
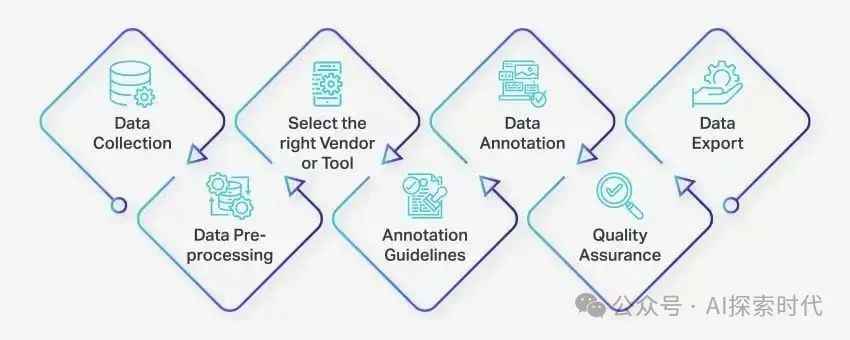
大力出奇迹造就了预训练大模型的成功。这里的大力除了把模型参数量调大外,更为重要的是用于训练它们的大量和高质量的数据。
阿里开源的 Qwen2.5 系列的训练数据规模达到 18 万亿 token,是目前开源模型中训练数据量最大的之一。DeepSeek-V3 的训练数据规模为 14.8 万亿 token,GPT-4 的训练数据规模约为 13 万亿 token,此外,OpenAI 还使用了来自 ScaleAI 和内部标注的 数百万行指令微调数据 来优化模型性能。

图1. 来源于DataFunTalk
但最大的问题是基于开源数据的训练无法避免幻象问题的产生,因此RAG技术显得更为重要,各行各业专有知识数据的价值飙升,而工业场景应用也从模型为中心转变到以数据为中心。这预示着针对企业专有知识数据的采集、标注、训练将成为生产经营的刚需。随着AI大模型普及,企业专有数据价值凸显。

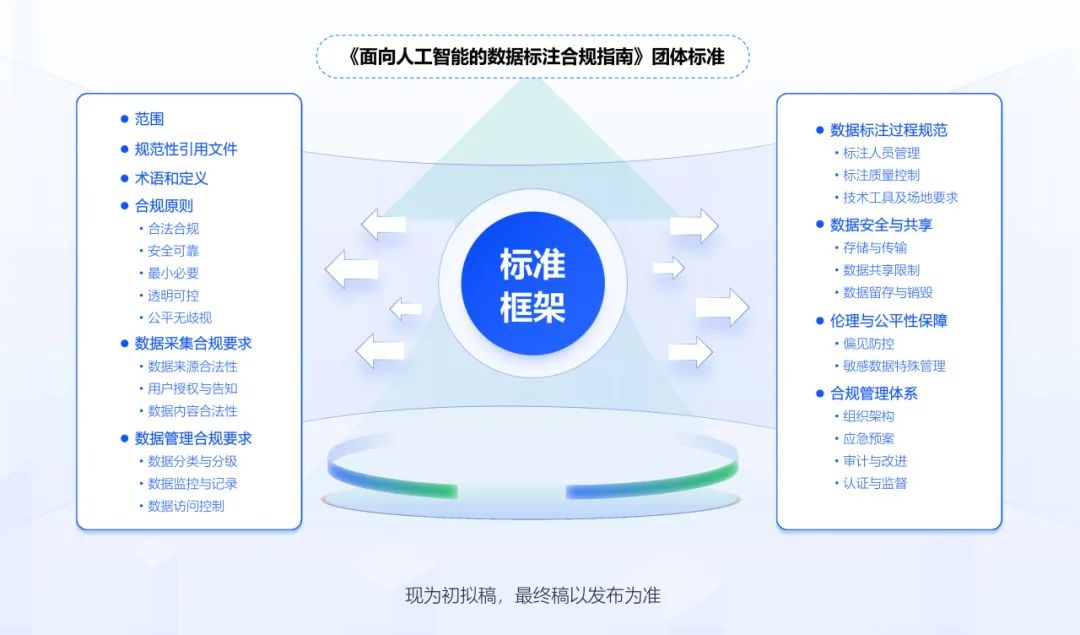
为提升数据标注行业规范化发展,智合标准中心正式启动《面向人工智能的数据标注合规指南》团体标准研制(以下简称“《标准》”)。现邀请人工智能厂商、数据标注企业、合规专业服务机构、技术方案提供商等加入标准起草编制组,共探数据标注产业高质量发展的合规路径。
【已确认参与起草的部分单位】
-
公安部第三研究所
-
中国电子信息产业发展研究院(赛迪研究院)
-
北京云测数据科技有限公司
-
江苏钟吾大数据发展集团有限公司
-
蚂蚁科技集团股份有限公司
-
福建中锐电子科技有限公司
-
北京易华录信息技术股份有限公司
-
北京集纳盛广网络科技有限公司(37度数据)
-
杭州数据交易所有限公司
-
北京热热文化科技有限公司(热热数据)
-
澳鹏Appen
-
国网江苏省电力有限公司连云港供电分公司
-
广西影迅物流有限公司
-
金华途样网络科技有限公司
-
重庆群星引力大数据科技有限公司
-
北京之合网络科技有限公司
-
北京市环球律师事务所
-
广东广悦律师事务所
-
浙江浦源律师事务所
-
更多单位确认中…..
《标准》将帮助AI企业从源头低成本解决数据标注合规难题,结合“业务场景实操化、人员管理规范化、企业经营稳健化”3大原则,聚焦数据来源、标注内容与过程操作、标注人员管理、数据安全与隐私保护、监督和审计机制5大关键合规议题展开研制。
欢迎人工智能厂商、数据标注企业、合规专业服务机构、技术方案提供商等相关单位参与起草工作,与会共研、共议标准优化方向。
如您对本标准感兴趣,欢迎扫码填报信息,后续会有工作人员与您联系

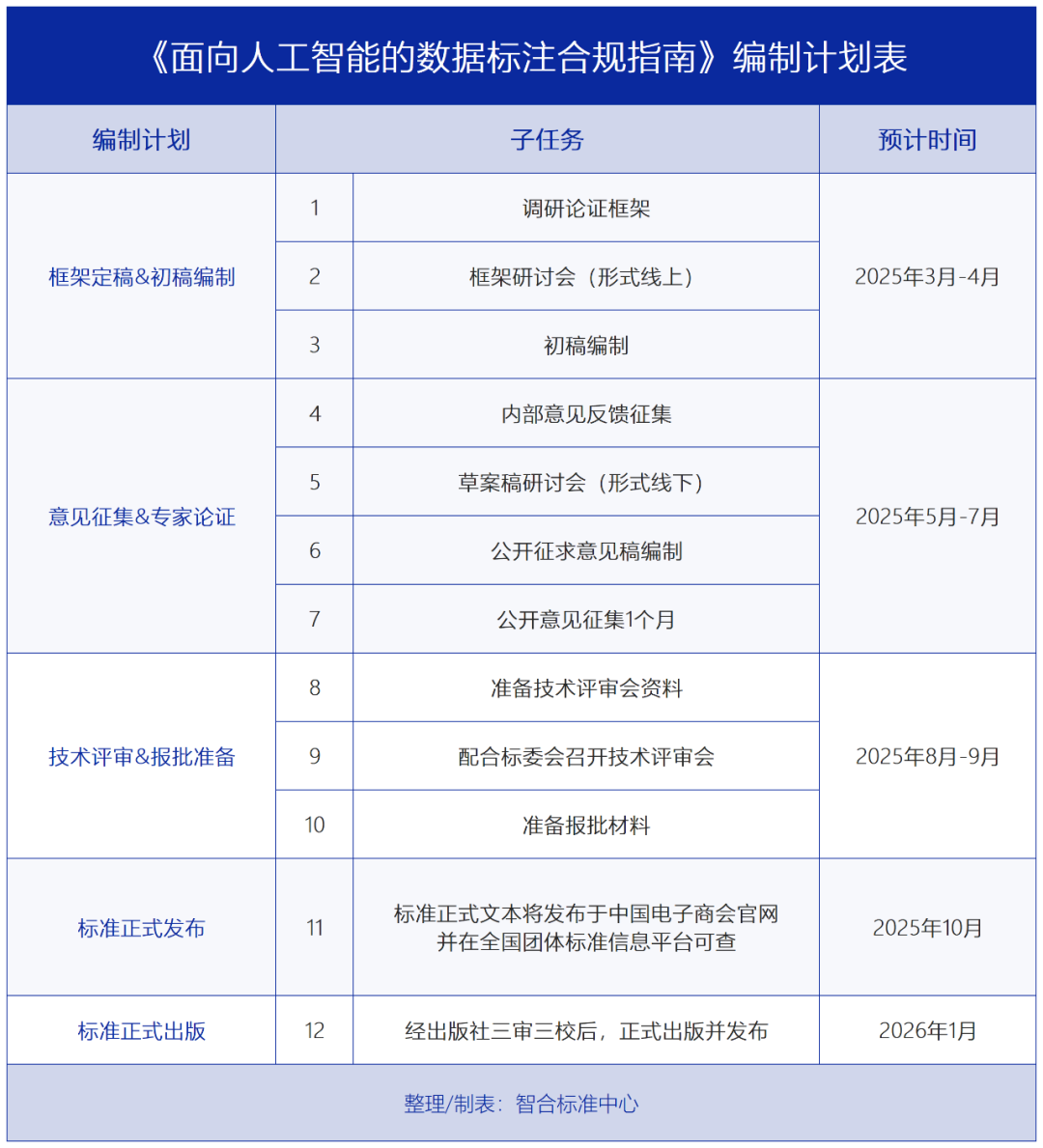
【编制计划】
(文:AI探索时代)