
R1–Zero强化学习路线新发现及R1思路用于GUI Agent动作预测方案

2025年4月1日,北京天气晴。文章介绍了R1进展中的两个工作,一是研究多种基础模型预训练特性的影响;二是将GRPO-RL强化用于Agent的UI动作预测,数据和奖励函数设计有趣。研究发现Qwen2.5模型在不使用模板的情况下有强大的推理能力,但模板会破坏数学解题能力。此外,文章还讨论了强化学习在图形用户界面(GUI)动作预测中的应用。
2025年4月1日,北京天气晴。文章介绍了R1进展中的两个工作,一是研究多种基础模型预训练特性的影响;二是将GRPO-RL强化用于Agent的UI动作预测,数据和奖励函数设计有趣。研究发现Qwen2.5模型在不使用模板的情况下有强大的推理能力,但模板会破坏数学解题能力。此外,文章还讨论了强化学习在图形用户界面(GUI)动作预测中的应用。
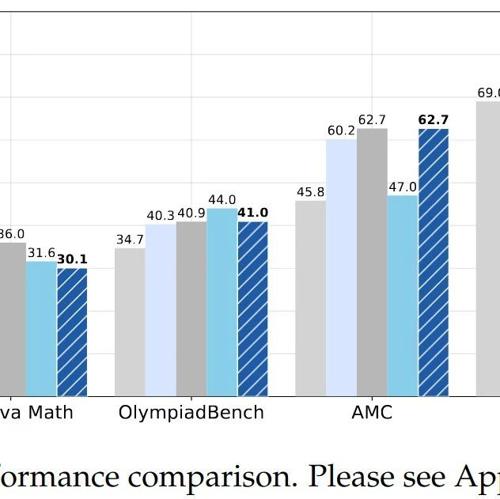
深入剖析R1-Zero训练方法,发现其已展现‘灵光一现’现象,并提出Dr. GRPO算法优化强化学习过程。仅用8×A100 GPU在27小时内实现SOTA性能。
DeepSeek AI 发布全新开源大模型 DeepSeek-V3-Base,完成率提升48.4%,在多语言编程领域超越Claude 3.5 Sonnet。该模型拥有256位顶尖专家的智库架构,通过MoE混合专家实现「专才专用」,支持上下文长度最高可达8K。

DeepSeek AI开源最新混合专家语言模型DeepSeek-V3-Base,性能优于多个竞品模型,编程能力大幅提升。