


极市导读
本文提出了一种新的自表征对齐方法,通过自蒸馏的方式就可获得表征指导,实验结果表明,将 SRA 应用于 DiTs 和 SiTs 会产生一致的性能改进。SRA 还实现了与依赖外部表征先验的方法相当的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
DiT 训练使用自蒸馏 (Self-Distillation) 取代 REPA。
最近关于表征对齐 REPA 的研究表明:在扩散 Transformer 中,学习有意义的内部表征既可以加速生成训练,也可以提高扩散 Transformer 的生成质量。但是,REPA 方法需要引入额外的大规模预训练的视觉基础模型比如 DINOv2,CLIP 等,在 DiT 的训练过程中提供指导。
本文觉得说 DiT 本身就已经具备判别的能力,使其本身就足以提供类似的指导,不再需要 DINOv2 了。基于此,本文提出了自表征对齐 (Self-Representation Alignment, SRA)。SRA 通过自蒸馏 (Self-distillation) 的方式获得表征指导。
SRA 将早期层 (噪声程度较高) 与末期层 (噪声程度较低) 的输出的 latent representation 对齐,辅助生成模型的训练。实验结果表明,将 SRA 应用于 DiTs 和 SiTs 会产生一致的性能改进。SRA 还实现了与依赖外部表征先验的方法相当的性能。
本文目录
1 SRA:DiT 训练使用自蒸馏取代 REPA
(来自 SGIT AI Lab, State Grid Corporation of China)
1 SRA 研究背景
1.2 SRA 观察
1.3 DiT 和 SiT 的训练目标
1.4 SRA 方法介绍
1.5 实验设置
1.6 实验结果
1 SRA:DiT 训练使用自蒸馏取代 REPA
论文名称:No Other Representation Component Is Needed: Diffusion Transformers Can Provide Representation Guidance by Themselves
论文地址:
https://arxiv.org/pdf/2505.02831
代码链接:
https://github.com/vvvvvjdy/SRA
1.1 SRA 研究背景
Diffusion Transformer 和 Vision Transformer 因其预训练的可扩展性以及下游任务的泛化能力,在视觉生成领域很常用。最近,许多工作表明:对于 DiT 而言,学习高质量的内部表征不仅可以加快训练进度,还可以提高生成质量。
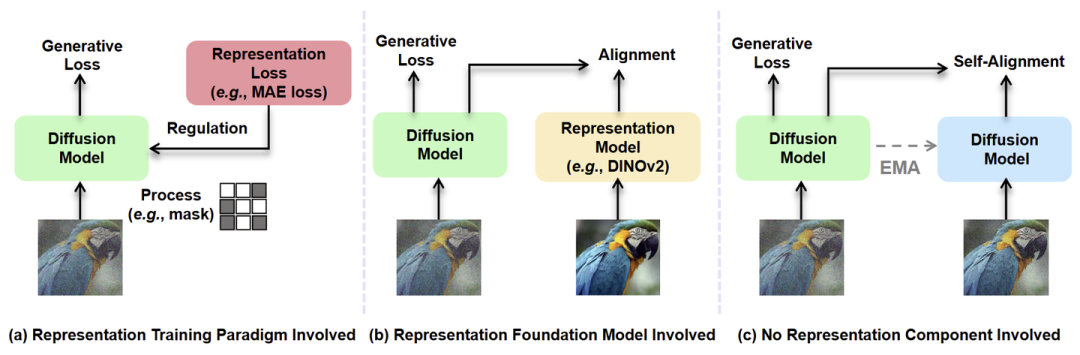
这些工作主要有图 1 的 2 种范式,在 DiT 训练期间提供表征的指导:
如图 1(a) 所示,利用表征学习的方法 (例如 MAE、IBOT)。这种方法需要复杂的训练框架设计。
如图 1(b) 所示,利用大规模预训练视觉基础模型 (例如 DINOv2、CLIP) 的表征。这种方法依赖一个强大的先验,该先验是在数千个 GPU 的海量数据上训练的。
因此,本文提出了一个重要的问题:在训练生成模型的时候,能不能不用额外的组件,获得类似的表征指导?
1.2 SRA 观察
表征模型通常输入干净的图像,输出语义丰富的特征。而扩散模型通常输入的是噪声,输出的每一次都比上一次更加清晰的图片。换句话说,扩散模型运行的生成机制通常可以被认为是从粗到细的过程。受这种行为的启发,本文假设 DiT 的表征也遵循这种趋势。为了验证这一点,作者对 DiT 进行了实证分析。
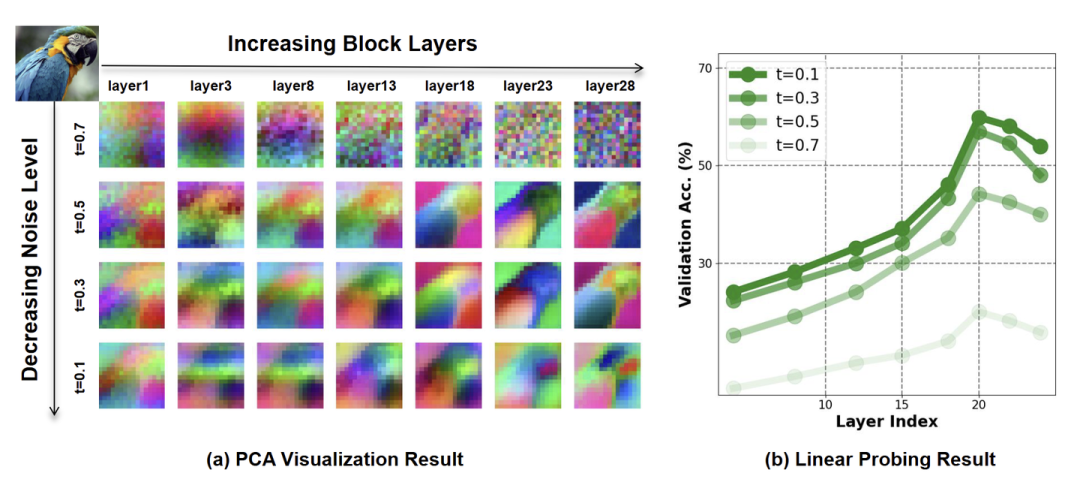
如图 2(a) 所示,作者首先发现随着 block 的增加和 noise level 降低,DiT 的 latent 特征逐渐细化,从粗糙逐渐变得精细。
如图 2(b) 的 ImageNet Linear Probing 结果所示,作者观察到扩散转换器已经学习了有意义的判别式的表征。Linear Probing 的精度在大约 20 层达到峰值后下降,因为模型需要偏移以专注于生成具有高频细节的图像。这说明增加 block,降低 noise level,表征质量基本上在慢慢变好。
从以上结果可以得出结论:DiT 预训练时,DiT 的表征大致从粗到细。且 DiT 学习到了有意义的判别式表征。
基于这种趋势,本文在生成模型 DiT 的训练中将 DiT 中的较弱表征与更好表征对齐,从而增强模型的表征学习,且不使用任何外部组件。
1.3 DiT 和 SiT 的训练目标
Denoise-based 的模型学习通过逐步去噪过程将 Gaussian noise 转换为 data sample。给定一个逐渐添加噪声的前向过程,这些模型学习反向过程来恢复原始数据。
对于分布 的数据点 ,正向过程如下: 。模型学习使用神经网络 反转这个过程,该网络预测每一步添加的噪声。该网络使用简单的均方误差目标进行训练,该目标衡量它可以预测噪声的程度:
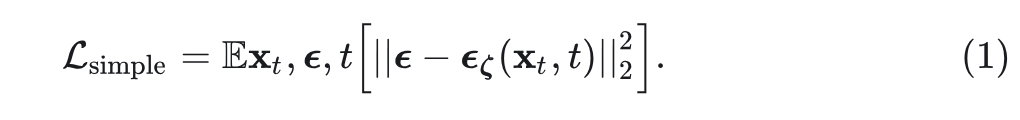
与 Denoise-based 的模型不同,Flow-based model 学习概率流常微分方程 (PF ODE) 的速度场 。PF ODE 允许模型通过流向数据分布,对数据采样。PF ODE 的前向过程定义为:
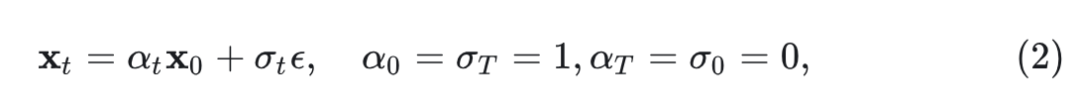
其中, 是数据, 是高斯噪声, 和 分别是 的单调递减和递增函数。PF ODE 由下式给出:

其中,该 ODE 在时间 的边际分布与正向过程的边际分布相匹配。为了学习速度场,训练模型 以最小化以下损失函数:
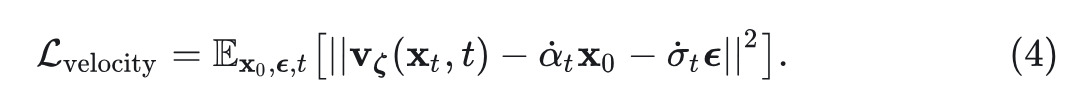
1.4 SRA 方法介绍
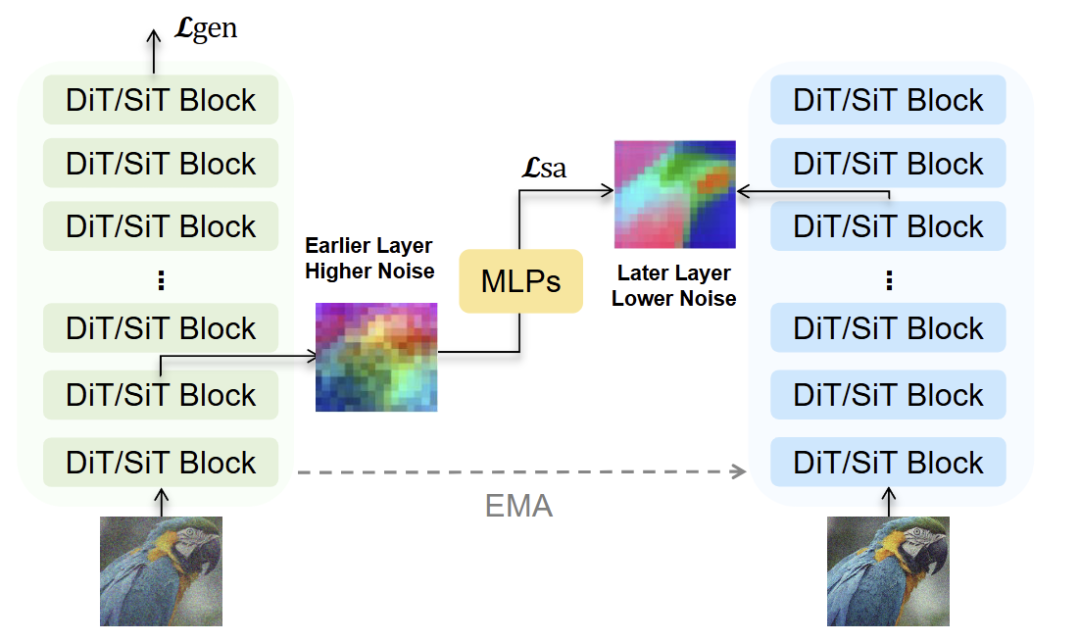
如图 1(c) 所示,SRA 不需要任何外部组件;本质上,SRA 将早期层的输出潜在表征 (噪声程度高) 与末期层的输出潜在表征 (噪声程度低) 对齐。
同时,为了使训练过程更加稳定,SRA 从另一个与可训练模型共享相同架构的模型 (通过 EMA 更新权重) 获得目标特征。也就是说,学生模型的输出 latent 特征首先通过投影层,然后与教师输出的目标特征对齐。
SRA 可以提供一种灵活的方式来获得表征的指导,且无需外部组件需求和架构修改。
如图 3 所示是 SRA 方法的框架。
设 是可训练的学生模型, 是教师模型。输入 noise latent,timestep,以及 condition 分别为 。
学生编码器 latent 输出 。
教师 latent 输出: 。
其中, 是 batchsize,number of patches 和 embedding dimension。 表示 中第 层输出。
SRA 中设置: 。使用教师输出 和学生的输出变换 进行自我表征对齐。其中, 是学生编码器输出 的投影,通过轻量级 MLP。
轻量级 MLP 可以在训练后可选地被丢弃。
SRA 通过最小化教师输出 和学生输出变体 之间的 patch-wise distance 来实现 Self-alignment:
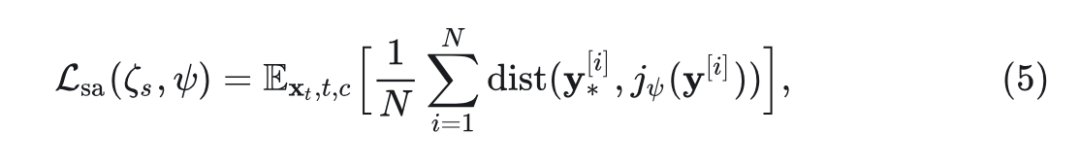
其中, 是一个 patch index, 是预定义的距离函数, 是学生 DiT 和投影头的参数。
把生成模型的训练目标 与上述 Self-alignment 结合起来,一起学习:

其中, 是超参数。
在 SRA 中,不需要现成的教师模型给出先验指导。SRA 使用学生权重的 EMA 从学生网络的过去迭代中构建教师模型。EMA: ,其中 是动量系数。
1.5 实验设置
实验部分关注以下几个问题:
-
SRA 中的每个设计选择和组件如何影响性能? -
SRA 对于不同 baselines 和 model sizes 是不是 work? -
SRA 与其他使用外部组件 (比如使用额外的表征学习范式,或者额外的视觉基础模型) 的方法相比,性能如何? -
SRA 是否真正增强了基线模型的表示能力,并且生成能力确实与表征指导密切相关?
除非另有说明,训练细节严格遵循 DiT 和 SiT 中的设置,无权值衰减,Batch Size 为 256,使用 SD VAE 提取 latent。对于模型配置,使用 DiT 和 SiT 论文中引入的 B/2、L/2 和 XL/2 架构,处理 Patch Size 为 2 的输入。
对于 DiT,使用 DDPM Sampler 并将函数评估 (NFE) 的数量默认设置为 250。对于 SiT,使用 SDE Euler-Maruyama 采样器(对于 的 SDE),默认情况下将 NEF 设置为 250。
1.6 实验结果
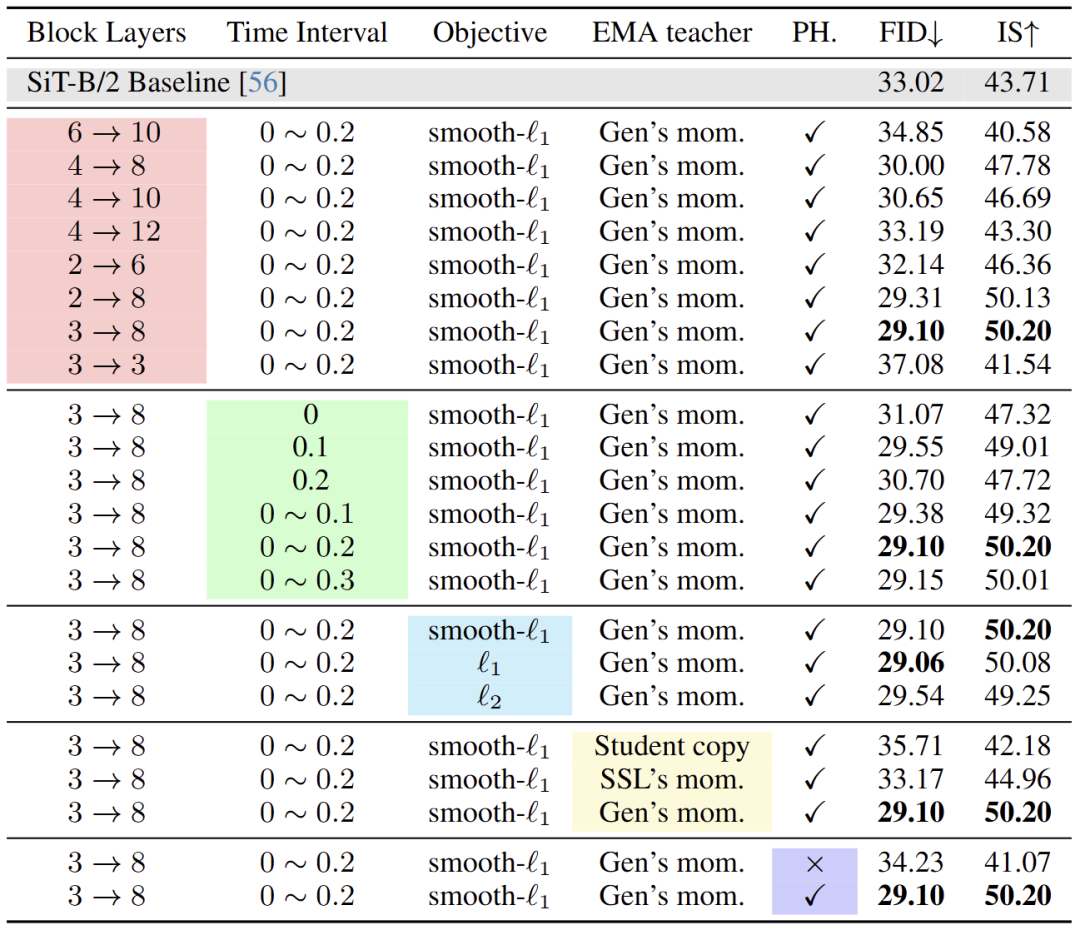
下面是对每个组件的影响进行的分析。使用 SiT-B/2 以及用 SRA 训练 400K iterations 进行评估,如图 4 所示。
用于对齐的层
首先,作者分析了使用不同学生和教师模型的层对齐的影响。这里的结论是:观察到使用教师模型相对后期的层,但是不是最后一层 (比如第 8 层),来监督学生模型相对早期的层 (比如第 3 层),可以得到最优的结果。作者认为前几层需要更多的指导,因此它们可以捕获语义上有意义的表征以进行后续生成。同时,教师层的表示质量与相应对齐学生的表现之间存在很强的相关性。基于这些结果,将 B、L 和 XL 模型的对齐层分别设置为 3 → 8、6 → 16 和 8 → 20。
用于对齐的 Time interval
然后作者研究了用于对齐的 Time interval (第 1.4 节中的 k )。这里作者研究了固定和动态间隔。这里的结论是:观察到教师模型相比学生模型,输入的特征噪声更低时,可以提高性能,间隔为0.1或平均值为0.1是最优的。
作者认为较低的噪声水平可以提供更好的表示指导,但过大的时间间隔会阻碍模型的学习过程,导致只关注优化对齐损失,而忽略了生成方面。动态区间表现出稍好的性能,实验中将时间间隔设置为 0-0.2。
对齐的目标
作者比较了 3 种简单的对齐回归目标,包括 smooth- 和 。发现 3 个目标都可以带来良好的性能并且在训练期间是稳定的。实验中使用 smooth- 。
用于对齐的教师网络
EMA 模型通常仅用于评估。然而,由于 SRA 需要它在训练期间提供指导,因此作者研究了不同的更新方法。
作者研究了几种不同的策略来构建教师模型。首先,发现教师模型如果直接从学生模型复制,会损害性能。接下来,使用自监督学习中使用的策略,在训练过程中将动量系数从 0.996 更新为 1。然而,发现效果不佳。最后,使用 0.9999 的动量系数不变,发现比较适合。
投影头对于对齐的影响
作者观察到使用简单的 head 来对学生的输出进行后处理,比直接使用学生的输出进行对齐要好得多。
作者认为这种轻量的操作使模型能够使得模型学习到更有效的 hidden representation,来进行最终对齐。这个就不用显式地对齐整个 latent 特征,因为这些特征可能会破坏每一个 layer 和 timestep 负责的原始生成内容。
系统级别的比较
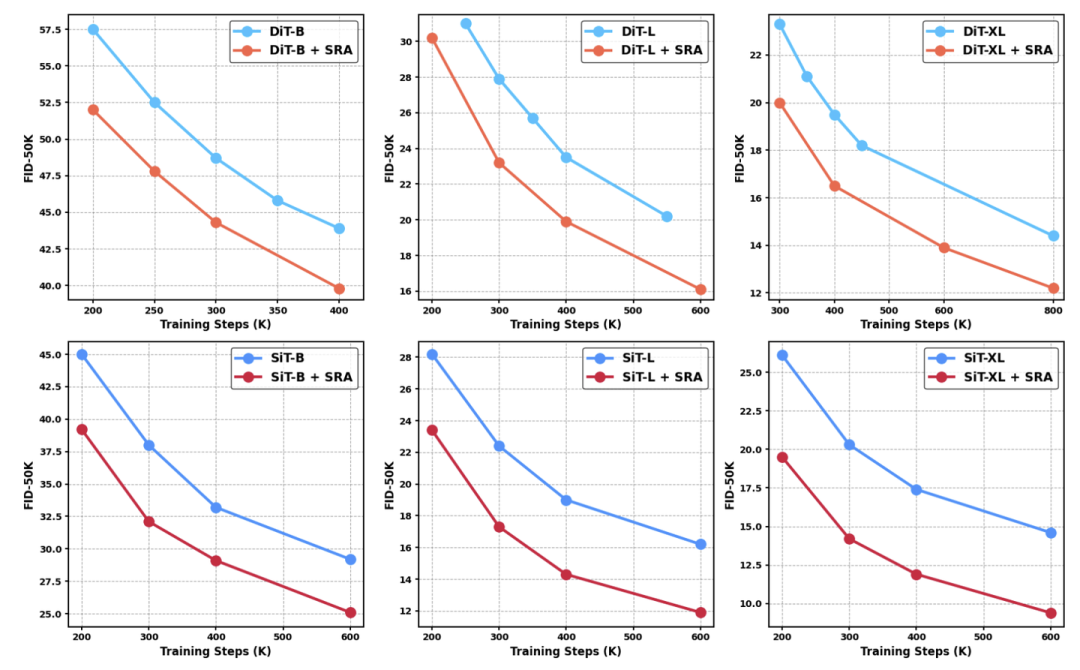
首先,作者比较了 vanilla DiT 或 SiT 与使用 SRA 训练的模型之间的 FID 值。如图 5 所示。
使用 SRA 训练的 DiT 在不同类型的每个 training step 以及各种大小上的性能都有显着提高。此外,与一些 SSL工作的观察结果类似,SRA 在更大的尺寸模型中的影响更为显著,这可能是因为较大的模型倾向于提供更丰富的指导。而且,即使模型已经获得了较低的 FID 分数,SRA 的优势也不会饱和。
作者认为这可能是由于教师在整个训练过程中的能力也不断提高,允许在训练时为学生提供更好的表征指导。
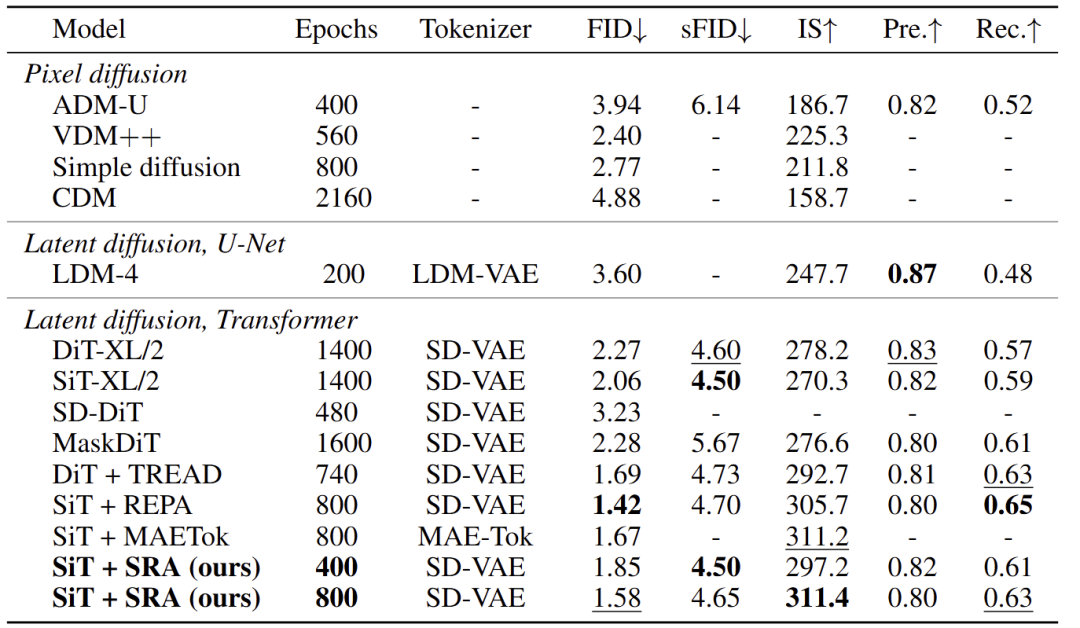
最后,使用 CFG 提供了 SiT-XL 与 SRA 和其他方法之间的定量比较,如图 6 所示。400 Epoch 的 SiT + SRA 超过了 SiT 方法。随着训练的延长,还会进一步提升。在 800 Epoch 时,SRA 的 SiT-XL 的 FID 为 1.58,IS 为 311.4。这一结果远远优于依赖于 MaskDiT,并且与 REPA 相当。此外,由于在整个训练过程中,教师模型的质量越来越高,作者发现与 REPA 相比,SRA 方法不太可能遇到饱和。


(文:极市干货)