

AI模型要把效率提升上去之后,才能更好在行业突围,实现公司的商业意图。看我文章的老朋友应该还记得去年7月份的时候写过一篇《Meta重磅推出最强大模型LLAMA 3.1 405B》推文,里面提到了它拥有4050亿参数。
刚刚,Meta公司正式发布了Llama 4系列AI模型。并且首次引入混合专家架构,试图在生成式AI的竞赛中实现技术路径的差异化突破。个人觉得这不仅是技术层面创新,更折射出Meta在AI领域的战略焦虑与突围野心。
⋯ ⋯
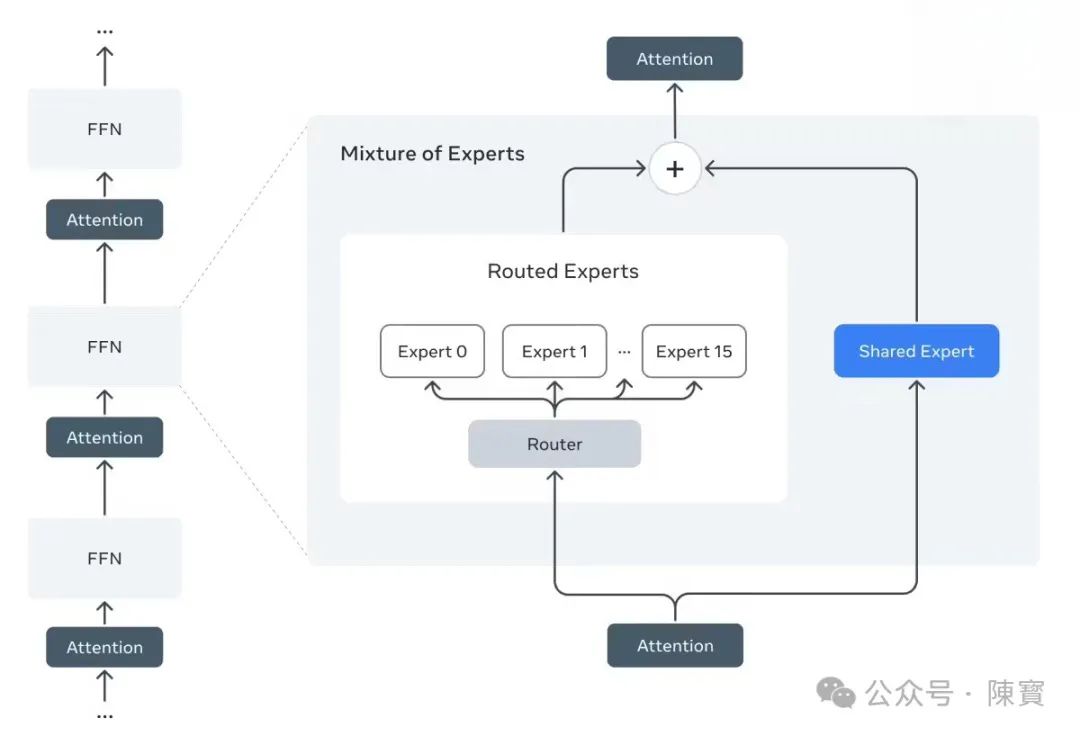
混合专家架构,也叫MoE。和传统大模型采用密集架构、所有参数参与每次推理不同,MoE架构将模型拆分为多个专家子网络。每个专家专注于特定任务领域,如数学推理、图像理解、代码生成,通过门控机制动态分配任务。
Llama 4 Maverick的4000亿总参数中,每次推理仅激活170亿参数,极大降低计算成本。通过按需调用机制,让模型在保持规模优势的同时,实现训练效率提升40%、推理速度提高3倍。
MoE架构的核心价值,在于用更少活跃参数达成更高性能。Llama 4 Scout仅需单块H100 GPU即可运行,却能处理1000万词元的上下文窗口,显著优于同级别密集模型。
使得Llama 4在边缘计算、实时交互场景中更具竞争力。Meta正在开发的AR眼镜Meta View,需要低延迟、高能效的本地化AI支持。
MoE并非新技术,DeepSeek、谷歌等早已应用。Meta此前坚持密集架构,认为MoE存在专家协作不充分、长尾任务处理弱等缺陷。
此次转向,实则是技术理想向商业现实的妥协。参数规模竞赛已触及物理极限,而Meta急需通过效率优化降低AI业务的边际成本。
⋯ ⋯
Meta将Scout和Maverick开源,但保留最强模型Behemoth的闭源训练。梯度开源既维持开发者社区热度,又为Meta AI保留技术壁垒。
参考历史,Llama系列的开源策略已吸引超50万开发者,但商业化转化率不足5%。此次通过MoE架构降低推理成本,Meta或试图吸引更多企业用户为其云服务付费。
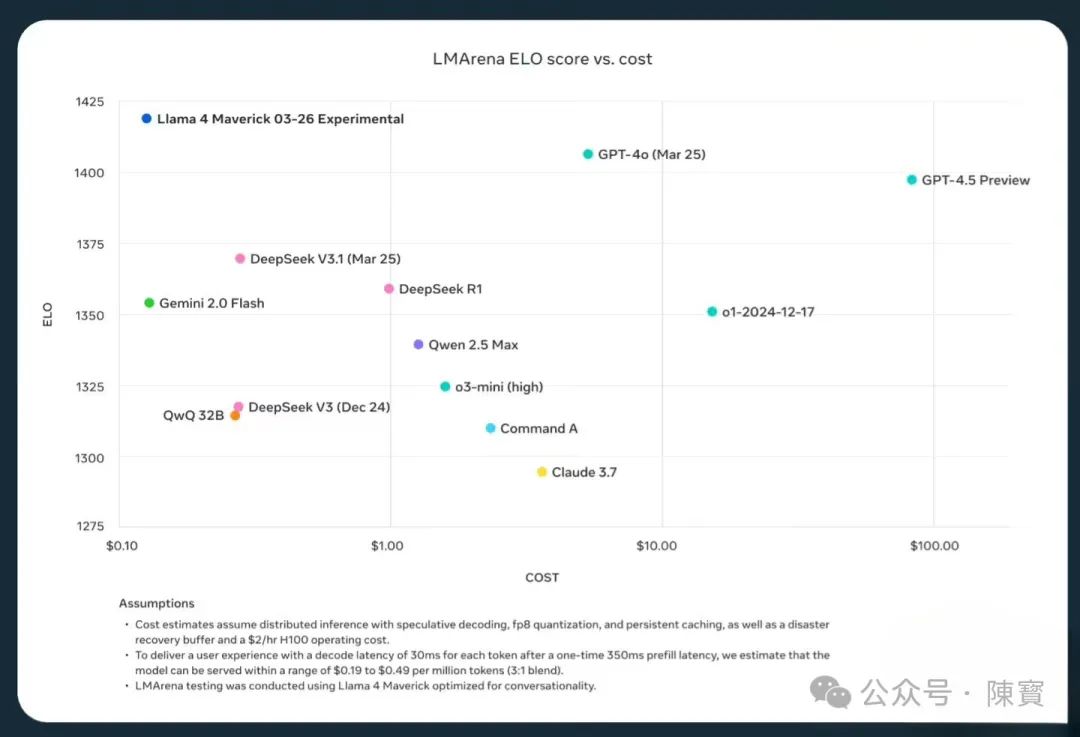
OpenAI推理模型GPT-4o通过事实核查提升准确性,但牺牲速度。而Llama 4的MoE架构以效率见长,更适合需要实时反馈的场景。
Meta的基准测试显示,Maverick在创意写作、代码生成等任务上已超越GPT-4o,但在复杂STEM问题上仍落后于GPT-4.5。差异化定位,有效避开了OpenAI强项,在垂直领域中建立优势。
Llama 4系列首次整合文本、图像、视频数据训练,暗示Meta正布局多模态入口。
Behemoth在STEM任务上的优势,会服务于Meta元宇宙内容生成。此外,支持超长上下文的特性,契合其社交平台的海量UGC数据处理需求。
⋯ ⋯
Llama 4硬件适配策略,也将推动推理芯片市场分化。
英伟达DGX平台仍是高端首选,但Meta 会联合AMD等开发定制化AI芯片,以优化MoE架构的稀疏计算效率。
边缘设备手机、XR头显的AI算力需求,在不久的将来会迎来爆发。
尽管Meta宣称坚持开源,但它的先闭源发布商业API,再开源旧版本新策略已经引发开发者不满。
如果社区无法复现Behemoth级模型,Meta 会重蹈Android生态的覆辙问题。掌握核心控制权,但失去开发者创新红利。
MoE架构虽然降低推理成本,但它的动态路由机制会导致输出波动性增加,尤其在跨领域任务中。

我认为,Meta 公司需要在效率与稳定性间找到平衡,否则企业客户会转向更可靠的闭源模型。
⋯ ⋯
理想很丰满,现实很骨感。Meta 公司想要让AI惠及所有人,但目前 Llama 4的技术路径却隐含矛盾。
MoE架构依赖复杂调度算法,中小开发者难以驾驭,而Behemoth的闭源训练更将技术权力集中于巨头手中。
未来值得期待,也充满了挑战。如果Meta 能够推出“可插拔专家模块”,才能真正实现AI民主化。否则,这场效率革命终将成为少数玩家的游戏。
Llama 4 发布不仅是技术迭代,更是Meta在AI霸权争夺中的关键落子。混合专家架构效率红利能帮助它在短期内缩小与OpenAI 技术差距,但真正的胜负手仍在于如何将技术优势转化为可持续的商业模式。
无论是通过元宇宙入口、广告精准投放,还是企业级AI服务。在这场竞赛中,效率与开放性的平衡,将决定Meta 公司能否打破技术领先却商业滞后的困境。
(文:陳寳)