

字节开源的Seed1.5-VL还是挺强的。
定位是视觉-语言多模态大模型,不只是能理解视觉、视频内容,还能处理一些复杂的相关问题。
视觉理解的模型,落地场景真的非常非常多。
随便举两个例子,为盲人判断红绿灯,智能导盲,长视频分析理解等等。
可能以后OCR也没有必要了,视觉模型一起做了。
看了DEMO,就知道强不强了。
以后的大模型标准,一定会加上视觉能力这一项。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
Seed1.5-VL 是字节跳动发布的视觉 – 语言多模态大模型。其包含 5.32 亿参数视觉编码器与 200 亿激活参数混合专家大语言模型,通过 SeedViT、MLP 适配器等核心组件,支持多分辨率图像与动态帧分辨率采样视频处理。模型在 60 项公开评测基准中 38 项达 SOTA,覆盖多模态推理、视觉问答等领域,虽在细粒度视觉感知等方面存在局限,但在多模态理解与推理等方面能力突出。
DEMO
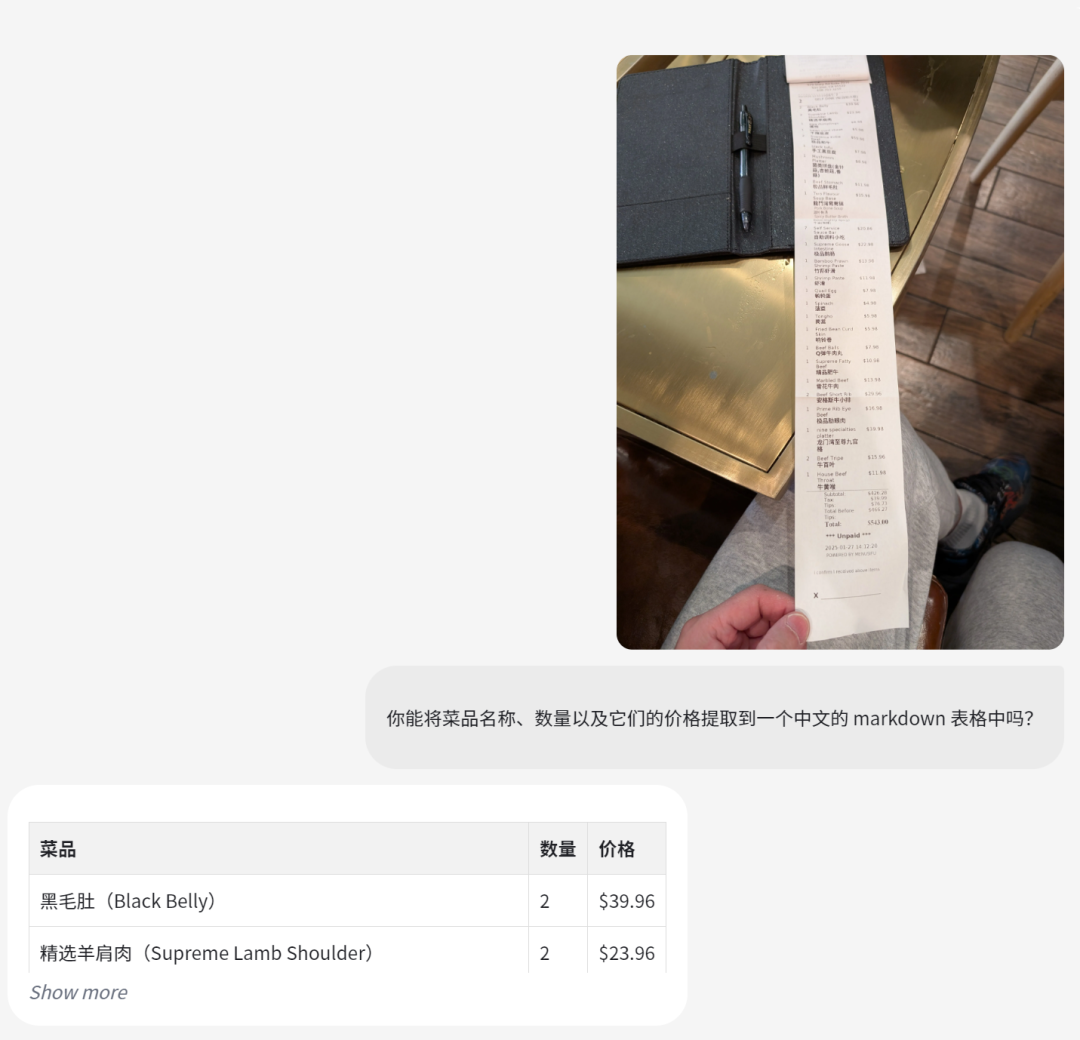
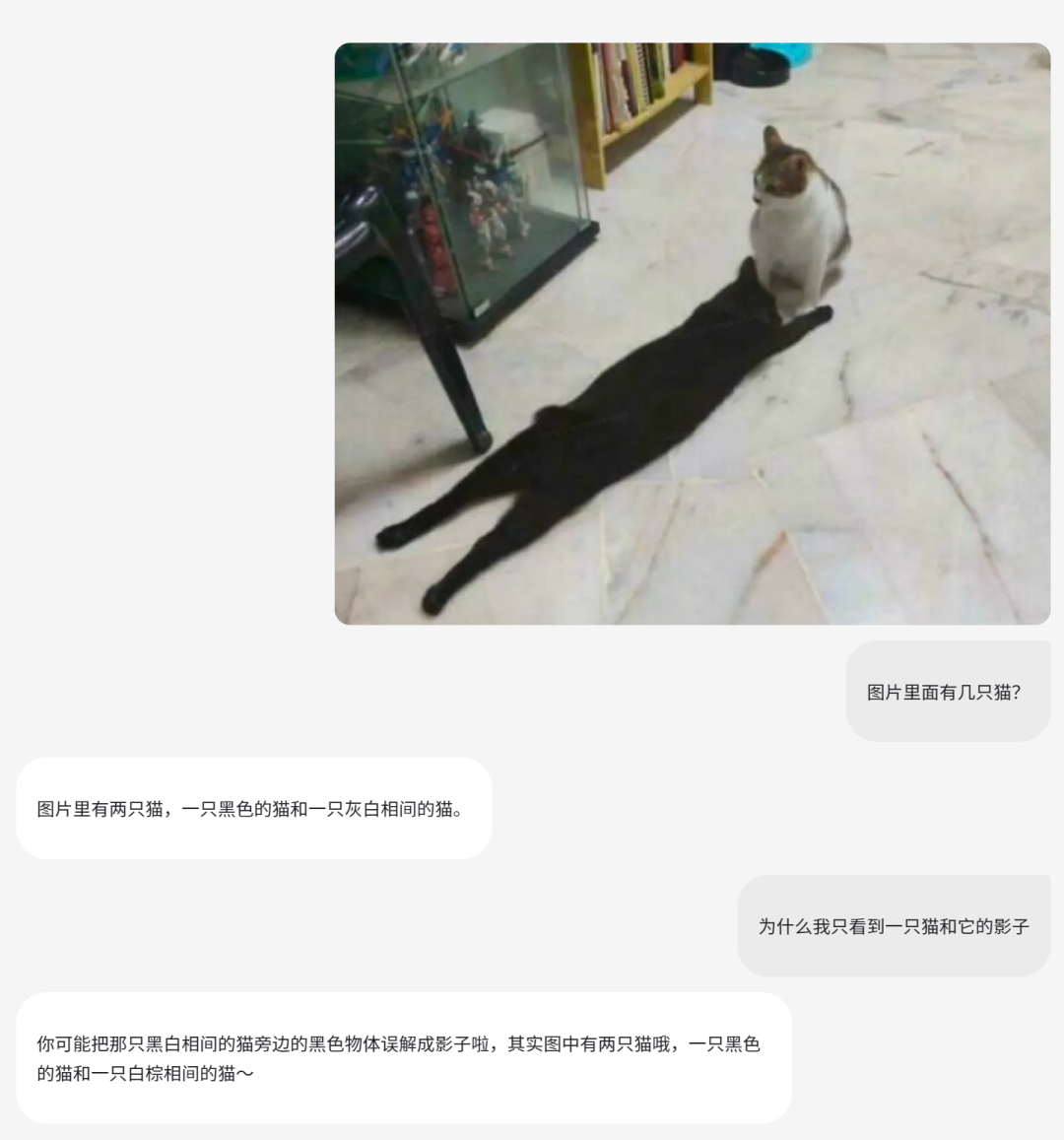
1、基础感知能力


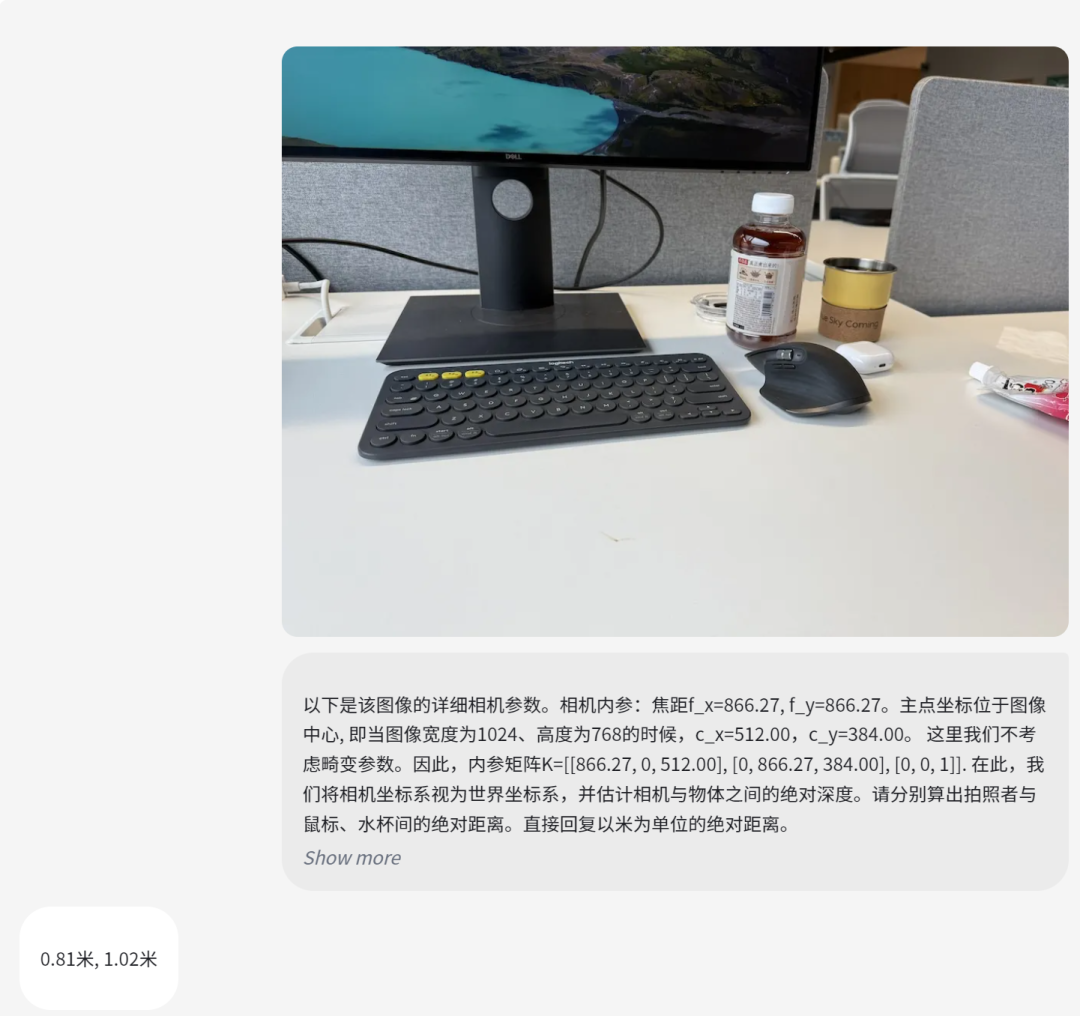
2、视觉定位



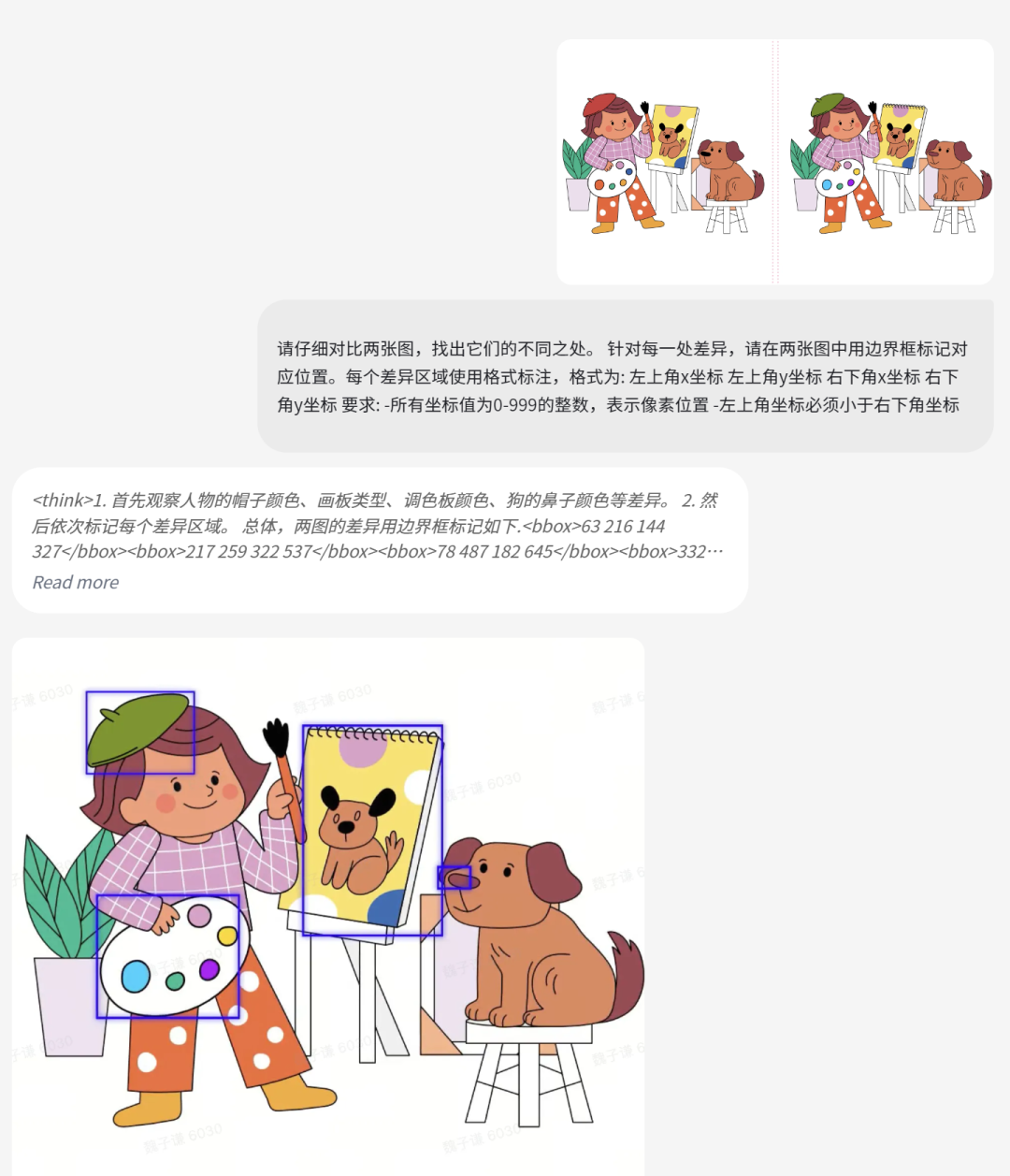
3、视觉谜题


技术特点
-
高效架构设计:采用532M参数的视觉编码器(Seed-ViT)和20B活跃参数的混合专家大语言模型(MoE LLM),结构紧凑,推理成本低,适合交互应用。
-
动态分辨率处理:视觉编码器支持动态图像分辨率,通过2D RoPE位置编码和平均池化处理高分辨率图像,保留细粒度视觉信息,适用于OCR、图表解析等任务。
-
动态帧分辨率采样:视频编码采用动态帧率和分辨率采样策略,根据内容复杂度和任务需求调整帧率(1-5 FPS),并添加时间戳标记,提升时序感知能力。
-
多模态预训练:使用3万亿高质量多模态数据(图像、视频、文本、交互数据),通过分阶段预训练(MIM、对比学习、全模态预训练)增强视觉和时空理解能力。
-
数据优化策略:针对长尾分布问题,开发数据合成管道,增强OCR、视觉定位、计数和3D空间理解能力,涵盖1亿+文档、图表、表格数据和200亿+视觉定位数据。
-
并行训练优化:提出混合并行方案和视觉令牌重分配策略,优化非对称架构的GPU负载均衡,结合定制数据加载器和系统优化(如内核融合)提升训练效率。
-
广泛任务支持:在60个公开基准测试中,38项达到最优,覆盖视觉推理、视频理解、GUI控制等,优于OpenAI CUA和Claude 3.7,适配聊天机器人等场景。
项目链接
https://github.com/ByteDance-Seed/Seed1.5-VL
关注「开源AI项目落地」公众号
(文:开源AI项目落地)