
字节跳动发了个新模型:BAGEL-7B-MoT
这是一个混合专家多模态模型,基于Qwen2.5-7B-Instruct和siglip-so400m-14-980-flash-attn2-navit模型微调,并使用FLUX.1-schnell VAE模型,支持视觉理解、文本到图像生成及图像编辑。
这是一个混合专家多模态模型,基于Qwen2.5-7B-Instruct和siglip-so400m-14-980-flash-attn2-navit模型微调,并使用FLUX.1-schnell VAE模型,支持视觉理解、文本到图像生成及图像编辑。

阿里开源的Qwen2.5系列训练数据规模达到18万亿token,远超其他模型。然而,这带来幻象问题的风险促使RAG技术及企业专有知识数据的价值提升,强调了数据采集、标注和管理的重要性。政策层面,《关于促进数据标注产业高质量发展的实施意见》发布,进一步推动数据标注产业发展。《标准》旨在解决数据标注中的合规问题,提高行业规范化发展水平。
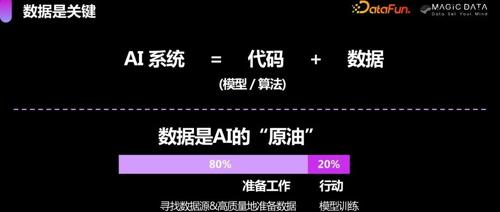
阿里开源的Qwen2.5系列训练数据规模达18万亿 token,推动AI大模型发展。但大规模训练带来幻象问题,RAG技术及工业场景应用以数据为中心成为趋势。国家和行业正积极推进数据标注产业发展规范,提升数据标注行业的合规能力。

印度初创公司Ziroh Labs开发了一套名为Kompact AI的新系统,该系统无需使用昂贵的GPU芯片就能运行大型AI模型。

Spark-TTS 是一个先进的文本到语音系统,利用大型语言模型实现高度准确和自然的声音合成。它简洁高效,支持零样本语音克隆及双语支持,具备可控语音生成功能。

2025年4月1日,北京天气晴。文章介绍了R1进展中的两个工作,一是研究多种基础模型预训练特性的影响;二是将GRPO-RL强化用于Agent的UI动作预测,数据和奖励函数设计有趣。研究发现Qwen2.5模型在不使用模板的情况下有强大的推理能力,但模板会破坏数学解题能力。此外,文章还讨论了强化学习在图形用户界面(GUI)动作预测中的应用。
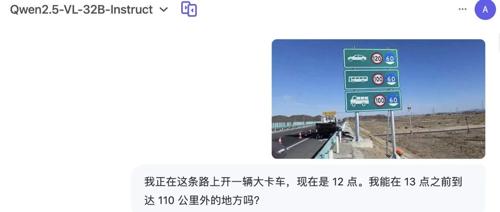
阿里云千问团队发布了Qwen2.5-VL-32B-Instruct模型。该模型在多个方面实现了重要突破:优化了模型规模、提升了性能,并在视觉理解和数学推理等方面取得了显著进步。
阿里国际站总裁张阔透露,Accio企业用户已超百万。接入Qwen2.5等先进推理模型后,让阿里国际站在AI外贸领域引发关注。海外买家在采购时信息类搜索量是商品类的10倍。目前Accio的用户规模超百万,且已有超过10万中小企业使用AI工具做外贸。张阔称AI能协助人完成外贸经营中的绝大部分环节,将提高转化率、客户互动和商品管理。

