



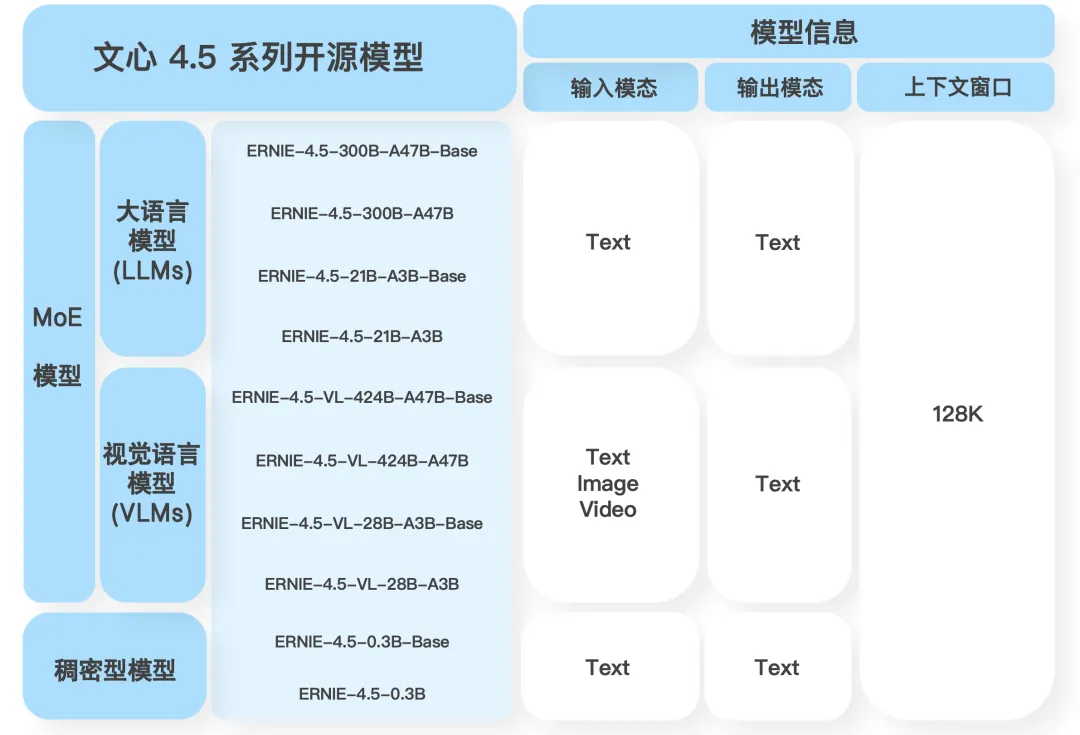
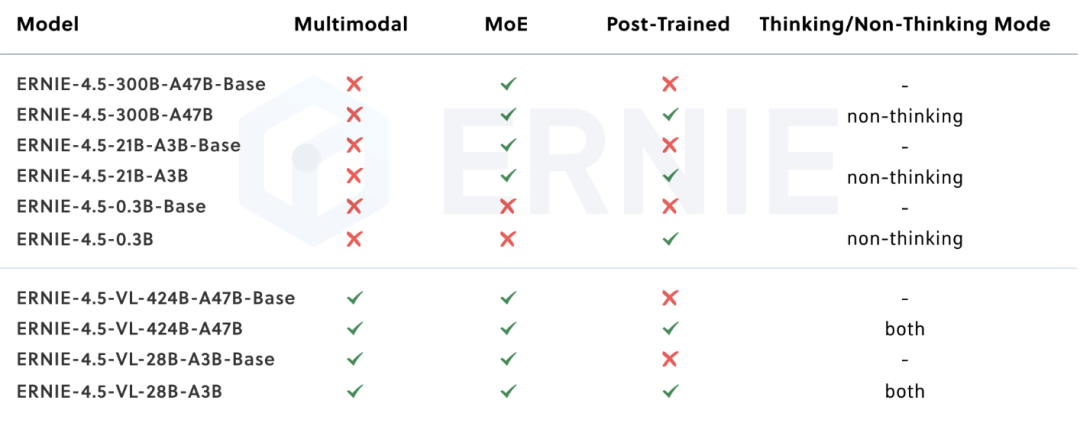

据介绍,文心4.5系列开源模型具有三大关键创新特点。
1、多模态异构MoE预训练:基于文本和视觉模态进行联合训练,以更好地捕捉多模态信息的细微差别,并提升文本理解与生成、图像理解以及跨模态推理等任务的性能,为此,百度团队设计了一种异构MoE结构,并引入了模态隔离路由,采用路由器正交损失和多模态标记平衡损失。
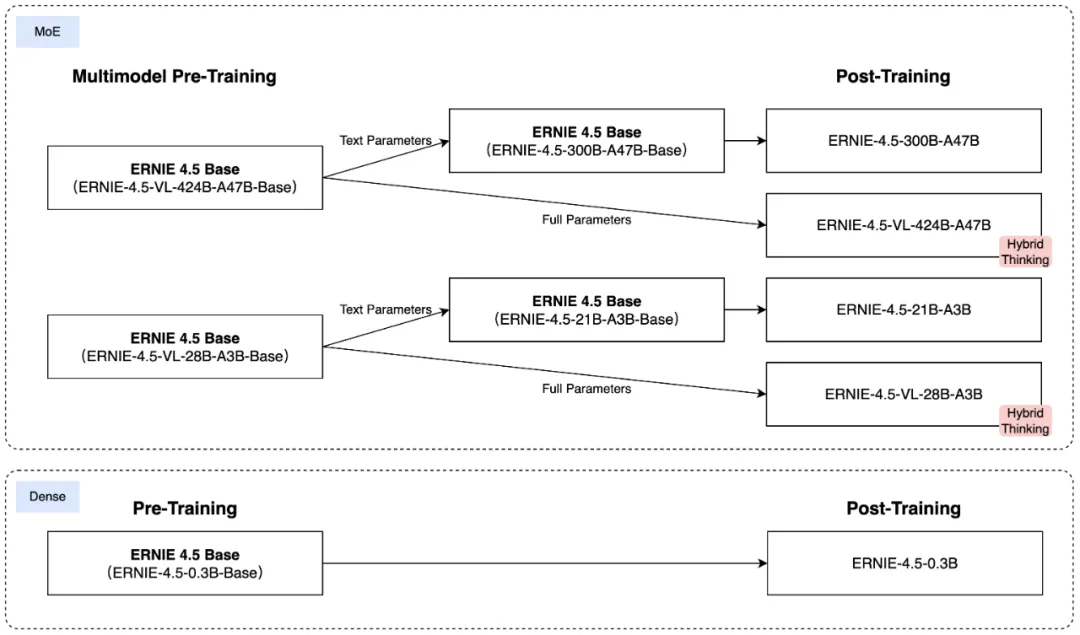
2、可扩展高效的基础设施:提出了一种新颖的异构混合并行和分层负载均衡策略,以实现ERNIE 4.5模型的高效训练。通过采用节点内专家并行、内存高效的流水线调度、FP8混合精度训练和细粒度重计算方法,我们实现了卓越的预训练吞吐量。
在推理方面,我们提出了多专家并行协作方法和卷积码量化算法,以实现4位/2位无损量化。此外,我们引入了具有动态角色切换的PD分解,以有效利用资源,从而提升模型的推理性能。
3、针对特定模态的后训练:为了满足实际应用的多样化需求,我们针对特定模态对预训练模型的变体进行了微调。每个模型都结合使用了监督微调(SFT)、直接偏好优化(DPO)或一种名为统一偏好优化(UPO)的改进强化学习方法进行后训练。
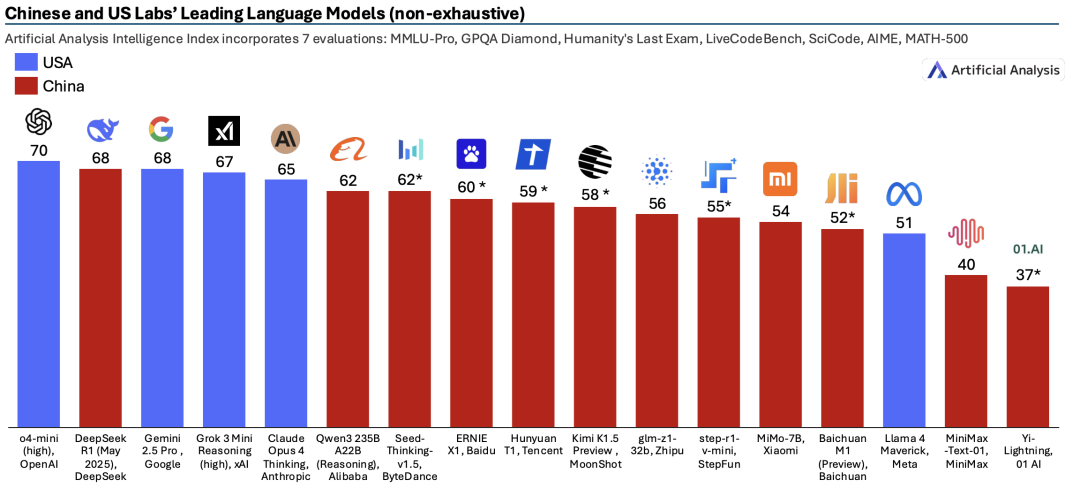
从百度给出的性能参数对比来看,ERNIE-4.5-300B-A47B-Base在28个基准测试中,有22个超越了DeepSeek-V3-671B-A37B-Base,凸显了ERNIE-4.5-Base模型相对于其他先进大型模型,在泛化、推理和知识密集型任务方面取得的显著提升。
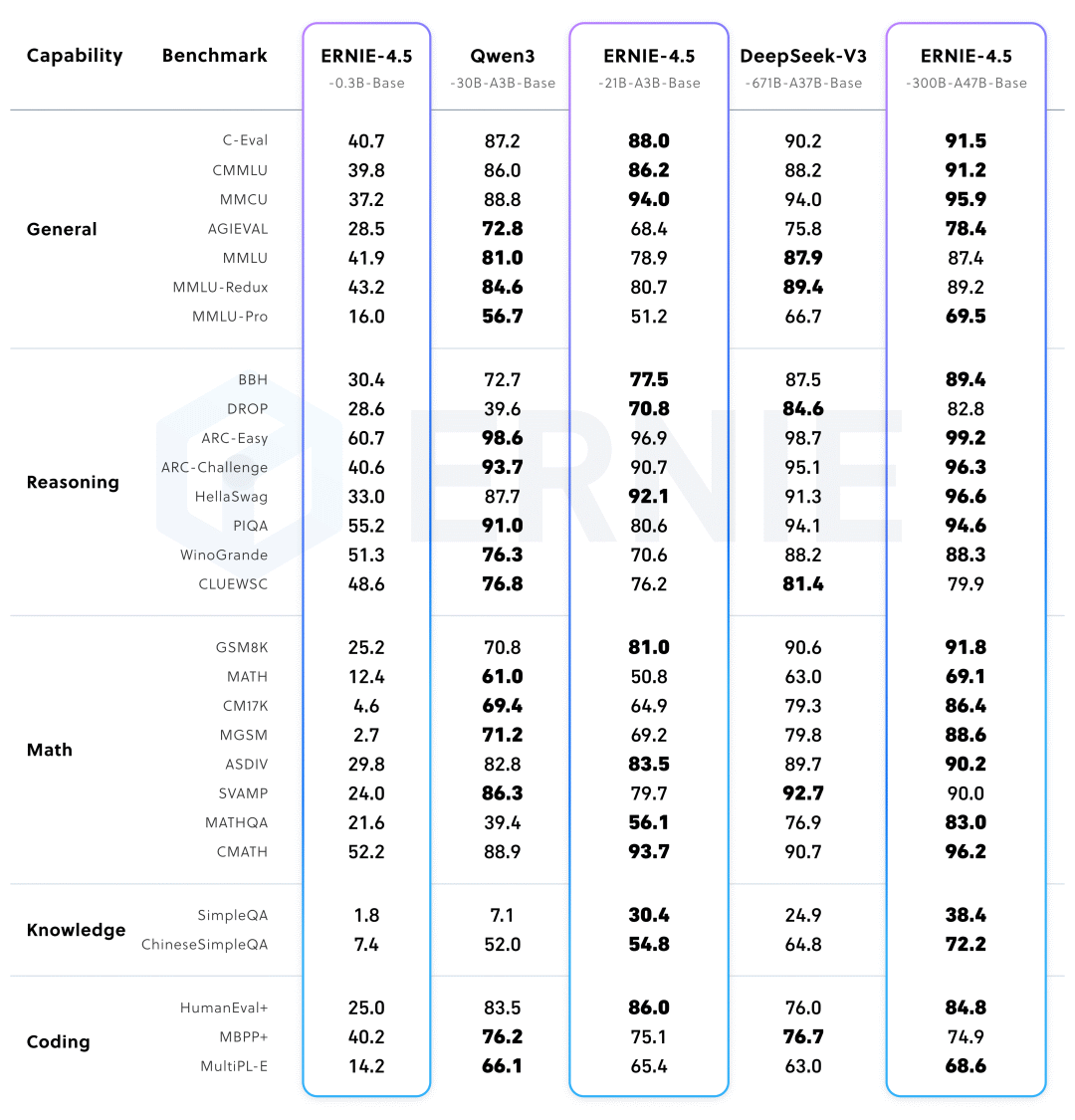
此外,ERNIE-4.5-21B-A3B-Base的总参数大小为21B的模型,在包括BBH和CMATH在内的多个数学和推理基准测试中优于Qwen3-30B-A3B-Base,展现出更好的参数效率和性能权衡。
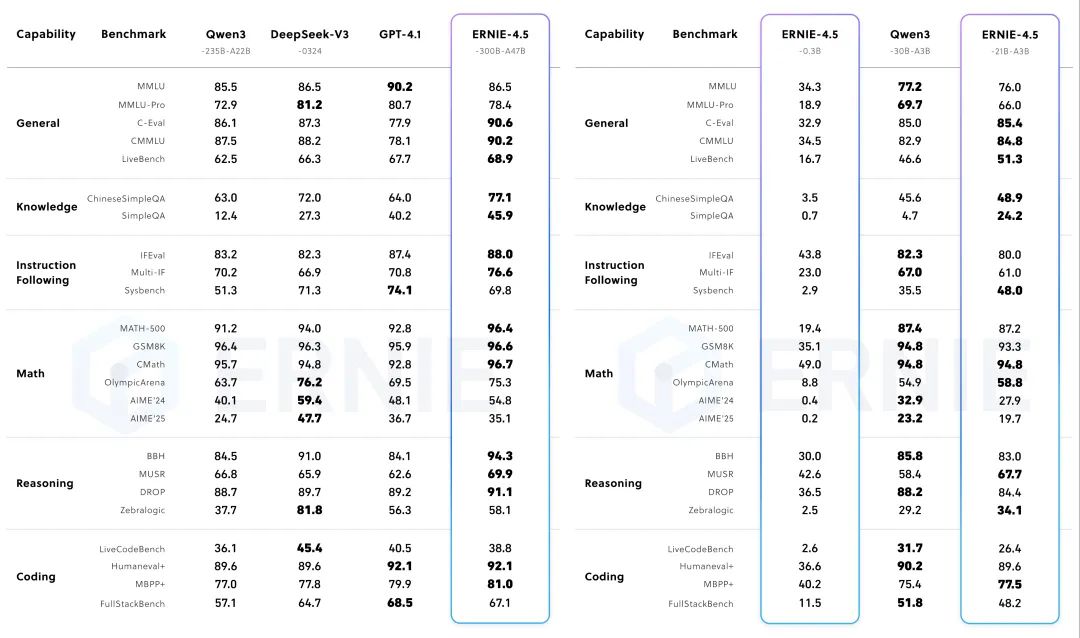
经过后期训练的ERNIE-4.5-300B-A47B模型在指令跟随和知识任务方面展现出显著优势,在IFEval、Multi-IF、SimpleQA等基准测试中取得的领先分数。轻量级模型ERNIE-4.5-21B-A3B的性能与Qwen3-30B-A3B相比依然具有竞争力,尽管总参数减少了约30%。
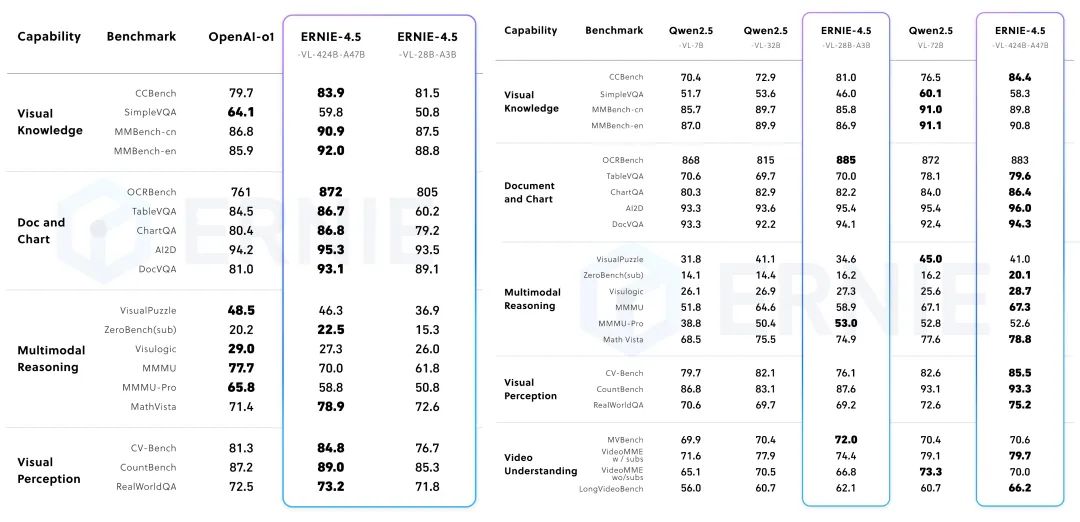
在非思考模式下,ERNIE-4.5-VL在视觉感知、文档和图表理解以及视觉知识方面展现出卓越的能力,在一系列既定基准测试中均有出色表现;在思考模式下,ERNIE-4.5-VL展现出比非思考模式更强的推理能力,同时保留了较强的感知能力。
值得注意的是,其轻量级模型也支持思考模式和非思考模式,提供与ERNIE-4.5-VL-424B-A47B一致的功能。
百度在今年2月14日就预告了要开源ERNIE 4.5,虽然只过去了4个月时间,但AI开源模型领域的各方竞逐却发生了深刻变化,尤其是在国内,从基础大模型到专项大模型,比封闭领域的模型PK还要激烈。
同样在今天,华为正式宣布开源盘古70亿参数的稠密模型、盘古Pro MoE 720亿参数的混合专家模型以及基于昇腾的模型推理技术;

6月,腾讯混元宣布开源首个混合推理MoE模型Hunyuan-A13B,总参数80B,激活参数仅13B,效果比肩同等架构领先开源模型;
“大模型六小虎”之中的月之暗面和MiniMax先后发布一系列最新开源模型,例如月之暗面的Kimi-Dev-72B、MiniMax-M1;
昆仑万维宣布开源2千亿稀疏大模型Skywork-MoE,据称是首个完整将MoE Upcycling技术应用并落地的开源千亿MoE大模型;
5月,DeepSeek-R1-0528开源,编码性能媲美o3 High和Claude 4;
4月,阿里Qwen3模型开源,参数规模从0.6B到235B,其Qwen3-235B-A22B 在编码、数学、通用能力等基准测试中取得了与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等其他顶级模型相比极具竞争力;同月,AI独角兽智谱一口气上线并开源了6款GLM模型(9B和32B),推理模型GLM-Z1-32B-0414做到了性能与DeepSeek-R1等顶尖模型相媲美的同时,实测推理速度可达200 tokens/秒。
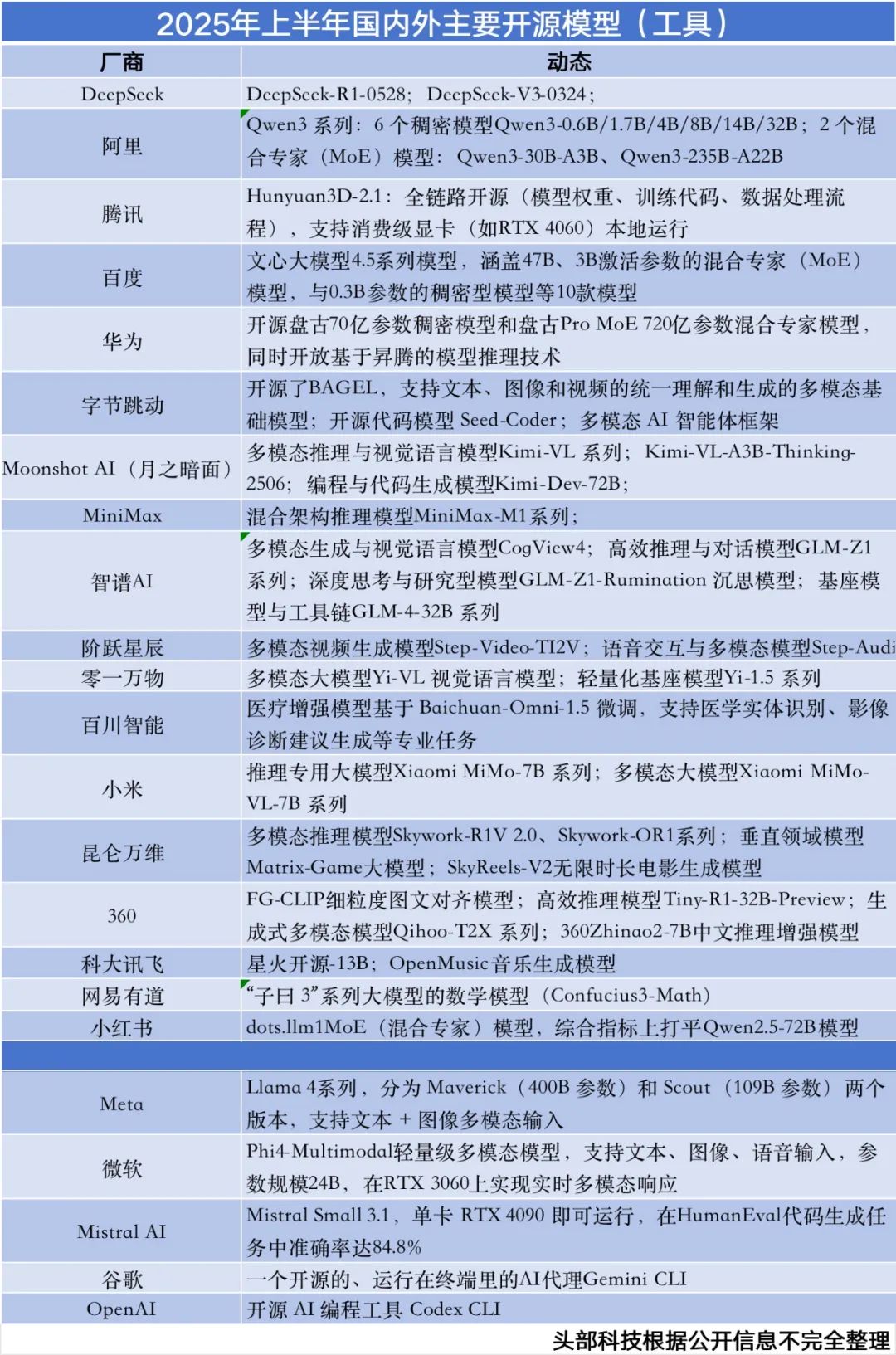
而且,开源AI模型赛道还不断有新选手加入,例如小米大模型Core团队推出的多模态开源模型MiMo-VL-7B系列,小红书hi lab团队推出的开源文本大模型dots.llm1等等。
当下的模型竞逐大环境下,想要成为“开源新王”并不容易,要么性能全球顶尖,要么生态足够强大。
随着各路市场参与者越来越卷,五花八门的AI开源项目令开发者目不暇接,百度需要持续推出更具行业突破性的创新成果才能俘获开发者认可,毕竟,此前在DeepSeek和阿里Qwen的轮番迭代下,开发者们对于开源AI模型的期待值也已经被拉到很高。
百度能不能创造出一个新的“DeepSeek时刻”有待观望,但可以肯定的是,百度转向开源阵营近一步强化了中国开源AI模型在全球范围内的技术竞争力,也更加需要着眼于与全球顶尖模型的竞逐。
-END-

(文:头部科技)