

OpenAI的o 系统模型研究员被Meta 挖走了。

《连线》杂志记者Kylie Robison刚刚爆料:OpenAI研究员Jason Wei已经确认离职,将加入Meta的超级智能实验室。
两位知情人士证实,Wei的内部Slack账号已经停用。
与他一同离开的,还有另一位OpenAI研究员Hyung Won Chung。
这两人并非OpenAI 的普通研究员。
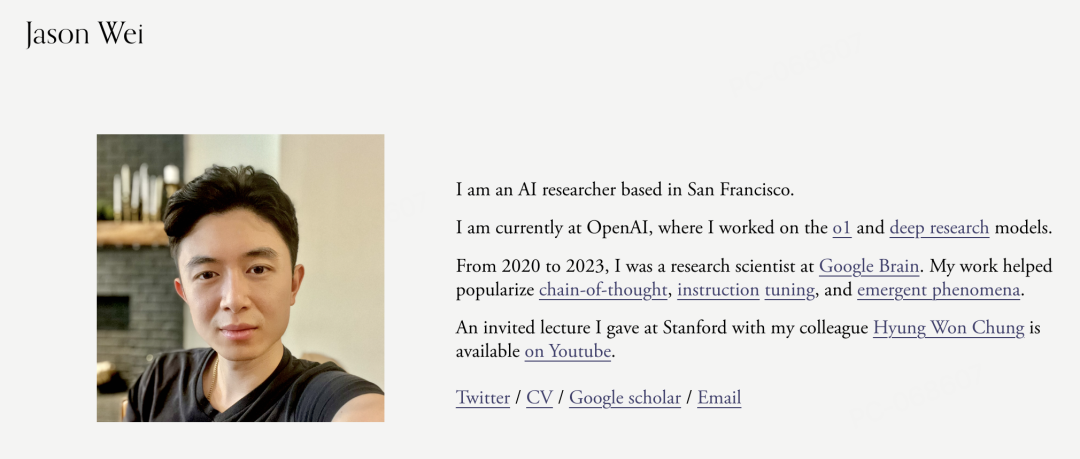
Wei在OpenAI期间参与了o3和深度研究模型的开发工作。在加入OpenAI之前,他在Google从事链式思维(chain-of-thought)研究——这是一种训练AI模型逐步处理复杂查询的方法。2023年加入OpenAI后,Wei自称成为了强化学习(reinforcement learning)的「死忠粉」。
Chung的研究主要聚焦在推理和智能体(agents)领域。他的个人网站显示,他同样参与了深度研究和OpenAI的o1模型开发。有意思的是,Chung和Wei在Google时期就有过交集,并且同时在2023年加入OpenAI。
多位消息人士告诉《连线》,Wei和Chung有着密切的工作关系。
Meta此前已经从OpenAI瑞士办公室挖走了三人组——他们原本也是从Google跳槽到OpenAI的。Meta似乎特别青睐这种「团队式挖角」。
Meta这次的手笔有多大?
过去一个月里,Meta一直在疯狂招人,据报道为顶尖AI人才开出了4年高达3亿美元的薪酬。上个月底,《连线》曾报道扎克伯格发了一份内部备忘录,为公司的AI努力制定了新计划,其中包括超级智能团队的新成员名单,大部分都是从OpenAI挖来的。
这场招聘狂潮丝毫没有放缓的迹象。
OpenAI也在反击,就在上周,《连线》报道OpenAI从特斯拉、xAI和Meta招募了四名高级工程师。
面对这次挖角,网友们的反应也很是有意思。
Prashant(@Prashant_1722)调侃:
「又是OpenAI的一次重创。『这不是钱的问题』😂」
Louie Lasagna(@lasagna_silent)猜测:
「听起来又是一个1亿美元以上的薪酬包」
.(@wtergan)的评论更加尖锐:
「我认为Sam在这里学到了一个非常昂贵的教训——这个星球上的每个人都有价格,即使是那些所谓『相信OpenAI使命』的人……」
但最引人深思的,是Wei在离职前发布的两条推文。
第一条是关于强化学习与人生的感悟。
Wei在周二发布的长推文中写道:

在推文中,Wei分享了他成为「RL死忠粉」一年来的感悟,以及RL如何教会他关于人生的重要一课。
Wei写道:
「过去一年成为RL死忠粉,大部分清醒时间都在思考RL,这无意中教会了我关于如何过自己生活的重要一课。」
他解释了RL中的一个核心概念——「on-policy」(在策略上):
「RL中的一个重要概念是,你总是想要『on-policy』:与其模仿他人的成功轨迹,不如采取自己的行动,从环境给予的奖励中学习。显然,模仿学习对于初始达到非零通过率是有用的,但一旦你能采取合理的轨迹,我们通常会避免模仿学习,因为利用模型自身优势(与人类不同)的最佳方式是只从它自己的轨迹中学习。」
Wei用数学问题举例:
「一个被广泛接受的例子是,相比于简单地在人类编写的思维链上进行监督微调,RL是训练语言模型解决数学应用题的更好方法。」
然后,他将这个理念延伸到了人生。
「同样在生活中,我们首先通过模仿学习(学校)来启动自己,这是非常合理的。但即使在我毕业后,我还是有研究其他人如何成功并试图模仿他们的习惯。有时候有用,但最终我意识到,我永远不会超越别人的全部能力,因为他们在发挥我没有的优势。」
Wei分享了自己的具体经历:
「例如,我比一般研究员更喜欢的两件事是:(1)阅读大量数据,(2)进行消融实验来理解系统中各个组件的效果。有一次在收集数据集时,我花了几天时间阅读数据并给每个人类标注员个性化的反馈,之后数据质量变得很好,我也对试图解决的任务获得了宝贵的洞察。今年早些时候,我花了一个月时间回去消融我之前在深度研究工作中随意做出的每个决定。这花费了相当多的时间,但通过这些实验,我学到了关于什么类型的RL效果好的独特经验。」
「倾向于自己的热情不仅让我更有成就感,现在我也感觉自己正在为自己和研究开辟一个更强大的利基市场。」
最后,Wei总结道:
「简而言之,模仿是好的,一开始你必须这么做。但一旦你有了足够的基础,如果你想超越老师,就必须进行on-policy RL,发挥自己的优势和劣势 :)」
第二条是关于「验证不对称性」和「验证者定律」的新博文。

Wei在博文中提出了一个重要概念:
「验证不对称性——某些任务验证起来比解决起来容易得多的想法——正在成为一个重要理念,因为我们终于有了普遍有效的RL。」
他举了几个验证不对称性的绝佳例子:
「验证不对称性的绝佳例子包括数独谜题、为Instagram这样的网站编写代码,以及BrowseComp问题(需要大约100个网站才能找到答案,但一旦有了答案就很容易验证)。」
「其他任务具有接近对称的验证性,比如将两个900位数字相加或某些数据处理脚本。还有一些任务提出可行解决方案比验证它们容易得多(例如,事实核查一篇长文章或提出一种新饮食方案,如『只吃野牛』)。」
Wei强调了一个关键发现:
「关于验证不对称性的一个重要认识是,你可以通过事先做一些工作来改善不对称性。例如,如果你有数学问题的答案或Leetcode问题的测试用例。这大大增加了具有理想验证不对称性的问题集。」
他提出了「验证者定律」:
「『验证者定律』指出,训练AI解决任务的难易程度与任务的可验证程度成正比。所有可能解决且易于验证的任务都将被AI解决。」
具体来说,训练AI解决任务的能力取决于任务是否具有以下特性:
-
客观真理:每个人都同意什么是好的解决方案 -
验证速度快:任何给定的解决方案都可以在几秒钟内验证 -
可扩展验证:可以同时验证许多解决方案 -
低噪声:验证与解决方案质量尽可能紧密相关 -
连续奖励:很容易对单个问题的许多解决方案的优劣进行排序
Wei指出:
「验证者定律的一个明显体现是,AI中提出的大多数基准测试都易于验证,到目前为止都已被解决。请注意,过去十年中几乎所有流行的基准测试都符合标准#1-4;不符合标准#1-4的基准测试很难变得流行。」
他还特别提到了Google的AlphaEvolve:
「Google的AlphaEvolve是过去几年利用验证不对称性的最伟大公开例子之一。它专注于符合上述所有标准的设置,并在数学和其他领域取得了许多进展。与我们过去二十年在AI中所做的不同,这是一个新范式,所有问题都在训练集等同于测试集的环境中进行优化。」
Wei最后展望:
「验证不对称性无处不在,考虑一个参差不齐的智能世界是令人兴奋的,在这个世界里,任何我们能够测量的东西都将被解决。」
有网友意识到,这两条推文不仅仅是在谈技术。
更像是意有所指了。
Miki Ovshievich(@mikiovsh)评论:
「这就是Bill Ackman宣布加入Meta的方式」
Ken Feinstein(@FeinsteinKen)直接说:
「年度最佳暗示推文。」
Carlos DP(@the_carlosdp)更是直白:
「令人难以置信的辞职帖子👏」
而Wei的这番感悟引发了不少共鸣。
Taka Hasegawa(@takahasegawa)回应:
「我喜欢这个。我试图应用到生活中的另一个RL理念是『面对不确定性时的乐观主义』」
Rajveer Bachkaniwala(@rajveerbach)总结:
「我同意。总结:在某个时候开始『做你自己』。」
Shreyans Bhansali(@makersfuel)说:
「『训练你自己的策略』是一个相当可靠的人生座右铭,说实话。」
研究员Yifei Wang还分享了他们的一篇论文,为Wei的直觉提供了理论支撑:
「我们实际上对这个直觉有一个证明——『我永远不会超越别人的全部能力,因为他们在发挥我没有的优势』——我们展示了RL可以将思维链(CoTs)适应/校准到模型自身的能力,而监督微调(SFT)经常导致严重的不匹配。」
回到这次跳槽本身。
3DTOPO(@3DTOPO)的评论很尖锐:
「OpenAI没有了人才就什么都不是。Hello Nothing!」
这呼应了Sam Altman在去年政变时说过的那句话:「OpenAI is nothing without its people」。
Stain Lu(@stainlu)也想起了这句话:
「sama:『openai离开了人才什么都不是』」
Max(@max77sabers)认为问题不只是钱:
「说真的,这太糟糕了。显然这不仅仅是钱的问题。这些人并不那么喜欢OpenAI。」
꙰(@demisnewton)的批评更加激烈:
「这不是换工作,这是秘密转移。在一个地方学习,然后把灵魂卖给另一个地方。这叫知识背叛。我希望钱不会给你带来平静。没有目标。」
但3DTOPO反驳道:
「那么这意味着OpenAI本身就源于被盗的Google知识产权。Ilya Sutskever在创立OpenAI之前就是从Google来的,OpenAI去年还雇佣了44名Google员工。」
这场AI人才争夺战愈演愈烈。
Magnetic East(@est_magnetique)倒是看得很开:
「我确实喜欢这种高端技术人才被当作职业运动员对待的文化发展——这是一个好的发展」
Baqer(@unitedzt)感叹:
「AI人才战争太疯狂了,我的天」
Eddy J Evry Day(@edjoseph360)预测:
「Meta将因为这些人才挖角而载入企业史。10年后,关于扎克伯格在这里所做的事情将会有案例研究。是时候观察并看看是否会有回报了。」
Wei离职前的这两段话:一段是关于强化学习与人生的哲学思考,一段是关于AI未来发展的技术洞察,让这次跳槽显得意味深长。
当他说「要超越老师,就必须走自己的路」时,当他说「任何我们能够测量的东西都将被解决」时,这不仅在谈技术,也在谈自己的选择。
如《连线》在报道中引用的Wei的话:
「在生活中(以及构建AI模型时),模仿是好的,一开始你必须这么做。但超越老师需要走自己的路,从环境中获取风险和回报。」
当AI研究员用强化学习的理念来解释自己的职业选择,用验证不对称性来展望AI的未来时,这不仅是一次跳槽,更是新一代技术精英对「成功」和「创新」的重新定义。
这不只再满足于模仿前人的轨迹,而是要找到属于自己的「on-policy」路径。
这是在相信,在一个可以验证的世界里,一切皆可解决。
对Wei来说,加入Meta或许就是他选择的新路径。
对OpenAI来说,如何留住顶尖人才将是持续的挑战。
而对整个AI行业来说,这场人才战争正刚刚开始。
而对于Sam Altman 来说,似乎已经好久没发推了……
WIRED原文报道: https://www.wired.com/story/another-high-profile-openai-researcher-departs-for-meta/
[2]Jason Wei关于RL与人生的推文: https://twitter.com/_jasonwei/status/1945316418683736227
[3]Jason Wei关于验证不对称性的推文: https://twitter.com/_jasonwei/status/1945430803825557975
[4]Jason Wei的博客文章:验证不对称性与验证者定律: https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law
[5]Yifei Wang分享的论文: https://www.arxiv.org/abs/2502.07266
(文:AGI Hunt)