

今天是2025年4月1日,星期二,北京,天气晴。
今天我们来继续回到R1进展,两个工作,一个是基于多种基础模型以了解预训练特性如何影响RL性能的工作,有些新发现。
另一个是将GRPO–RL强化用于Agent的UI动作预测,数据跟奖励函数设计有意思,可借鉴。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、R1–Zero路线的组合实验新发现
继续来看大模型可解释性,最近的工作 《Understanding R1-Zero-Like Training: A Critical Perspective》(https://arxiv.org/abs/2503.20783,https://github.com/sail-sg/understand-r1-zero) ,结论很有趣,研究了多种基础模型,以了解预训练特性如何影响RL性能。
模型侧,包括DeepSeek-V3-Base和Qwen2.5模型家族,即Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-7B、Llama-3.1-8B、DeepSeek-Math-7B和DeepSeek-V3-Base-685B等模型。
实验侧,包括使用不同的模板(R1模板和Qwen-Math模板)和不同的RL算法(GRPO和Dr. GRPO)。
有几个有趣的结论:

1、DeepSeek-V3-Base已经表现出“Aha moment”,而Qwen2.5模型在不使用模板的情况下显示出强大的推理能力,表明可能存在预训练偏差,也就是它可能在预训练时使用了拼接的问题-答案文本。即Qwen2.5模型在预训练阶段使用了某种形式的提示或数据结构,例如将问题和答案连接成文本。这种预训练方式使得模型在没有额外模板的情况下也能更好地理解和回答问题。更直白点说,就是:Qwen2.5模型可能在预训练时接触了大量的问答对数据,这些数据本身就是以问题和答案的形式呈现的,因此模型在不需要额外模板的情况下就能自然地生成回答。
2、使用模板会破坏基础模型的数学解题能力,从而在RL重建这些能力之前需要更加谨慎地评估纯RL带来的巨大收益。模型-模板不匹配可能会在RL重建之前破坏推理能力。
3、尽管自我反思行为在训练中出现得更频繁,但这些行为并不一定意味着更高的推理准确性,提示我们在评估模型性能时需要考虑这一点。
4、群体相对策略优化(GRPO)存在优化偏差,该偏差会在训练期间人为地增加响应长度(尤其是针对不正确的输出),体现在两个方面,一个是响应级长度偏差,由于在计算优势时除以响应长度,导致较短响应的梯度更新更大,而较长响应则相反。这意味着模型倾向于生成较短的正确答案,而对较长但错误的答案惩罚较小。另一个是问题级难度偏差,由于在计算优势时除以问题标准差,导致较容易或较难问题的权重不同。较容易的问题(标准差较小)在优化过程中被赋予更高的权重,而较难的问题则被赋予较低的权重。这种偏差可能导致模型在优化过程中对不同难度的问题表现出不一致的行为。
5、数学预训练可以提高Llama-3.2-3B模型的RL上限。
二、R1用来做用户界面GUI动作预测
看第二个工作,《UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning》(https://arxiv.org/pdf/2503.21620,https://github.com/lll6gg/UI-R1),基于规则的RL如何增强多模态大模型(MLLM)对图形用户界面(GUI)动作预测任务的推理能力。
也看看数据和奖励函数上的设计。
在数据上,采用三阶段数据选择方法,从ScreenSpot和ANDROIDCONTROL数据集中选择了136个高质量的训练样本,涵盖五种常见的动作类型。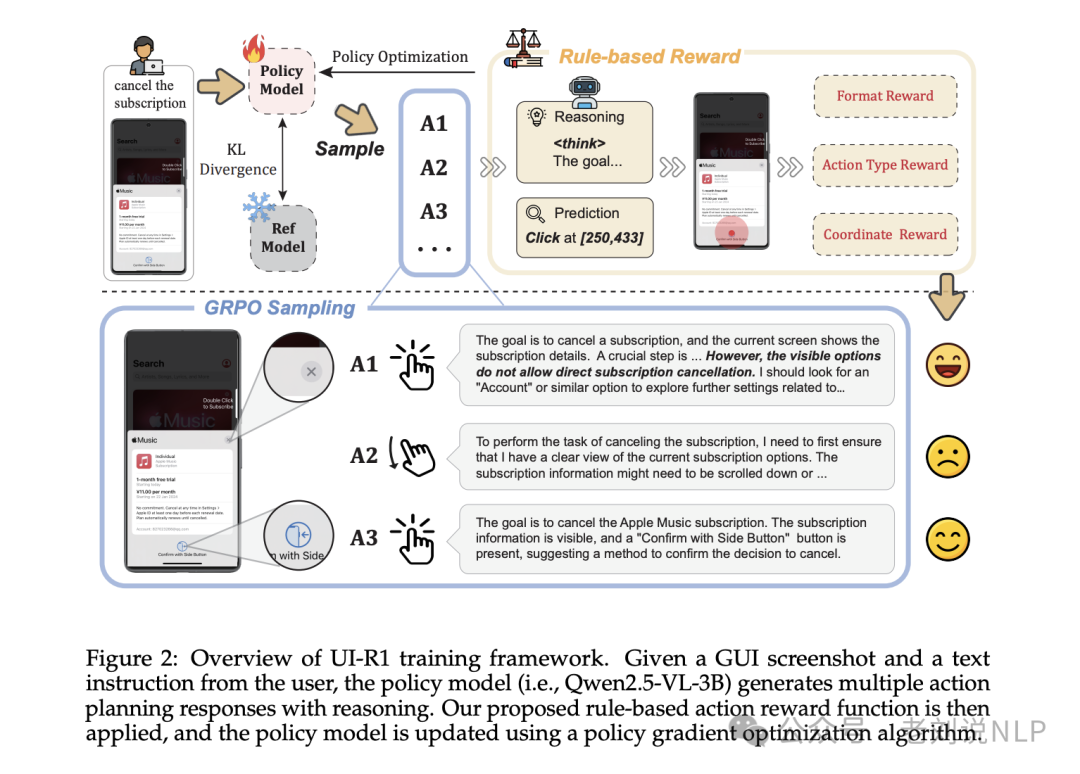
一个是质量筛选,首先,使用ScreenSpot的移动子集作为初始数据集,因为它提供了干净且对齐良好的任务元素配对注释。对于其他动作类型,从ANDROIDCONTROL中随机选择1K个样本。由于ANDROIDCONTROL的元素标注未经过滤且可能存在对齐问题,因此排除了点击动作步骤,仅保留了其他动作类型。
一个是难度筛选,通过评估Qwen2.5-VL-3B在每个任务指令上的模型性能,识别出模型输出与真实值不匹配的“困难”样本,并将其保留。
一个是多样性筛选,确保所选样本在不同动作类型(如滚动、返回、打开应用、输入文本)和元素类型(如图标、文本)上具有多样性。排除ANDROIDCONTROL中的罕见动作(如等待和长按)。
在强化学习策略方面,引入了统一的基于规则的行动奖励,通过基于策略的算法(如群体相对策略优化(GRPO))来实现模型优化,奖励函数包括动作类型奖励、动作参数奖励和常用的格式奖励。
一个是动作类型奖励,比较预测的动作类型和真实动作类型,若匹配则奖励1,否则奖励0。
一个是坐标准确性奖励,计算预测坐标和真实边界框之间的IoU,若在框内则奖励1,否则奖励0。
一个是格式奖励,确保模型的预测结果遵循HTML标签格式,使用表示推理过程,<answer>表示最终答案。
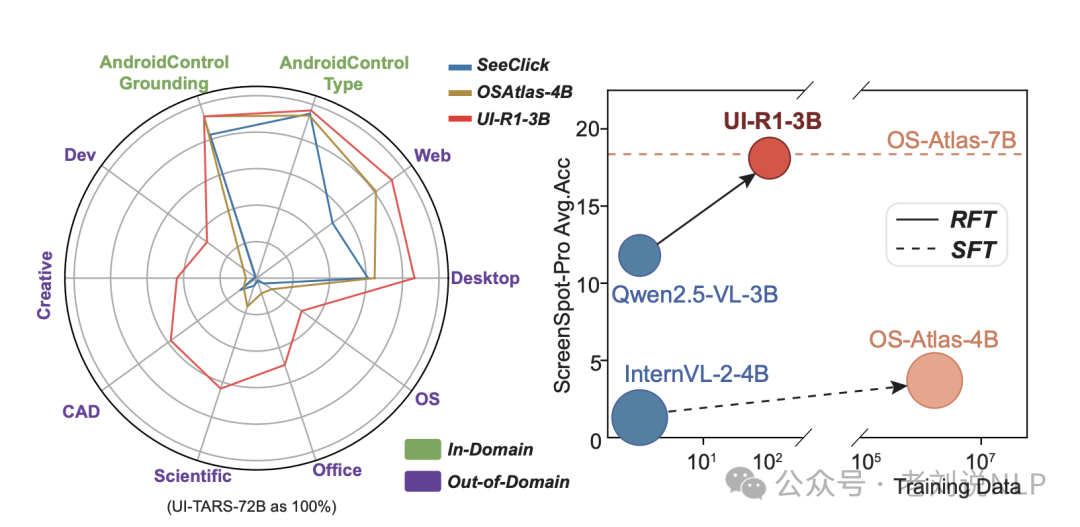
做了两个对比模型,一个是强化模型,将Qwen2.5-VL-3B模型在选定的三阶段数据上进行基于规则的RL训练,命名为UI-R1-3B。一个是微调模型,使用整个ScreenSpot移动集对基模型进行监督微调,命名为Qwen2.5-VL-3B*。
结论就是强化比微调好,很常见的结论。
参考文献
1、https://arxiv.org/pdf/2503.22458
2、https://arxiv.org/abs/2503.20783
(文:老刘说NLP)