
Kyutai TTS:实时文本转语音

法国AI研究机构Kyutai Labs开源最新文本转语音技术Kyutai TTS,支持实时交互场景,性能卓越,已在GitHub和Hugging Face开放源码与模型权重。
法国AI研究机构Kyutai Labs开源最新文本转语音技术Kyutai TTS,支持实时交互场景,性能卓越,已在GitHub和Hugging Face开放源码与模型权重。
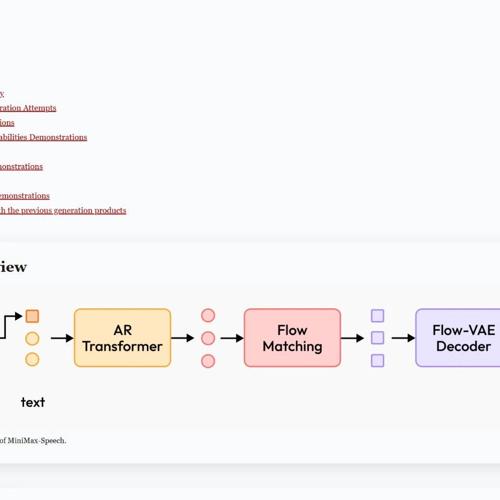
MiniMax发布的新模型MiniMax-Speech通过可学习的说话人编码器和Flow-VAE架构提高了文本转语音的质量与保真度,在零样本情况下实现了跨语言合成,多项测试中表现优异。

Muyan-TTS 是一款专为播客场景设计的开源文本转语音(TTS)模型,具有超低延迟生成能力、支持自定义说话人及长文本连续合成等特性。主要特点包括快速生成、说话人适配和离线部署友好。
2025年3月,OpenAI发布新一代音频模型API,包括改进的语音转文本和文本转语音模型。新模型在准确性和噪声消除方面表现出色,并提供更强的可控性定制选项。开发者可通过API和集成的Agent SDK轻松访问这些功能。
OpenAI发布全新一代音频模型,包括语音转文本和文本转语音功能。gpt-4o-transcribe单词错误率显著降低,gpt-4o-mini-tts支持可引导性合成。定价分别为每分钟0.006美元与0.015美元。
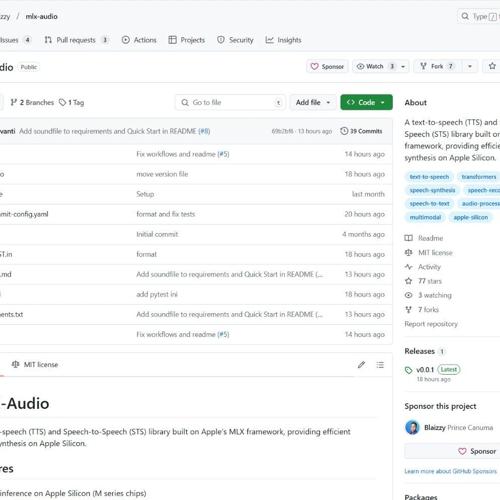
基于 Apple 的 MLX 框架构建的文本转语音 (TTS) 和语音转语音 (STS) 库,在 Apple Silicon 上提供高效支持,涵盖多语言、自定义选项和量化技术。

Zyphra 发布了具有高保真语音克隆功能的新文本转语音(TTS)模型 Zonos-v0.1 beta,该模型基于 Transformer 和混合架构进行训练,并提供对语速、情感和音频质量的灵活控制。

新智元报道
编辑:LRS
【新智元导读】
Meta最近开源了一个7B尺寸的Spirit LM的多模态

