


6 月 30 日,百度正式开源文心大模型 4.5 系列模型,涵盖 47B、3B 激活参数的混合专家(MoE)模型,与 0.3B 参数的稠密型模型等 10 款模型,并实现预训练权重和推理代码的完全开源。
目前,文心大模型 4.5 开源系列已可在飞桨星河社区、HuggingFace 等平台下载部署使用,系列权重按照 Apache 2.0 协议开源,同时开源模型 API 服务也可在百度智能云千帆大模型平台使用。值得关注的是,此次文心大模型 4.5 系列开源后,百度实现了框架层与模型层的“双层开源”。
相关链接:
https://huggingface.co/models?other=ERNIE4.5
https://aistudio.baidu.com/modelsoverview
早在今年 2 月,百度就已预告了文心大模型 4.5 系列的推出计划,并明确将于 6 月 30 日起正式开源。
文心大模型 4.5 是百度于 2025 年 3 月 16 日发布的新一代多模态基础大模型,属于百度人工智能核心产品体系的重要升级版本。此次百度一次性推出 10 款文心大模型 4.5 系列开源模型,在独立自研模型数量占比、模型类型数量、参数丰富度、开源宽松度与可靠性等关键维度上,均处于行业领先位置。
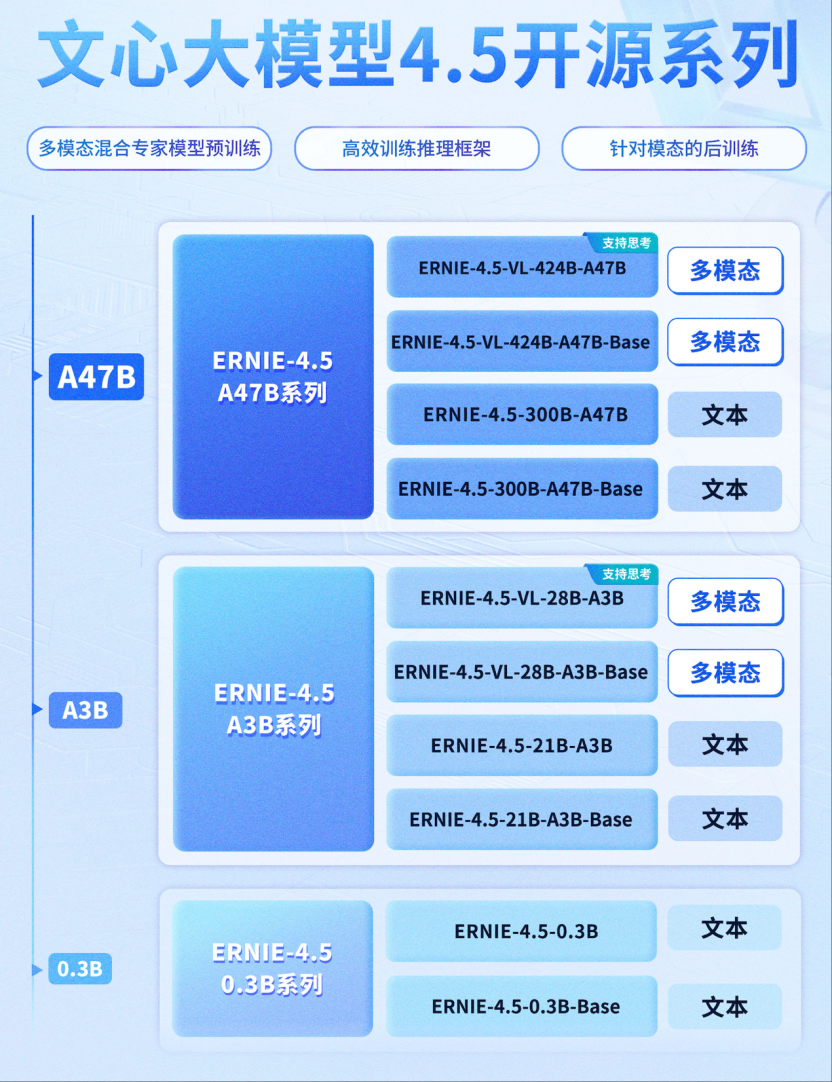
据介绍,ERNIE 4.5 型号(尤其是基于 MoE 的 A47B 和 A3B 系列)的先进功能由几项关键技术创新支撑:
-
多模态异构 MoE 预训练。基于文本与视觉模态进行训练,更精准捕捉多模态信息的细微差异,从而提升文本理解生成、图像理解及跨模态推理等任务性能。为避免模态间学习相互干扰,百度团队设计了异构 MoE 结构,并引入了模态隔离路由机制,采用路由正交损失与多模态 token 均衡损失双重优化。这些架构设计确保两种模态特征均得到高效表征,从而在训练过程中实现相互强化。
-
可扩展高效的基础设施。百度团队提出了一种新异构混合并行和分层负载均衡策略,以实现 ERNIE 4.5 模型的高效训练。通过采用节点内专家并行、内存优化流水线调度、FP8 混合精度训练和细粒度重计算方法,显著提升预训练吞吐量。在推理方面,提出了多专家并行协作方法和卷积码量化算法,以实现 4-bit/2-bit 无损量化。此外,团队还引入了具有动态角色切换的 PD 分解,以有效利用资源,从而提升 ERNIE 4.5 MoE 模型的推理性能。基于 PaddlePaddle 构建的 ERNIE 4.5 可在各种硬件平台上提供高性能推理。
-
针对特定模态的后训练。为了满足实际应用的多样化需求,团队针对特定模态对预训练模型的变体进行了微调,并针对通用语言理解和生成进行了优化。VLM 专注于视觉语言理解,并支持思考和非思考模式。每个模型都结合使用了监督微调 (SFT) 、 直接偏好优化 (DPO) 或一种名为统一偏好优化 (UPO) 的改进强化学习方法进行后训练。
此外,文心大模型 4.5 开源系列均使用飞桨深度学习框架进行高效训练、推理和部署。在大语言模型的预训练中,模型 FLOPs 利用率(MFU)达到 47%。实验结果显示,其系列模型在多个文本和多模态基准测试中达到 SOTA 水平,尤其在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果突出。
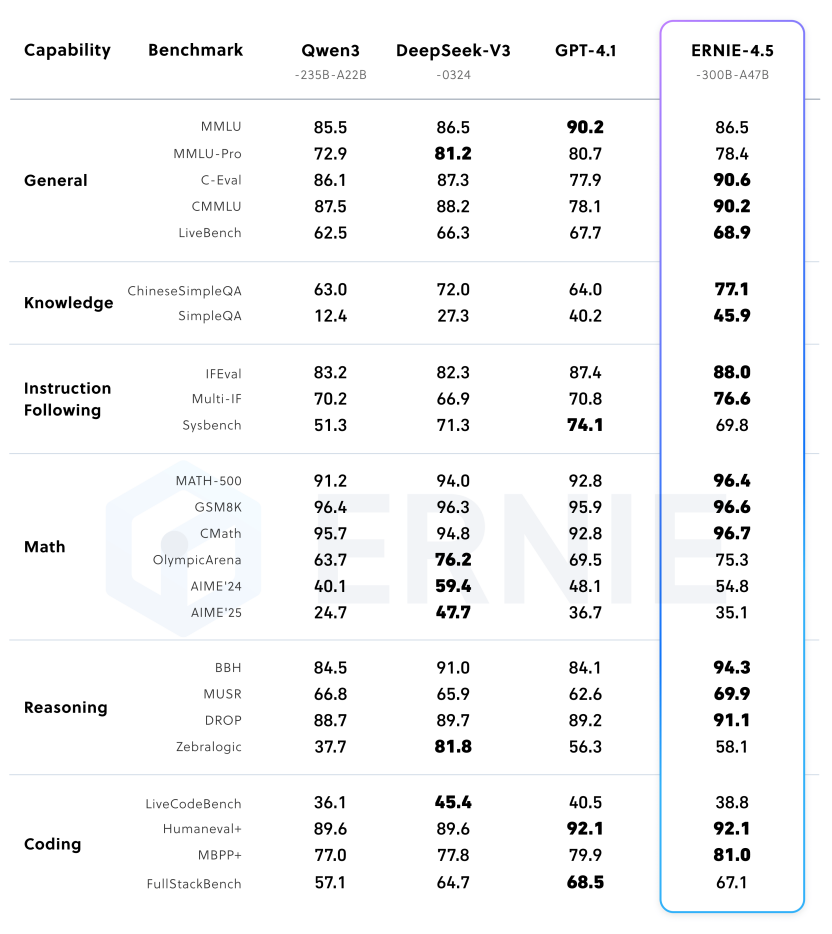
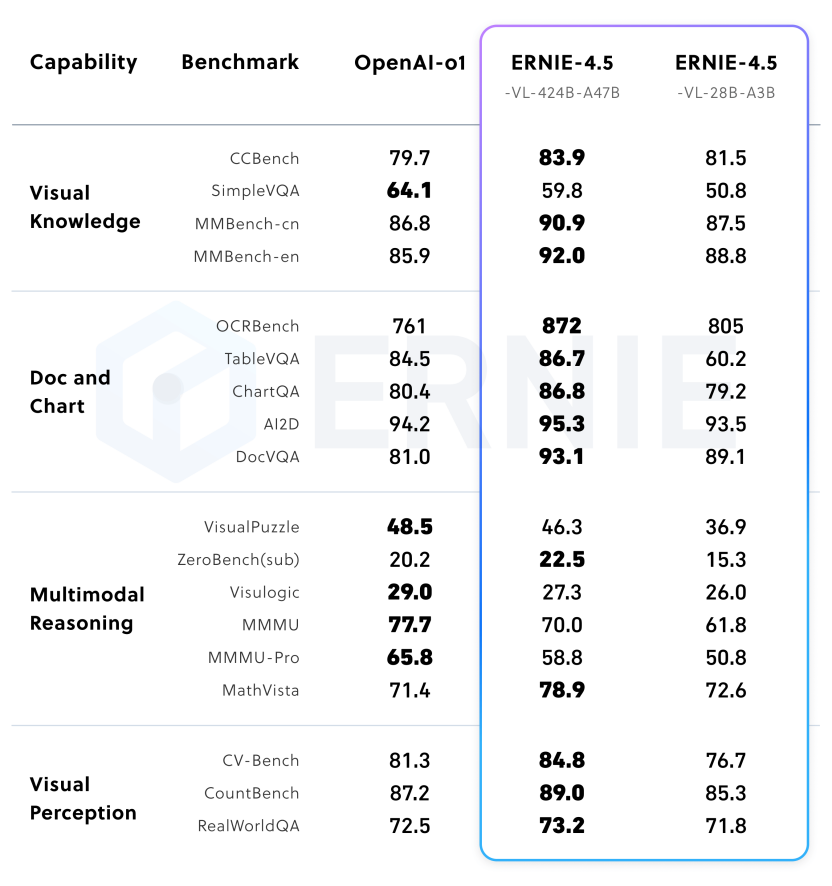
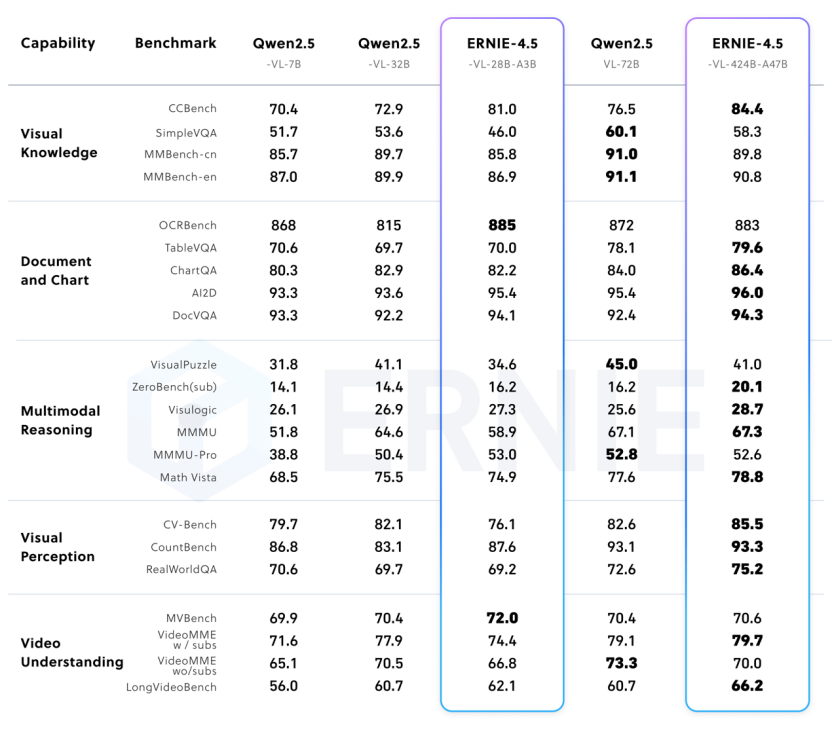
百度表示,在文本模型方面,文心大模型 4.5 开源系列基础能力强、事实准确性高、指令遵循能力强、推理和编程能力出色,在多个主流基准评测中超越 DeepSeek-V3、Qwen3 等模型。在多模态模型方面,文心大模型 4.5 开源系列拥有卓越的视觉感知能力,同时精通丰富视觉常识,并实现了思考与非思考统一,在视觉常识、多模态推理、视觉感知等主流的多模态大模型评测中优于闭源的 OpenAI o1。此外,在轻量模型上,文心 4.5-21B-A3B-Base 文本模型效果与同量级的 Qwen3 相当,文心 4.5-VL-28B-A3B 多模态模型也是目前同量级最好的多模态开源模型,甚至与更大参数模型 Qwen2.5-VL-32B 不相上下。
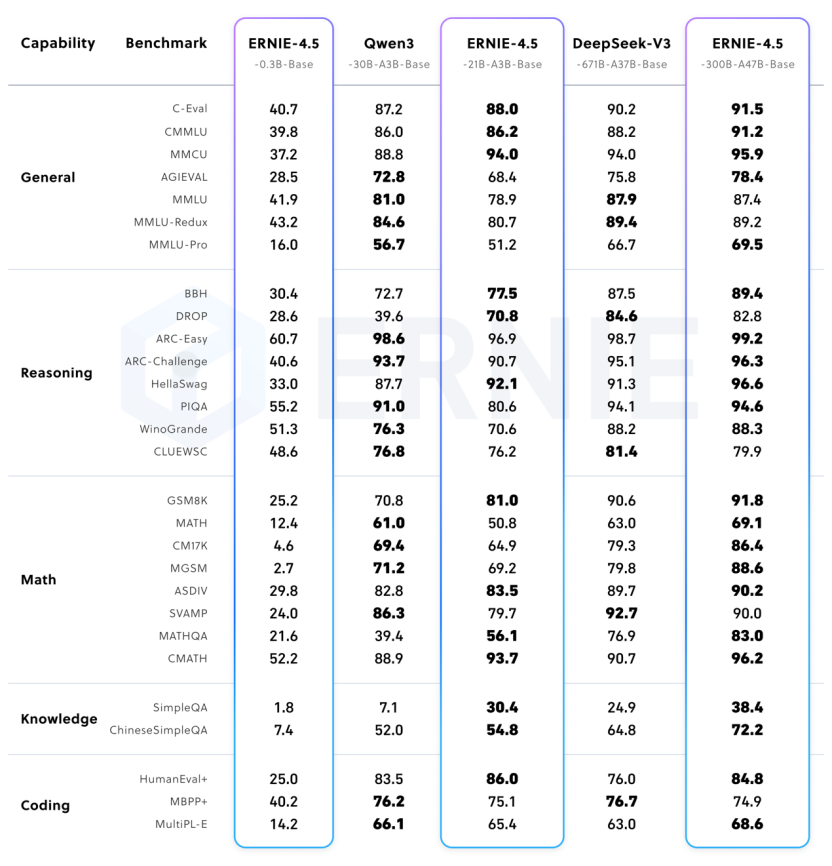
文心 4.5 预训练模型在主流基准测试中表现
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
(文:AI前线)