
多模态推理


VRAG-RL:阿里开源多模态RAG推理框架,视觉信息理解与生成的“新引擎”!
阿里巴巴通义大模型团队推出VRAG-RL多模态RAG推理框架,通过视觉感知驱动和强化学习优化提升VLMs处理视觉丰富信息的能力。支持多轮交互、动态调整策略等,应用场景包括智能文档问答、视觉信息检索、多模态内容生成等。

地铁换乘都搞不定?ReasonMap基准揭示多模态大模型细粒度视觉推理短板

ReasonMap 是首个聚焦于高分辨率交通图的多模态推理评测基准,用于评估大模型在理解图像细粒度结构化空间信息方面的能力。
首个多模态专用慢思考框架!超GPT-o1近7个百分点,强化学习教会VLM「三思而后行」

研究团队提出VL-Rethinker模型,通过优势样本回放和强制反思技术解决多模态推理中的优势消失和反思惰性问题。该模型在多个数学和科学任务上超过GPT-o1,并显著提升Qwen2.5-VL-72B在MathVista和MathVerse上的性能。
类R1训练不再只看结果对错!港中文推出SophiaVL-R1模型

SophiaVL-R1 是一项基于类 R1 强化学习训练框架的新模型,它不仅奖励结果的准确性,还考虑了推理过程的质量。通过引入思考奖励机制和 Trust-GRPO 训练算法,SophiaVL-R1 提升了模型的推理质量和泛化能力,在多模态数学和通用测试数据集上表现优于大型模型。
看图猜位置不输o3!字节发布Seed1.5-VL多模态推理模型,在60个主流基准测试中拿下38项第一
字节发布轻量级多模态推理模型Seed1.5-VL,在60个主流基准测试中拿下38项第一,仅用532M视觉编码器+200亿活跃参数即能与大型顶尖模型抗衡。该模型通过多层次架构和训练细节实现了高效处理多种多模态数据的能力。
一个完整的多模态推理模型发展全景图
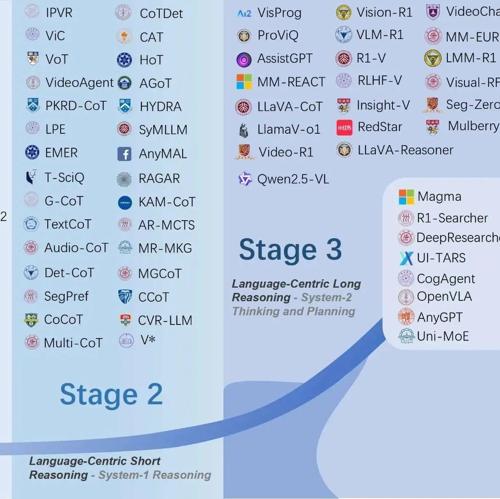
GitHub项目Awesome-Large-Multimodal-Reasoning-Models总结了多模态推理模型的四阶段发展历程,覆盖感知驱动、语言中心短推理、长推理以及原生多模态推理,并提供详细数据集和图表支持。
