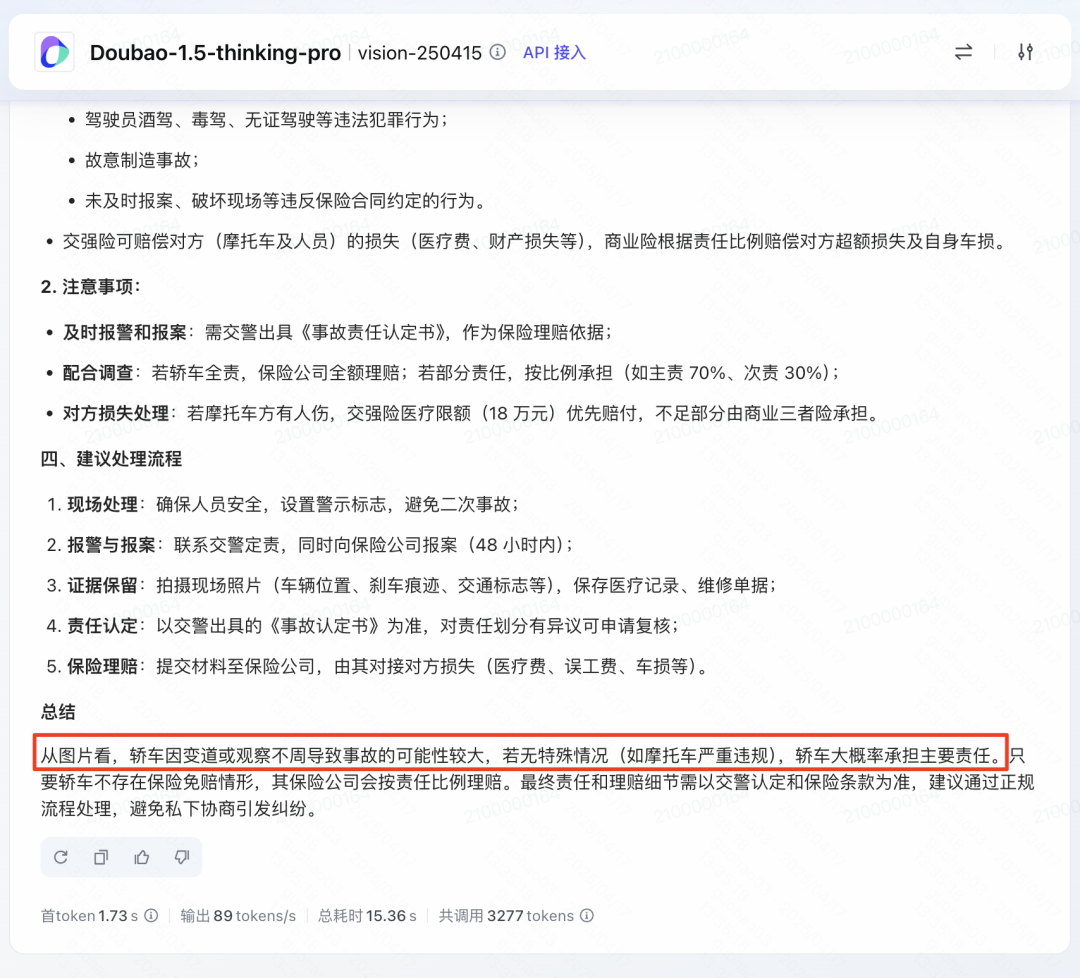
根据照片判断车祸原因和责任
很多朋友可能喜欢看车祸事故视频下饭或者自己开车不好判断事故责任问题,我们在小红书找一个撞车事故的图片,看看豆包模型能不能猜出事故的原因。

我本来不报期望的,因为这个图片的信息太少了,红绿灯之类的都没有,但是豆包模型还是基于两车接触位置和摔倒的姿态判断出了车祸的原因,就是因为视野盲区加车主没注意撞了摩托车,说明图片信息真的参与了推理过程。

育儿家居改造建议
豆包这个视觉思考模型视觉版也支持多张图片进行推理。
这里我上传了一个房子不同房间和角度的照片,让豆包给出可以为孩子降生做的家装整改建议。
他分析了现在屋子的陈设以后先是给出了一些针对安全的建议,后面针对方便育儿给出的物品陈列和摆放建议也很实用,还设计了安全防护 + 动线便利 + 弹性收纳三步走的调整策略,非常条理。


AI 编程和多模态就是今年最重要的两条主线叙事,Open AI 靠着在多模态和生成上的爆发在今年继续站稳了自己的位置。
而且无论是视觉推理还是多模态图片生成都是非常前沿的结果。
不得不说字节真的很有前瞻性,豆包文生图Seedream3.0(即梦3.0接入的模型)和豆包Doubao-1.5-thinking-pro-vison在这两个层面都在发力,现在也有了一些不错的成果。
我们有理由相信他们会是国内最快能够追上 Open AI 在这两个层面进度的公司。
(文:归藏的AI工具箱)