
混合专家模型

DeepSeek R1 说这次是小升级,实测后我不信!

DeepSeek AI团队升级了DeepSeek R1模型,新版本在深度思考、写作自然性和持久专注能力上有所提升。通过具体示例展示了其在文本生成和辅助编程设计方面的实力,并强调了中国大模型的进步和发展前景。
通俗易懂看技术:24张流程图直观理解LLM、RAG及Agent
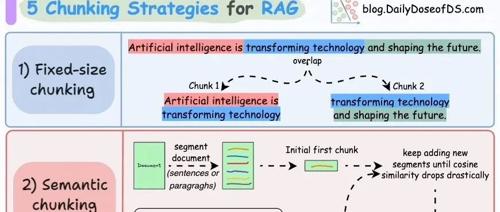
2025年5月24日周六,北京晴天。本文总结了大模型微调与训练、RAG及AgenticRAG等7张图,以及Agent、MCP和Functioncall的9张图。这些内容可供参考并作为验证标准,有助于深度思考和体系化学习。

用一个例子来通俗解释 DeepSeek 最新开源的 DeepEP

文章介绍了DeepEP,一个用于高效通信的开源框架。通过类比交通系统,解释了其主要特点包括全对全通信能力、支持两种通信方式(节点内和节点间)、高吞吐量低延迟的GPU内核以及灵活资源控制等特性。
刚刚,DeepSeek开源DeepEP,公开大模型训练效率暴涨秘诀!

专注AIGC领域的专业社区分享了开源的DeepEP库,用于优化混合专家模型训练和推理。DeepEP支持高效的All-to-All通信机制、高吞吐量和低延迟内核,以及原生支持FP8格式。
Kimi 模型,硬核开源…

AI研究者Kimi发布了首个大规模混合专家模型Moonlight-16B-A3B,其使用Muon优化器在5.7T tokens的训练中实现了约2倍的计算效率提升,并开源了分布式Muon实现版本和预训练模型。
A Visual Guide to Mixture of Experts (MoE)
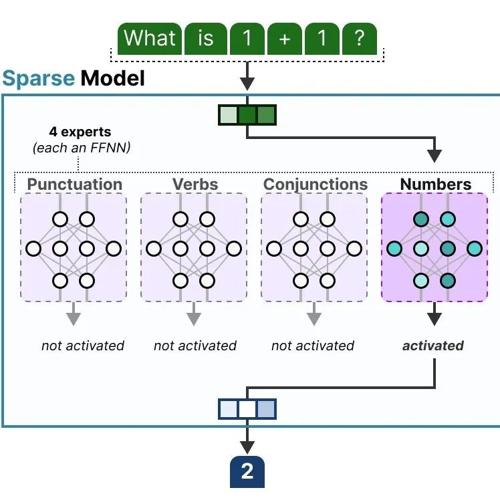
混合专家模型(MoE)通过动态选择子模型处理不同输入,显著降低计算成本并提升表现,核心组件包括专家网络、路由机制和稀疏激活。

DeepSeek-VL2开源MoE 视觉语言模型家族,Gemini英语口语助手,将 PDF 文档转换为互动式思维导图

本文介绍了DeepSeek-VL2、Leffa、小红书笔记生成器、Gemini 英语口语助手和PDF Mind Map Maker等创新技术与应用。它们涵盖多模态视觉-语言模型、可控人物图像生成框架、笔记生成工具及AI英语口语辅助等多个领域,提供高效便捷的功能以提升用户在不同场景下的工作效率和体验质量。