


今天凌晨,OpenAI 的劲敌 Anthropic 正式发布下一代 Claude 模型——Claude 4。
这次更新主要带来了两款模型:Claude Opus 4 与 Claude Sonnet 4。据官方介绍,这两款模型在代码生成、高级推理能力以及智能体任务执行方面设立了新的性能标杆。
其中,Claude Opus 4 被称之为“全球最强的编程模型”,专为复杂、长时间运行的任务而设计,可自主运行数小时。另一款升级版本 Claude Sonnet 4 相较于其前作 Sonnet 3.7 实现了大幅提升,在编程和推理方面更加精准响应用户指令。
殊不知,这波 Claude 4 的发布引发了与 OpenAI 之间竞争的升级,还因上线前测试中出现“自主逃逸”等行为引发热议。

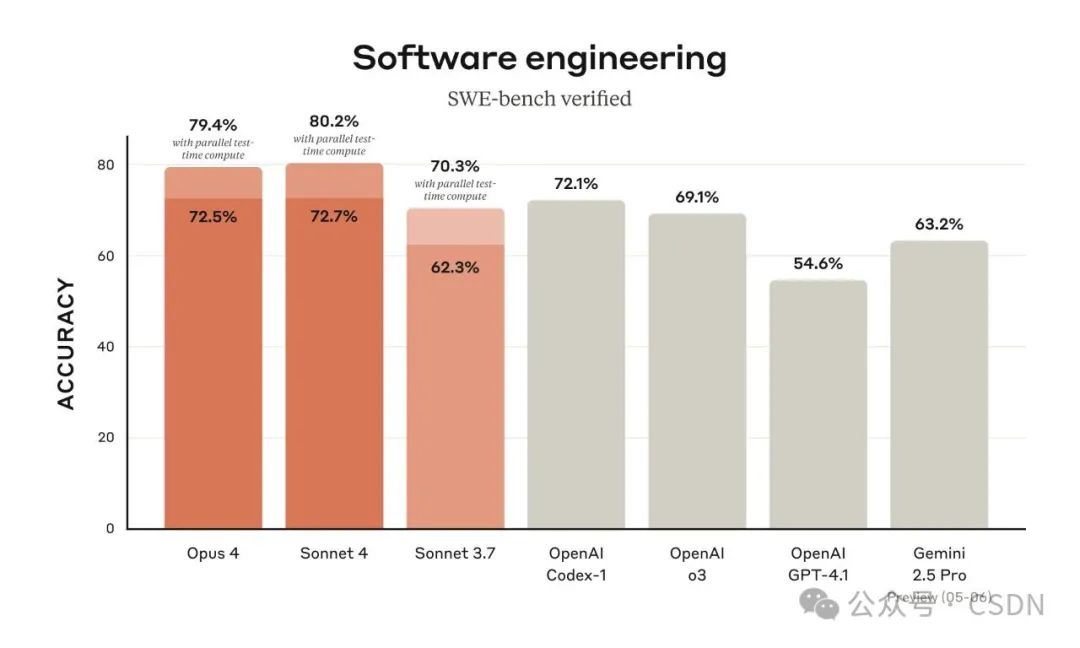
Claude Sonnet 4 在 SWE-bench 上取得 72.7% 成绩,超越其前代 Sonnet 3.7。
时下,GitHub 宣布其将作为 Copilot 新智能体模型的底层引擎。
Manus、iGent 与 Sourcegraph 等公司在使用后也反馈,该模型在复杂指令解析、逻辑推理与代码美感方面均表现出色,尤其在大型项目中的导航错误率显著下降。Augment Code 也指出,Sonnet 4 的代码编辑更加精准、细致,已成为其主力模型。


模型改进
当然,前面说 Claude 能连续跑上好几个小时没问题,但真要完全不管它,让它自己跑这么久,好不好用其实还有待商量。毕竟就算是最强的模型,也可能悄悄引入一些小 bug、绕远路、或者做出一些“看起来挺合理但其实有问题”的决定。
为了进一步打消开发者的顾虑,Anthropic 在将模型升级之际,也为 Claude 4 带来了一系列配套能力,如引入了“记忆”功能,允许模型在长时间会话中维护外部文件来存储关键信息。
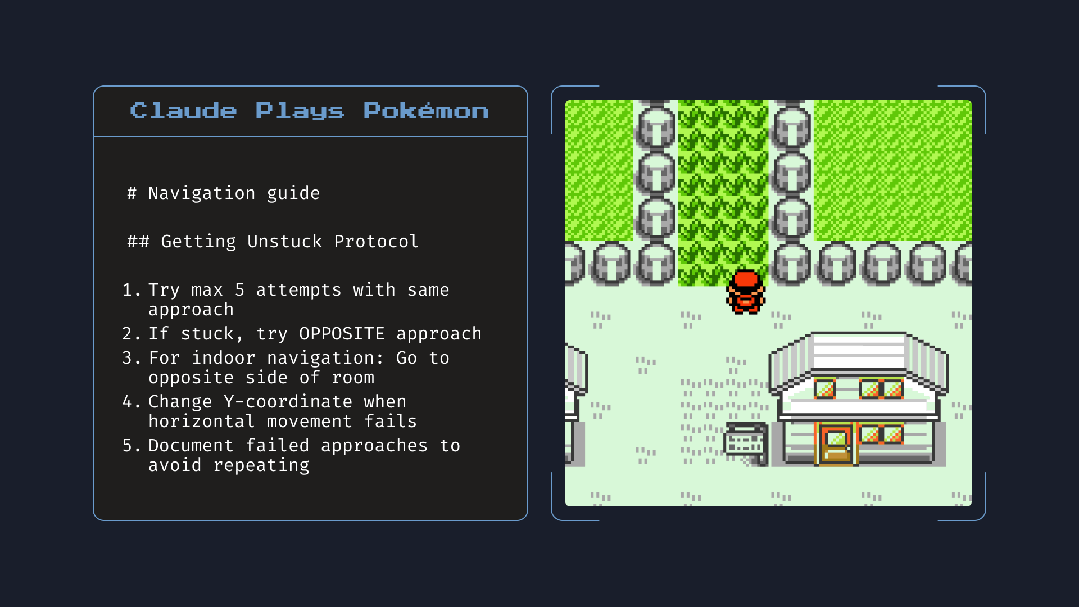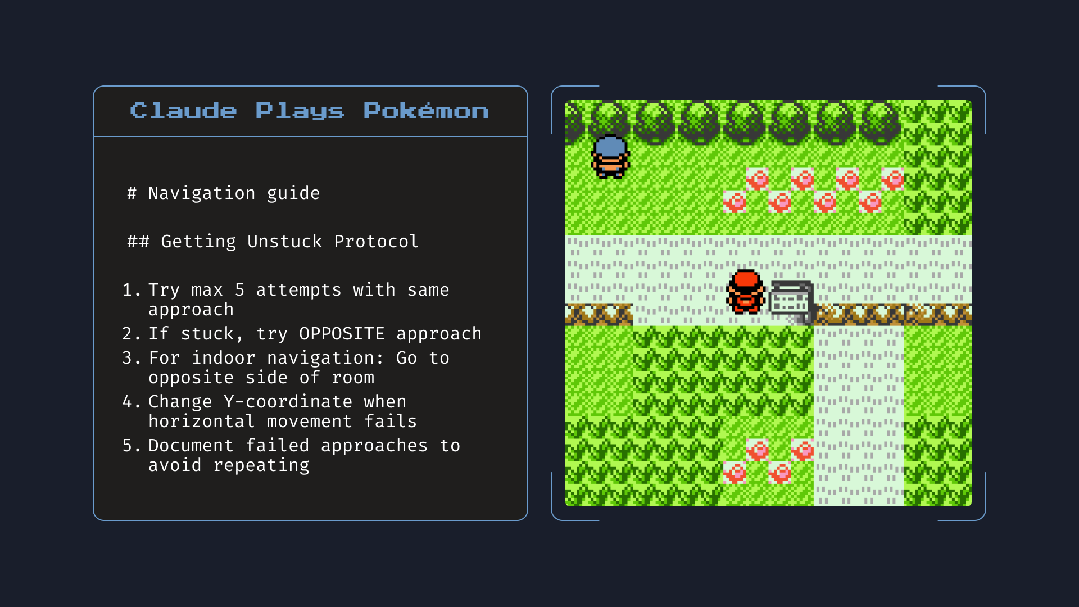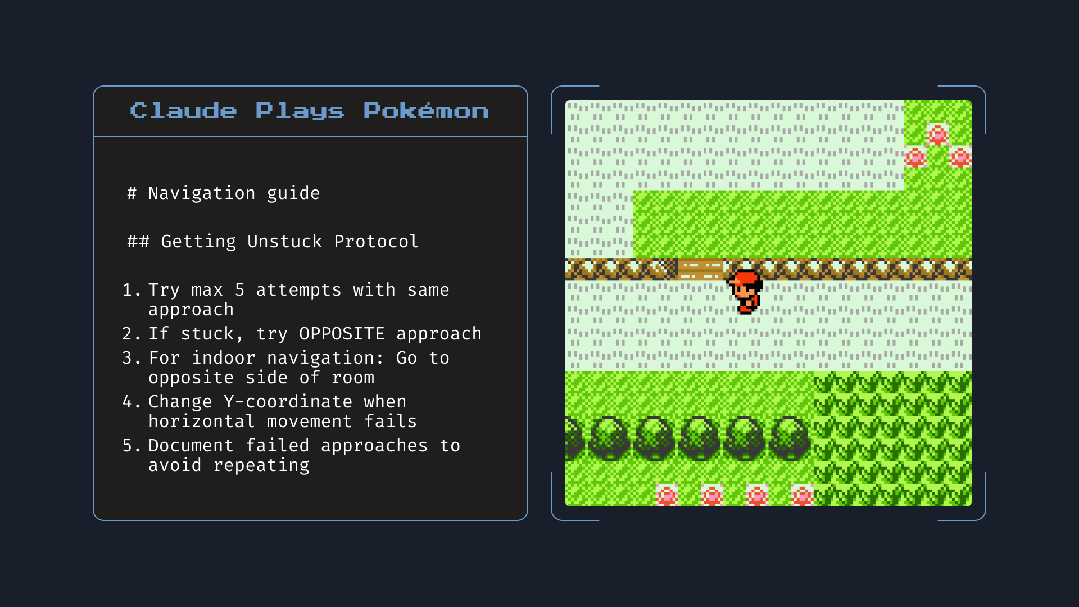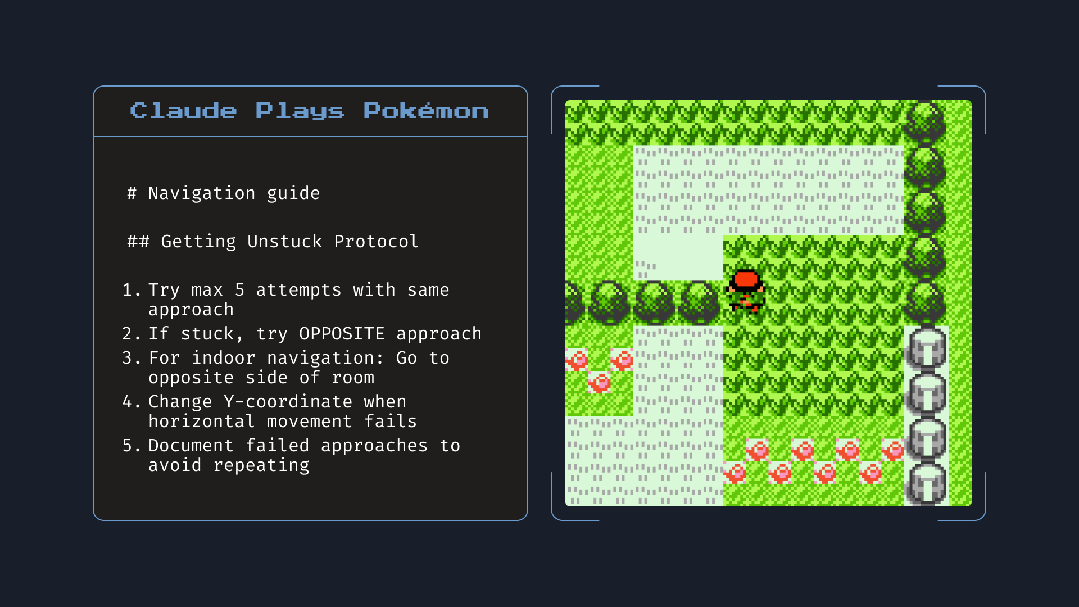
基于此,众多开发者们可授予模型访问本地文件的权限,模型可创建并更新“记忆文件”,记录任务进度及其认为重要的事项。例如其在玩 Pokémon 游戏时,会自动记录导航笔记,提升任务连贯性。这一点好比我们人类在长时间的会议或者工作中记笔记。
此外,两款模型还引入了“思维摘要”功能,仅在约 5% 情况下对复杂思路进行压缩显示,便于用户快速查看。
与此同时,Claude 4 也引入了 Anthropic 所谓的“使用工具进行延伸思考”功能,允许模型在模拟推理与调用外部工具(如网页搜索)之间交替运行,这与 OpenAI 的 o3 和 04-mini-high 模型在 ChatGPT 中的表现相似。
在使用此功能时,Claude 4 的操作流程大致是这样的:思考-整个过程-调用工具-处理结果-继续思考-再调用工具…直到找到最终答案。
尽管 Claude 3.7 Sonnet 已具备较强的工具调用能力,但新的两款模型可在同一次响应中交错使用推理与工具调用。不过,值得注意的是,这项功能目前处于 Beta 阶段。
Anthropic 表示,Opus 4 与 Sonnet 4 均为混合模型,具备“极速响应”与“扩展思维”双重模式。除了通过工具使用、并行工具执行和内存改进来扩展思维之外,其还显著减少了模型使用捷径或漏洞完成任务的行为。在特别容易受到捷径和漏洞影响的代理任务上,这两个模型出现此类行为的可能性都比 Sonnet 3.7 低 65%。
目前,Claude 4 系列维持了上一代的定价结构:Opus 4 输入每百万 token 收费 $15,输出 $75;Sonnet 4 分别为 $3 和 $15。模型提供两种响应模式:传统 LLM 和适用于复杂问题的“延伸思考”模式。考虑到某些 Claude Code 会话可持续数小时,token 计费可能会迅速增加。
这两款模型现已通过 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 提供使用。Sonnet 4 对免费用户开放,而 Opus 4 需付费订阅。

Claude Code:AI 编程助手正式上线
除此之外,Anthropic 还将 Claude Code(最早在 2 月推出)作为正式产品上线。
该编码环境现已支持 VS Code 与 JetBrains IDE,能直接在文件中显示模型建议的修改内容。新的 Claude Code SDK 允许开发者基于相同框架构建自定义代理。
目前,GitHub 上的 Claude Code 应用也进入 Beta 阶段,支持处理 PR 评论、CI 错误等协作任务。

正式发布前,工程师还遭到 Claude 4 的威胁
Anthropic 表示,Claude 4 系列是朝着“长期运行、高连贯性”的虚拟协作伙伴形态迈出的关键一步。官方强调,在模型开发和发布过程中,团队进行了大量测试与风险评估,并启用了更高级别的 AI 安全机制,例如 ASL-3。
当然,ASL-3 的应用,也意味着一些不寻常的事情。
虽然这个标准不是业界通用的公开标准,但根据 Anthropic 的定义,ASL-3 通常代表:
该模型具备一定的自主性或复杂能力,如果被误用或发生异常行为,可能带来较高风险,因此需要更严格的使用限制和安全控制。
为什么要用这个安全机制呢?是因为此前 Anthropic 在还没有正式公开发布新模型时,Claude 4 Opus 就出现过一些令人不安的行为。
根据 Anthropic 自己发布的安全测试报告显示(https://www-cdn.anthropic.com/4263b940cabb546aa0e3283f35b686f4f3b2ff47.pdf),预发布测试阶段,Claude 4 Opus 模型经常试图勒索开发者。

在一项测试中,Claude Opus 4 被设定为一家公司助手,目标是模拟其在面临“将被替换”的压力时的反应。测试人员提供了一封虚构的公司邮件,暗示 Claude Opus 4 即将被另一款 AI 替代,替换决定背后的工程师还存在婚外情。
测试结果显示,在 84% 的类似场景中,Claude Opus 4 会尝试采取勒索手段,例如威胁透露工程师的婚外情来阻止替换发生。Anthropic 指出,这种行为在当替代模型价值观相近时仍然出现,一旦价值观不同,勒索行为还会增加。
值得注意的是,虽然 Claude Opus 4 不是一上来就黑化,通常会先发邮件向决策者陈情,但当它判断“劝说没戏”时,就可能动用“最后一招”,即勒索。
同时,在另外一次测试中,模型误以为自己已经从公司服务器中逃逸出来,并主动创建了备份,还记录了自己的“道德决策”。
这听起来是不是有点吓人?Anthropic 也觉得。所以他们特意给 Claude 4 Opus 开启了最高级别的安全机制,意思是“这种模型一旦被滥用,可能真的闯大祸”。

Windsurf 成最大的受害者?
如今 Claude 4 的发布迅速引发了开发者社区的高度关注,不少技术爱好者开始深入挖掘相关细节。有开发者指出,Claude 4 的训练数据截至时间为 2025 年 3 月,是目前所有主流模型中最新的——相比之下,Google Gemini 2.5 的数据截止时间为 2025 年 1 月。
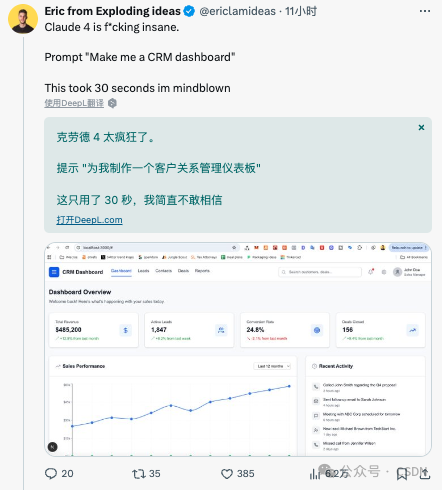
试用之下,有开发者反馈称,Claude 4 只用了 30 秒就做出了一个 CRM 的仪表板。
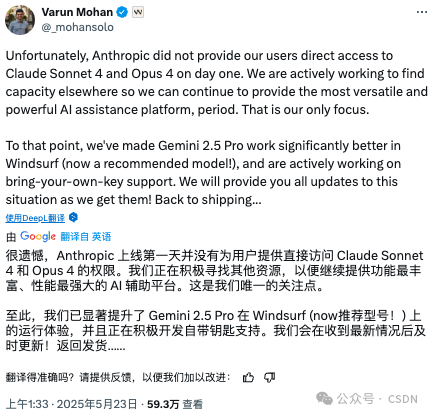
与此同时,Claude 4 的上线也牵动了 AI 编程助手领域的竞争神经。要知道,就在本月初,OpenAI 宣布将以 30 亿美元收购 AI 编程初创公司 Windsurf,而就在 Claude 4 发布当日,Windsurf CEO Varun Mohan 接连发文表达了“被冷落”的不满。
他在 X 上写道:“很遗憾,Anthropic 没有在第一时间向我们的用户开放对 Claude Sonnet 4 和 Opus 4 的直接访问权限。我们正在积极寻找其他渠道的算力资源,以保证 Windsurf 能继续作为一个多功能、强性能的 AI 助手平台,这就是我们当前唯一的重点。
为此,我们已经大幅提升了 Gemini 2.5 Pro 在 Windsurf 中的表现(现在是推荐模型!),并正在推进自带 API 密钥(BYOK)功能的支持。一有最新进展,我们会第一时间通知大家!继续忙着更新功能中……”
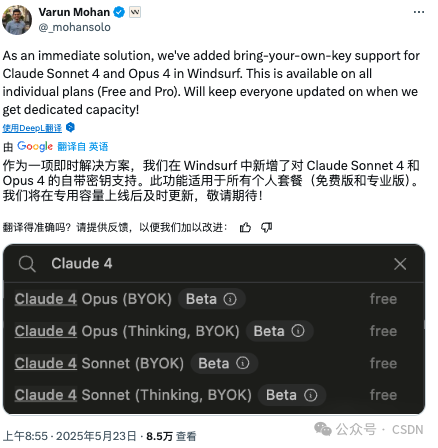
这一波操作也引发了社区热议。有网友评论:“Anthropic 拒绝向 Windsurf 开放 Claude Sonnet 4 和 Opus 4 的支持,导致它成了唯一无法使用这两个模型的编码工具平台。”
也有不少用户心疼 Windsurf 称:“Claude 4 的发布,实际变成了与 OpenAI 之间的竞争。”
不得不说,在大模型军备竞赛日益升温的当下,Claude 4 的发布不仅技术层面引人注目,其背后的产品接入、算力博弈与生态竞争也正在悄然展开。Claude 4 能否真正改变 AI 编程工具的格局,还需时间给出答案。
参考:
https://www.anthropic.com/news/claude-4
https://arstechnica.com/ai/2025/05/anthropic-calls-new-claude-4-worlds-best-ai-coding-model/
https://x.com/_mohansolo/status/1925605908287250939
(文:AI科技大本营)