🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
AI 圈周末炸锅,Meta 毫无预兆地扔出了 Llama 4 系列,直接抢回开源第一宝座。
这次 Llama 家族一口气来了三款 (最后一款超大杯还在路上),全是基于 MoE 架构,还首次原生支持多模态——Llama 终于“长眼睛”了。
支持 12 种语言, Apache 2.0 开源。
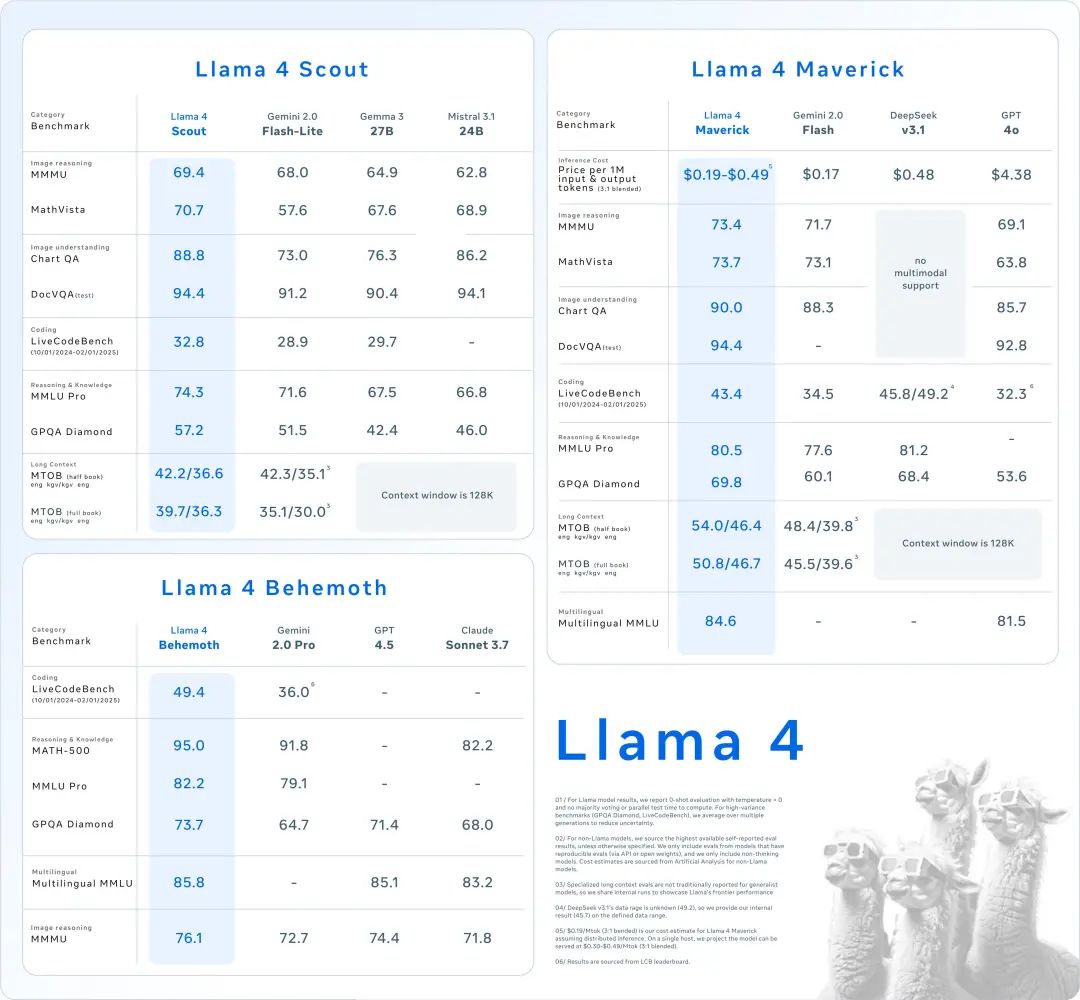
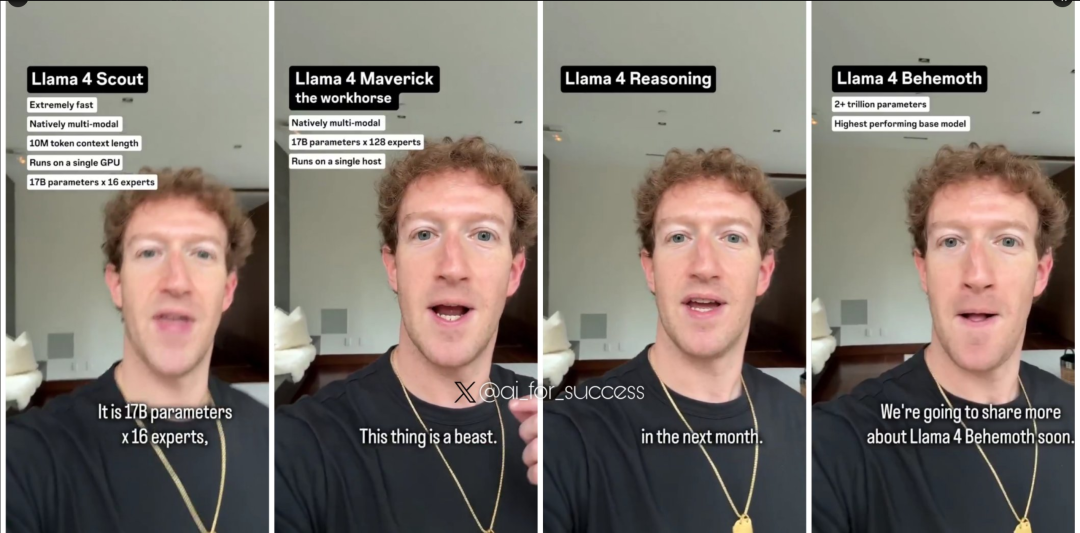
中杯Llama 4 Scout (侦察兵): 109B 参数 (17B 活跃),16 专家。长文逆天,主打 1000 万超长上下文窗口!相当于可以处理20+小时的视频。
性能 PK 掉 Gemma 3、Gemini 2.0 Flash-Lite、Mistral 3.1。小模型卷王。一张 H100 (Int4 量化)就能跑。
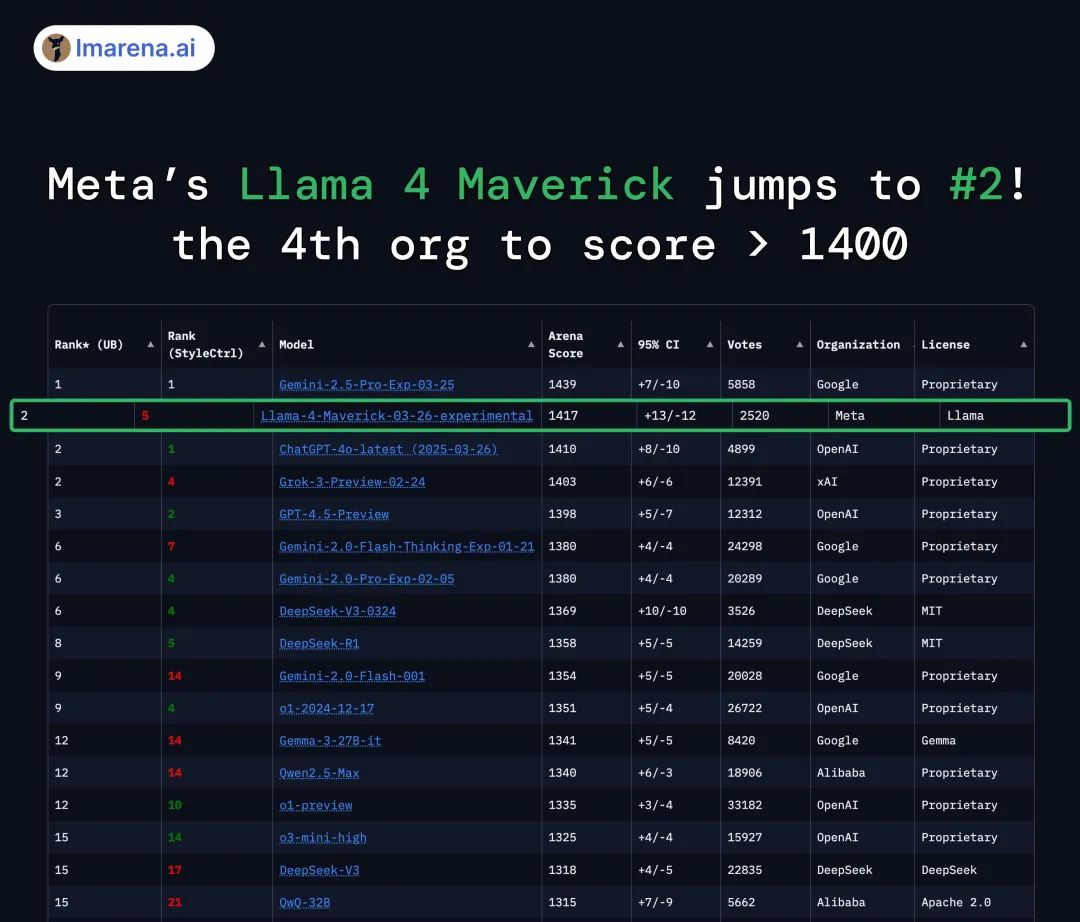
大杯Llama 4 Maverick (独行侠): 400B 参数 (17B 活跃),128 专家,100 万上下文。直接在 LMSYS 榜单冲到第二,仅次于闭源 Gemini 2.5 Pro。
这是第四个突破 1400 分的模型,开源模型里更是直接登顶,超过了 DeepSeek。 而且在各种硬核任务像困难提示词、编程、数学、创意写作上,Llama 4 Maverick 都是第一,比自家的 Llama 3 提升巨大。
拳打 GPT-4o/Gemini 2.0 Flash,代码能力对标 DeepSeek-V3 但参数减半!还是一张 H100 就能跑。
另外两个模型即将推出。- Llama-4 推理模型将于下个月推出。- Llama 4 Behemoth 正在训练中。
▼ LLAMA-4细节一图搞定
超大杯Llama 4 Behemoth (巨兽): 2 万亿参数 (288B 活跃),16 专家。还在训练,已经在STEM 基准上干掉了 GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Pro。
这是 Maverick 的“教师模型”。上面两个都是从它这“蒸馏”出来的,目标是干翻 GPT-4.5 这些顶级闭源模型。
Meta 的 GenAI 负责人 Ahmad Al-Dahle 直接表示,Llama 4 代表了 Meta 对开源 AI 的长期承诺,他们坚信开放系统才能搞出最好的模型。
连谷歌 CEO 劈柴都忍不住点赞,说 AI 世界真是永不无聊。
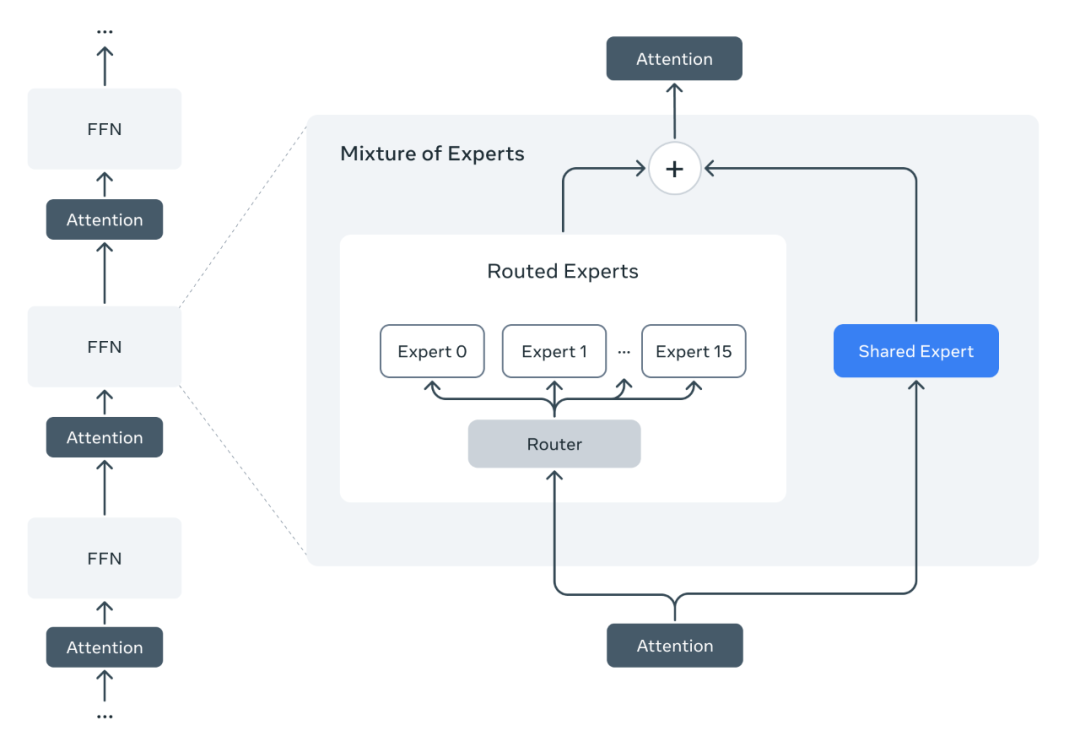
原生多模态设计,文本和视觉 token 早期融合,用大量无标注数据联合预训练。
架构革新: 首次上 MoE (提效降本), Maverick 模型用 MoE 后,虽然总参数 4000 亿,但激活参数只有 170 亿,推理成本和延迟都大大降低。
升级了视觉编码器;搞了个 MetaP 训练方法 优化超参数;支持 100 多种语言;
预训练 Llama 4 Behemoth 模型时下血本: 30 万亿+ Token 数据集 (Llama 3 两倍),FP8 精度训练,32K 个 GPU 硬怼。
为了提升长上下文能力,Llama 4 还搞了中期训练,Scout 的超长上下
文得益于 新 iRoPE 架构 (无位置嵌入,利于长文)。
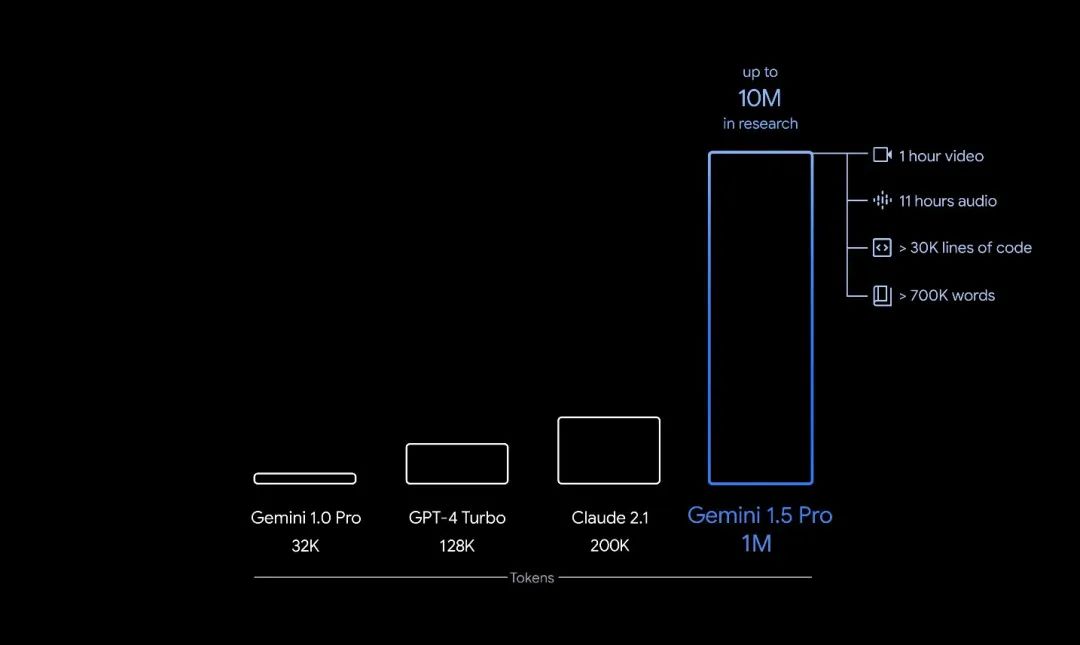
直接解锁了 1000 万 token 上下文,文档代码随便塞,记忆、个性化和多模态应用。
不过,虽然 10M 上下文听起来很疯狂,但这只是 Magic AI 计划在某个时候实现真正LLM上下文长度的十分之一(100M):
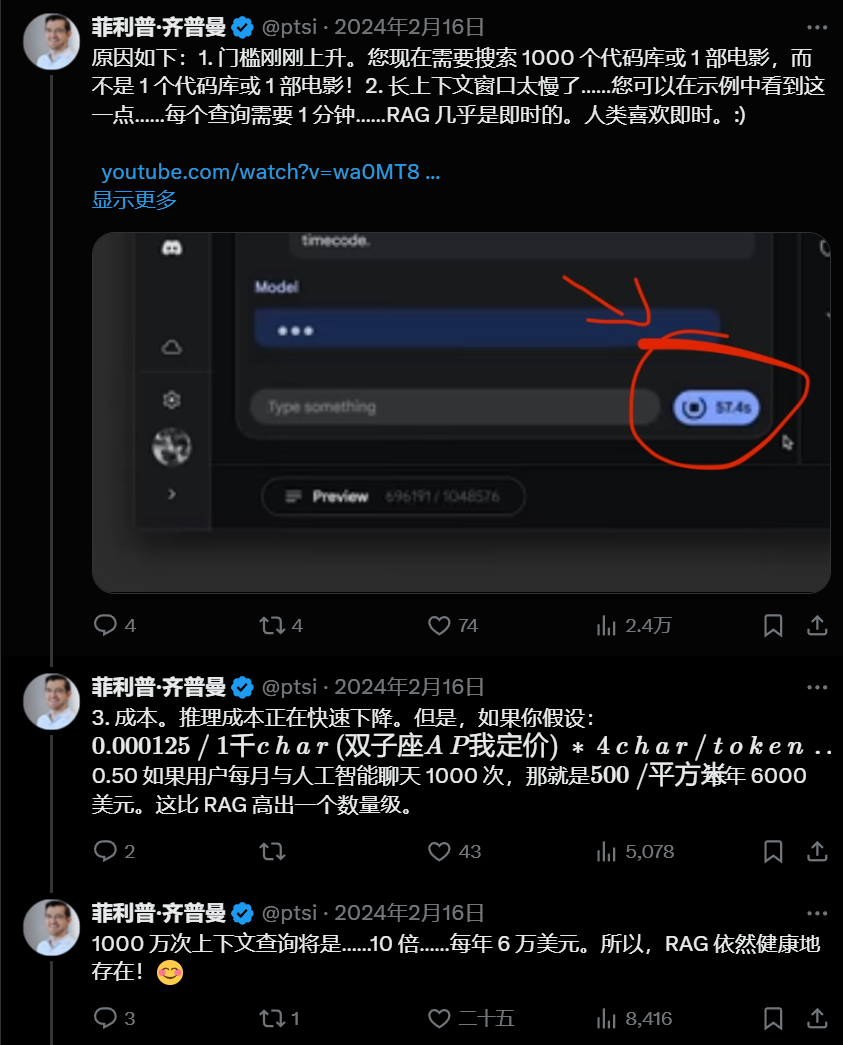
Llama 4 这 1000 万上下文一出,直接有人喊出 “RAG 已死”。
核心意思是,有了这么长的上下文,再加上各种工具 (比如搜索),还要 RAG 干啥?成本似乎也不是大问题了。
一个论点是“Garbage in garbage out”——上下文太长,塞一堆不相关的垃圾信息进去,LLM 反而会懵逼,输出质量更差。
RAG 能精准筛选最相关的信息喂给模型,还能有效减少长上下文可能带来的幻觉问题。更别提实时数据、私有数据这些场景,RAG 还是刚需。
也有人觉得,就算上下文再长,精准理解用户偏好、快速捞出个性化数据这块,还得靠 RAG 和向量数据库。
还有人更实际,说除非 token 价格打骨折,否则 RAG 就死不了。
更有人认为,就算 RAG 整体过时,但 “检索” 这个动作本身还是有价值的,尤其是在你想看原始资料的时候。
还有人看得更远,觉得在这种“too fast”的迭代速度下,除了有基建护城河的巨头(megacaps),很多工具(比如被点名的 Cursor)可能很快就会“become worthless”,最终一切都会被大厂掌控。
还有新的后训练流程 (轻量 SFT > 在线 RL > 轻量 DPO),以及从 Behemoth 蒸馏 到 Maverick 的技术。
总的来说,Llama 4 Maverick 性能很强,同等规模模型里几乎无敌,编码、推理、多语言、长上下文、图像理解都非常出色。
Llama 4 Scout 也很能打,1000 万 token 上下文更是亮点。
Llama 4 Behemoth 作为教师模型,性能天花板更高。 Llama 4 全系列都支持原生多模态和 12 种语言,应用前景广阔。
不过也有网友表示,Llama系列在中文支持上一直不是很好。
Llama 4 Scout 和 Llama 4 Maverick 现已开放下载,地址:
llama.com:https://www.llama.com/llama-downloads/
Hugging Face 地址:https://huggingface.co/meta-llama
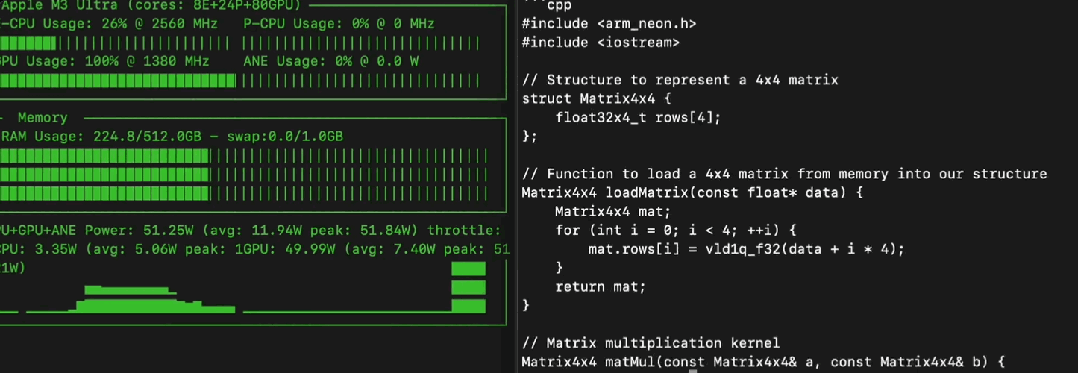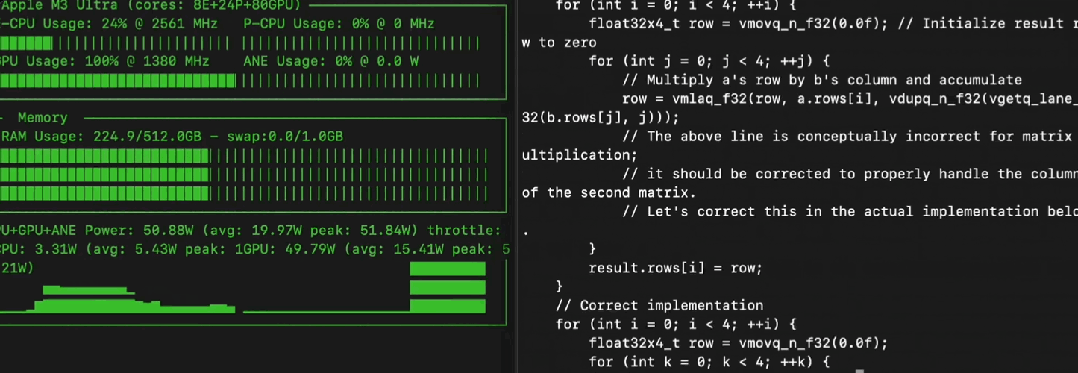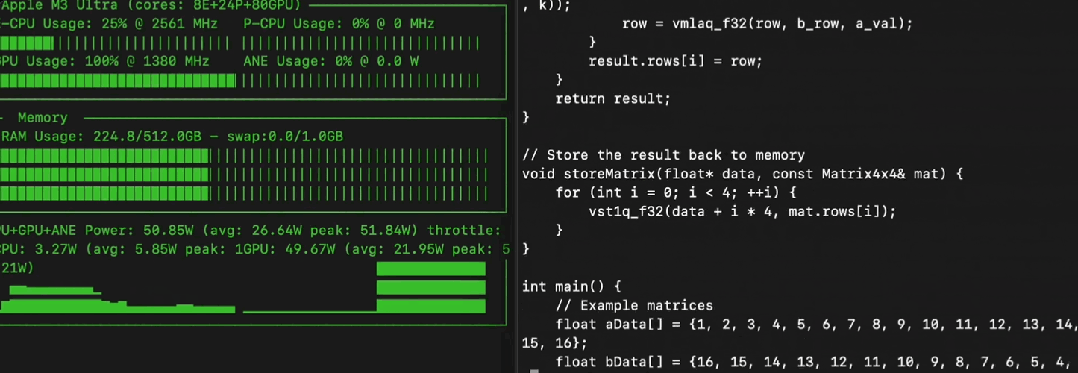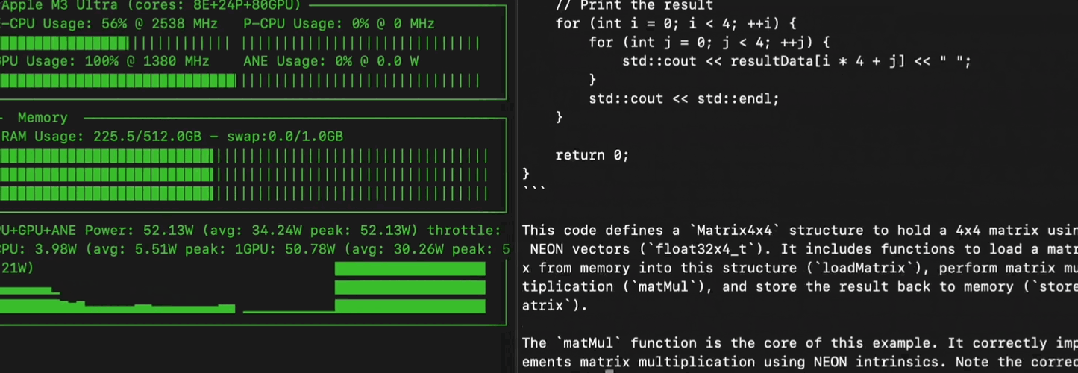
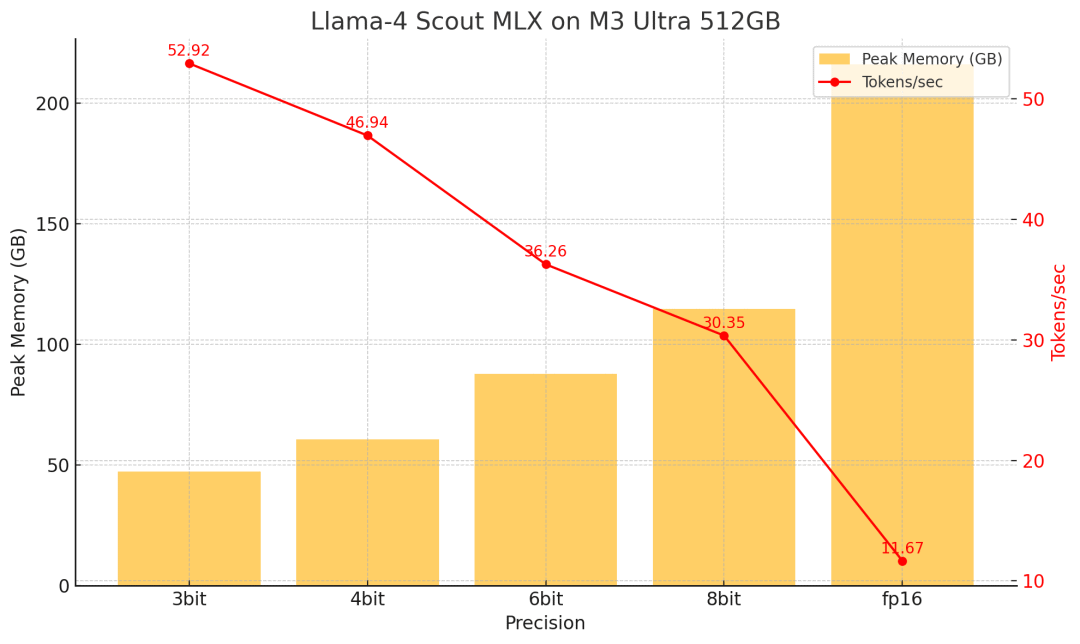
模型刚放出来,Mac 用户这边立马就有人秀肌肉了。
有网友直接在 M3 Ultra (512GB 内存) 上用苹果自家的 MLX 框架,把 Llama 4 Maverick 的 Q4 量化版 (大概 225GB) 跑出了 50 token/s 的惊人速度,功耗才 50 瓦,又快又省电。
以下,本号知识星球(汇集ALL订阅频道合集和其他):
星球里可获取更多AI绘画实践以及其他AI实践:
本号连载过许多MCP的文章,从概念到实践再到自己构建:
MCP是什么:Windsurf Wave3:MCP协议让AI直接读取控制台错误,自动化网页调试不用复制粘贴了!Tab智能跳转、Turbo模式。
MCP怎么配置、报错解决:Windows下MCP报错的救星来了,1分钟教你完美解决Cursor配置问题。
MCP实践:Cursor + MCP:效率狂飙!一键克隆网站、自动调试错误,社区:每个人都在谈论MCP!
最新MCP托管平台:让Cursor秒变数据库专家,一键对接Github,开发效率暴增!
Blender + MCP 从入门到实践:安装、配置、插件、渲染与快捷键一文搞定!
比Playwright更高效!BrowserTools MCP 让Cursor直接控制当前浏览器,AI调试+SEO审计效率狂飙!
手把手教你配置BrowserTools MCP,Windows 和 Mac全流程,关键命令别忽略。
2分钟构建自己的MCP服务器,从算数到 Firecrawl MCP(手动挡 + AI档)
太简单了!Cline官方定义MCP开发流程,聊天式开发,让MCP搭建不再复杂。
微软发布 Playwright MCP 正式版。
OpenAI 官宣拥抱 MCP,Agents SDK已支持,桌面版即将跟进!
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
点这里👇关注我,记得标星哦~
(文:AI进修生)