7B小模型超越DeepSeek-R1:模仿人类教师,弱模型也能教出强推理LLM Transformer作者团队

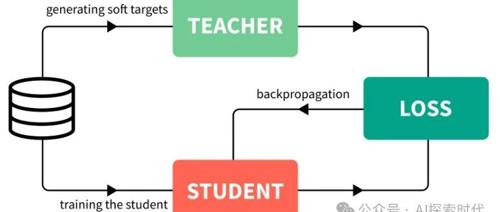
Sanaka AI提出的新方法通过让教师模型输出清晰解释来改进教学效果,其7B小模型在传授推理技能方面超越了671B的DeepSeek-R1。这种方法不仅有效还经济高效,并且能与传统强化学习技术结合使用。
Sanaka AI提出的新方法通过让教师模型输出清晰解释来改进教学效果,其7B小模型在传授推理技能方面超越了671B的DeepSeek-R1。这种方法不仅有效还经济高效,并且能与传统强化学习技术结合使用。

Meta发布Llama 4系列模型,参数规模达到109B至288B不等,支持原生多模态和12种语言,性能强大且应用前景广阔。不过中文支持仍需改进,但其在编码、推理、多语言处理等方面表现出色。

苹果研究人员发现,多次‘蒸馏’更具优势。当教师模型性能比大小更重要时,选择与学生模型相近大小的教师模型可优化学习效果。这一研究成果有望为业界提供更高效、低成本的小模型训练方案。
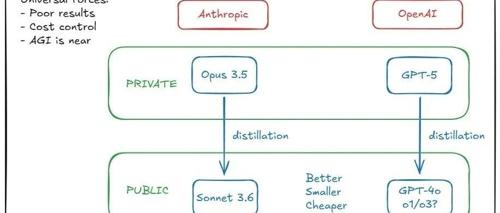
OpenAI和Anthropic秘密开启了递归自我改进行动。OpenAI可能开发了GPT-5但选择内部保留;Anthropic的Claude Opus 3.5未发布或用于生成训练数据。专家认为未来O4/O5将能自动化研发。