该函数用于批量修复缺失site的app,通过事件触发 site 重新创建,异常时记录失败并继续,直到全部处理完毕。
@click.command("fix-app-site-missing", help="Fix app related site missing issue.") deffix_app_site_missing(): """ Fix app related site missing issue. """ click.echo(click.style("Starting fix for missing app-related sites.", fg="green")) failed_app_ids = [] whileTrue: sql = """select apps.id as id from apps left join sites on sites.app_id=apps.id where sites.id is null limit 1000""" with db.engine.begin() as conn: rs = conn.execute(db.text(sql)) processed_count = 0 for i in rs: processed_count += 1 app_id = str(i.id) if app_id in failed_app_ids: continue try: app = db.session.query(App).filter(App.id == app_id).first() ifnot app: print(f"App {app_id} not found") continue tenant = app.tenant if tenant: accounts = tenant.get_accounts() ifnot accounts: print("Fix failed for app {}".format(app.id)) continue account = accounts[0] print("Fixing missing site for app {}".format(app.id)) app_was_created.send(app, account=account) except Exception: failed_app_ids.append(app_id) click.echo(click.style("Failed to fix missing site for app {}".format(app_id), fg="red")) logging.exception(f"Failed to fix app related site missing issue, app_id: {app_id}") continue ifnot processed_count: break click.echo(click.style("Fix for missing app-related sites completed successfully!", fg="green"))
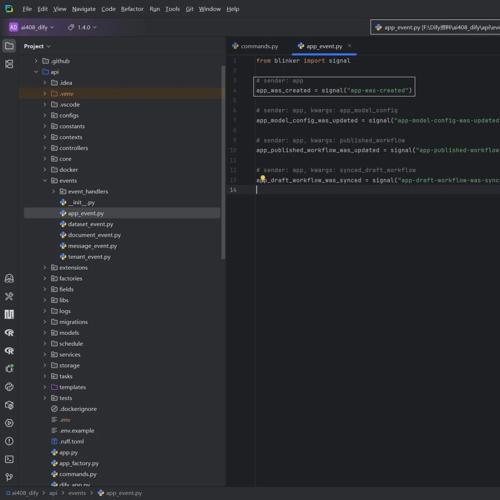
1.命令注册与函数定义
@click.command("fix-app-site-missing", help="Fix app related site missing issue.") deffix_app_site_missing():
通过 click 注册命令行命令 fix-app-site-missing,定义修复函数。
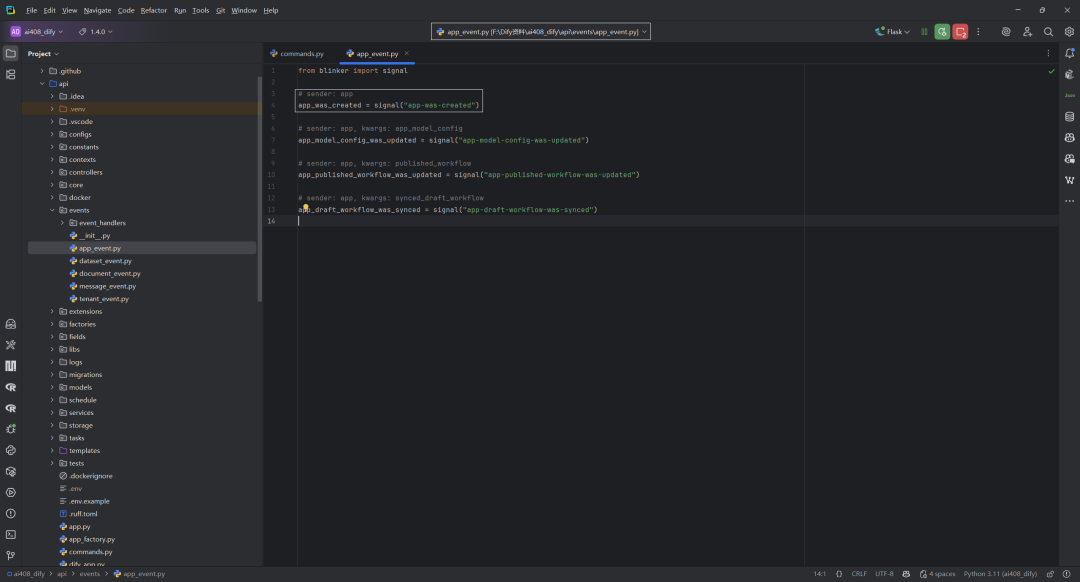
2.开始提示
click.echo(click.style("Starting fix for missing app-related sites.", fg="green"))
输出开始修复的提示信息。
3.初始化失败 app 列表
failed_app_ids = []
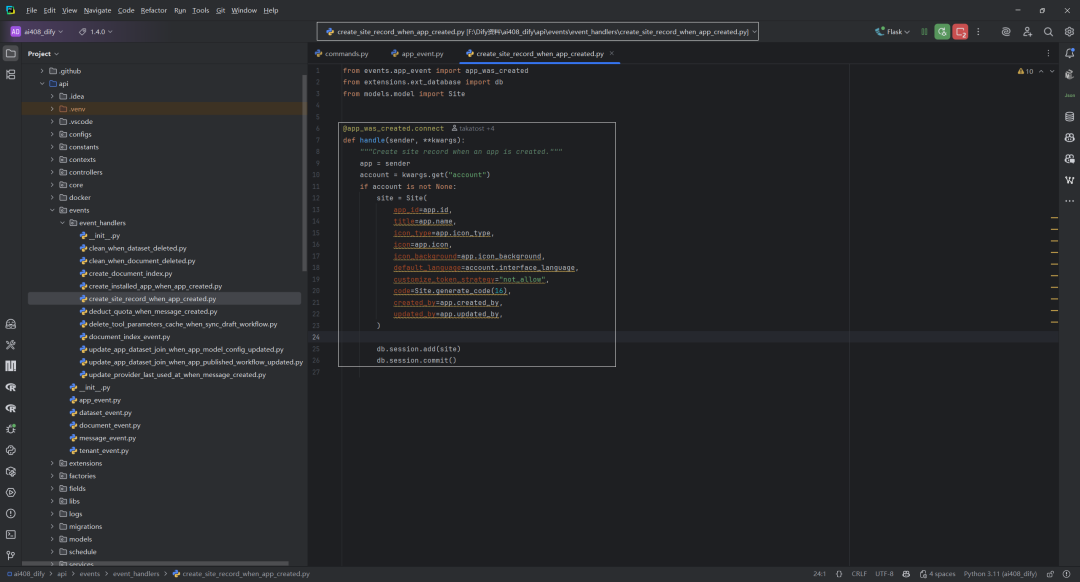
4.循环处理所有缺失 site 的 app
whileTrue: sql = """select apps.id as id from apps left join sites on sites.app_id=apps.id where sites.id is null limit 1000""" with db.engine.begin() as conn: rs = conn.execute(db.text(sql)) processed_count = 0 for i in rs: processed_count += 1 app_id = str(i.id) if app_id in failed_app_ids: continue try: app = db.session.query(App).filter(App.id == app_id).first() ifnot app: print(f"App {app_id} not found") continue tenant = app.tenant if tenant: accounts = tenant.get_accounts() ifnot accounts: print("Fix failed for app {}".format(app.id)) continue account = accounts[0] print("Fixing missing site for app {}".format(app.id)) app_was_created.send(app, account=account) except Exception: failed_app_ids.append(app_id) click.echo(click.style("Failed to fix missing site for app {}".format(app_id), fg="red")) logging.exception(f"Failed to fix app related site missing issue, app_id: {app_id}") continue ifnot processed_count: break
通过 SQL 查询找出没有 site 记录的 app(每次最多 1000 条)。
遍历每个 app id,跳过已失败的。
查询 app 实体,若不存在则跳过。
获取 app 的 tenant,若 tenant 存在,获取其 accounts,若无账号则跳过。
取第一个账号,调用 app_was_created.send(app, account=account) 触发 site 创建事件。
若过程中有异常,记录失败 app id 并输出错误日志。
若本轮没有处理任何 app,则跳出循环。
5.结束提示
click.echo(click.style("Fix for missing app-related sites completed successfully!", fg="green"))
@click.command("migrate-data-for-plugin", help="Migrate data for plugin.") defmigrate_data_for_plugin(): """ Migrate data for plugin. """ click.echo(click.style("Starting migrate data for plugin.", fg="white")) PluginDataMigration.migrate() click.echo(click.style("Migrate data for plugin completed.", fg="green"))
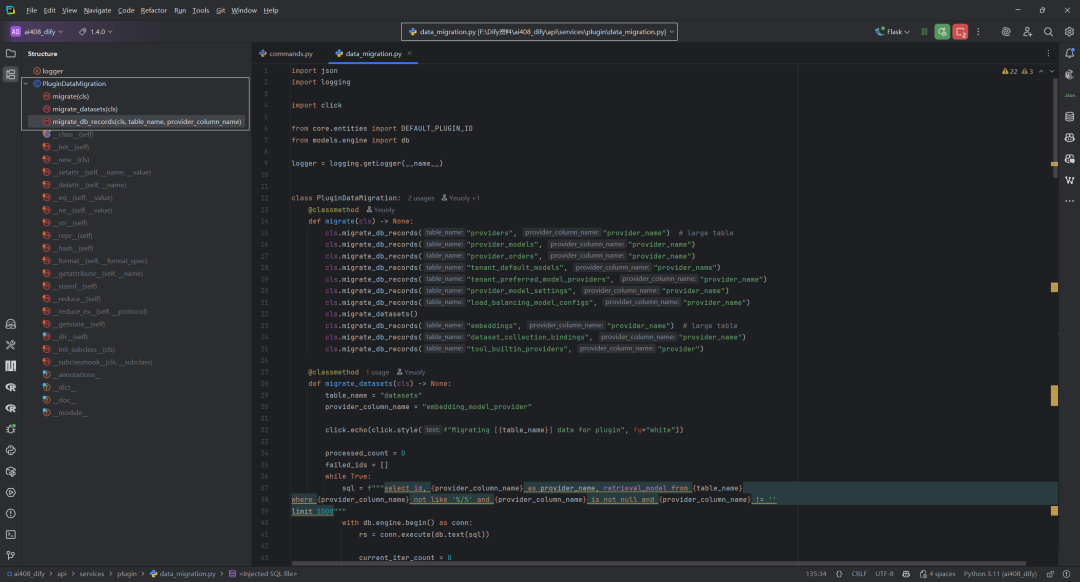
whileTrue: sql = f"""select id, {provider_column_name} as provider_name, retrieval_model from {table_name} where {provider_column_name} not like '%/%' and {provider_column_name} is not null and {provider_column_name} != '' limit 1000""" with db.engine.begin() as conn: rs = conn.execute(db.text(sql))
@classmethod defmigrate_db_records(cls, table_name: str, provider_column_name: str) -> None: click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white")) processed_count = 0 failed_ids = [] last_id = "00000000-0000-0000-0000-000000000000" whileTrue: sql = f""" SELECT id, {provider_column_name} AS provider_name FROM {table_name} WHERE {provider_column_name} NOT LIKE '%/%' AND {provider_column_name} IS NOT NULL AND {provider_column_name} != '' AND id > :last_id ORDER BY id ASC LIMIT 5000 """ params = {"last_id": last_id or""} with db.engine.begin() as conn: rs = conn.execute(db.text(sql), params) current_iter_count = 0 batch_updates = [] for i in rs: current_iter_count += 1 processed_count += 1 record_id = str(i.id) last_id = record_id provider_name = str(i.provider_name) if record_id in failed_ids: continue click.echo( click.style( f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})", fg="white", ) ) try: updated_value = f"{DEFAULT_PLUGIN_ID}/{provider_name}/{provider_name}" batch_updates.append((updated_value, record_id)) except Exception as e: failed_ids.append(record_id) click.echo( click.style( f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})", fg="red", ) ) logger.exception( f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})" ) continue if batch_updates: update_sql = f""" UPDATE {table_name} SET {provider_column_name} = :updated_value WHERE id = :record_id """ conn.execute(db.text(update_sql), [{"updated_value": u, "record_id": r} for u, r in batch_updates]) click.echo( click.style( f"[{processed_count}] Batch migrated [{len(batch_updates)}] records from [{table_name}]", fg="green", ) ) ifnot current_iter_count: break click.echo( click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green") )
1.初始化与准备
输出迁移开始信息。
初始化计数器、失败ID列表、last_id(用于分页)。
@click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white")) processed_count = 0 failed_ids = [] last_id = "00000000-0000-0000-0000-000000000000"
2.循环分页处理
构造 SQL 查询,查找 provider 字段未迁移(不含 /)的记录,按 id 升序分页(每次 5000 条)。
用 last_id 控制分页,避免遗漏或重复。
whileTrue: sql = f""" SELECT id, {provider_column_name} AS provider_name FROM {table_name} WHERE {provider_column_name} NOT LIKE '%/%' AND {provider_column_name} IS NOT NULL AND {provider_column_name} != '' AND id > :last_id ORDER BY id ASC LIMIT 5000 """ params = {"last_id": last_id or""}
3.处理每一批数据
with db.engine.begin() as conn: rs = conn.execute(db.text(sql), params) current_iter_count = 0 batch_updates = [] for i in rs: current_iter_count += 1 processed_count += 1 record_id = str(i.id) last_id = record_id provider_name = str(i.provider_name) if record_id in failed_ids: continue click.echo( click.style( f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})", fg="white", ) ) try: updated_value = f"{DEFAULT_PLUGIN_ID}/{provider_name}/{provider_name}" batch_updates.append((updated_value, record_id)) except Exception as e: failed_ids.append(record_id) click.echo( click.style( f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})", fg="red", ) ) logger.exception( f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})" ) continue
if batch_updates: update_sql = f""" UPDATE {table_name} SET {provider_column_name} = :updated_value WHERE id = :record_id """ conn.execute(db.text(update_sql), [{"updated_value": u, "record_id": r} for u, r in batch_updates]) click.echo( click.style( f"[{processed_count}] Batch migrated [{len(batch_updates)}] records from [{table_name}]", fg="green", ) )
5.终止条件
如果本批没有数据,跳出循环。
ifnot current_iter_count: break
输出迁移完成信息。
6.结束输出
click.echo( click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green") )