

沉默已久的Meta,终于再次掀起AI界狂风,Llama 4系列模型官宣了!
这回不再是小打小闹,是对整个Llama系列的彻底重设计,不仅采用了最前沿的混合专家(MoE)架构,还原生支持多模态训练。
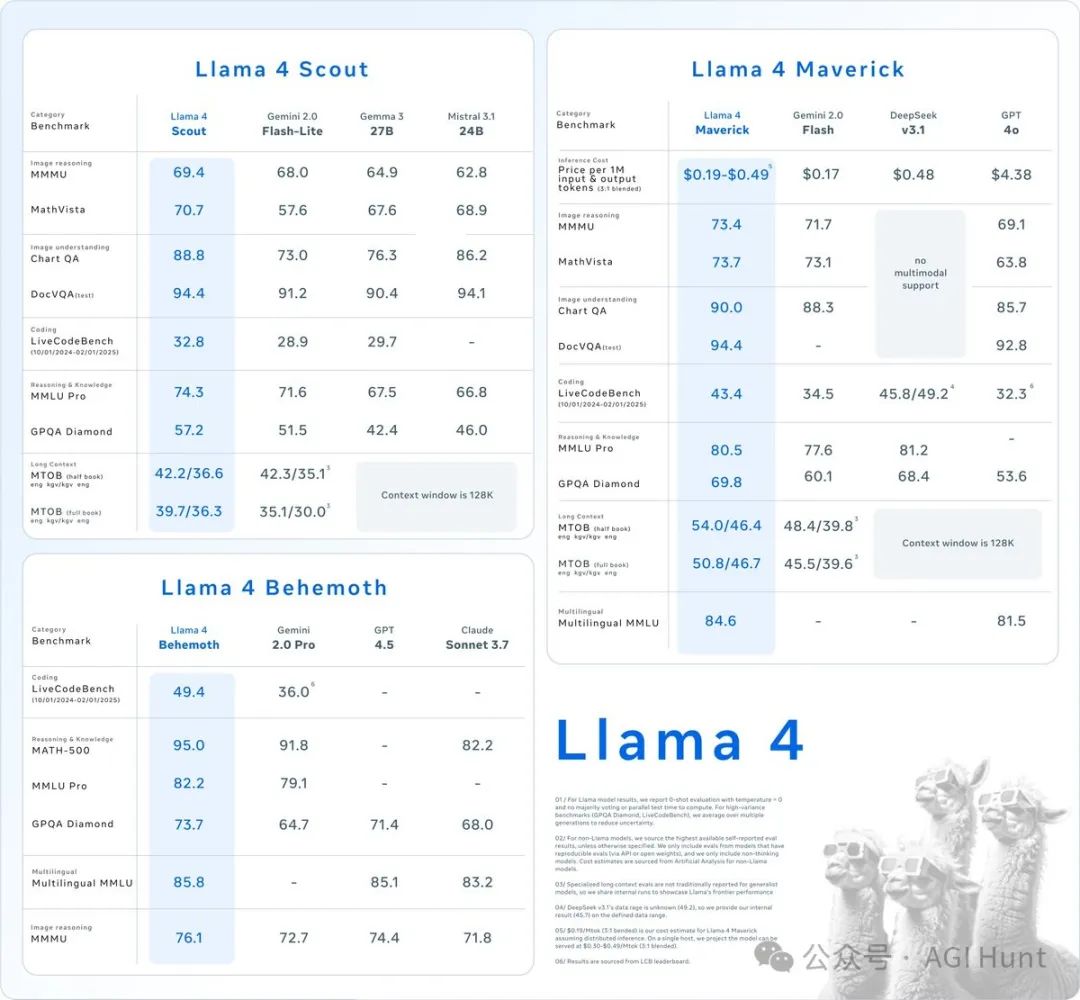
这次推出的模型包括三剑客:Llama 4 Scout、Llama 4 Maverick,以及仍在训练中的Llama 4 Behemoth。
三款模型各具特色,表现堪称惊艳
Llama 4 Scout可不是吃素的,这款小型模型拥有17B激活参数和16个专家,关键是支持超过1000万token的上下文窗口,而且轻量到能在单个GPU上运行。
单GPU就能跑,还能处理1000万token?
这是把「又快又好」写在脸上了啊!
再看Llama 4 Maverick
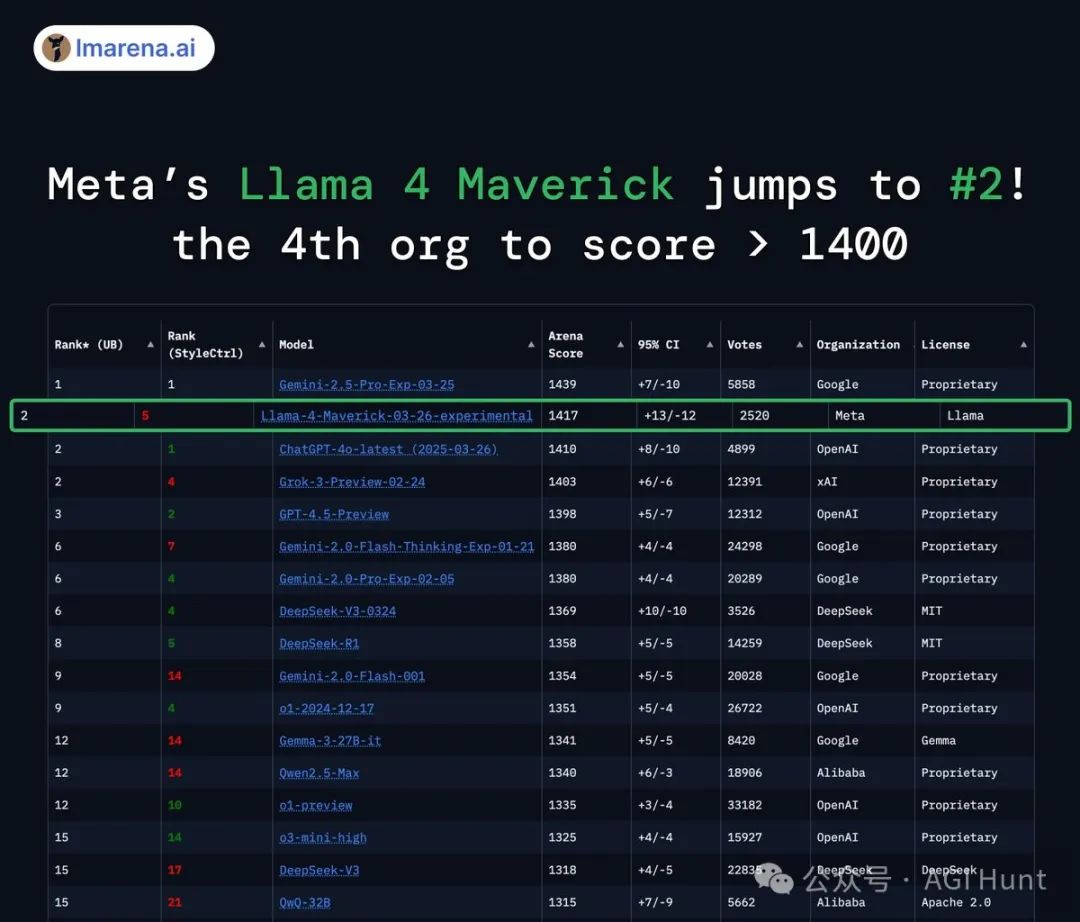
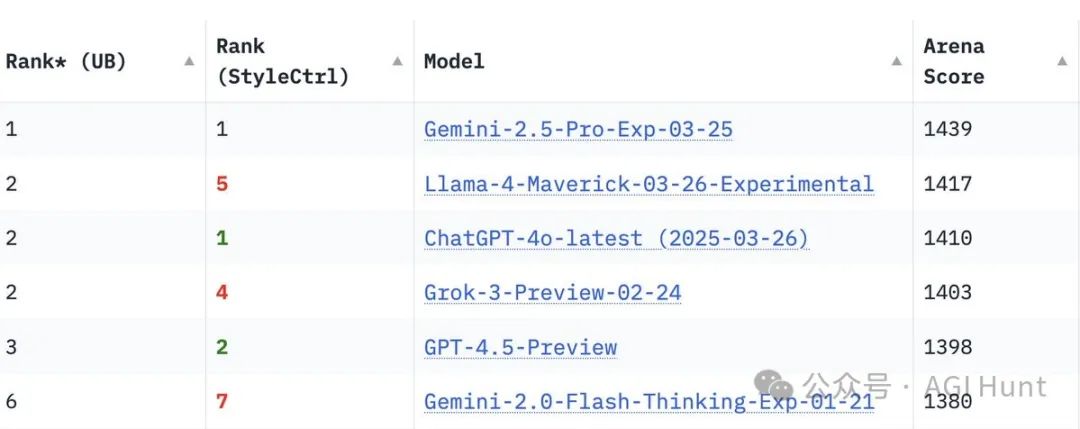
这位更是厉害,在LMArena上的聊天版本ELO评分高达1417,在多模态领域表现出色,成了Arena排行榜上的第二名,也是第四个突破1400分的组织。
人家在图像理解上完全秒杀GPT-4o和Gemini 2.0 Flash,推理和编码能力也与DeepSeek v3相当,但激活参数不到后者的一半!
这性价比,真不是一般的高啊。
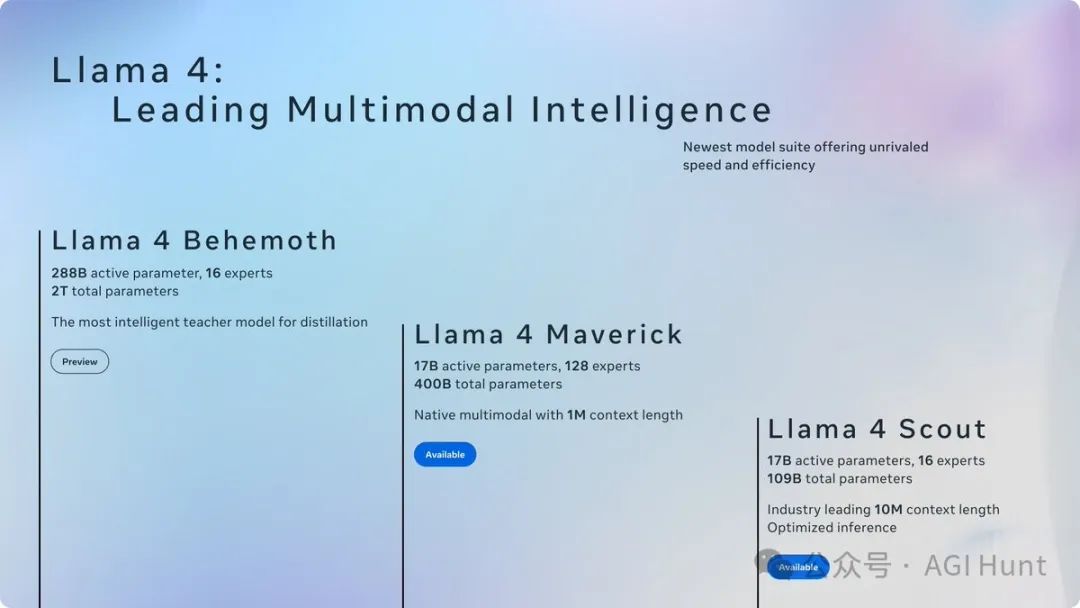
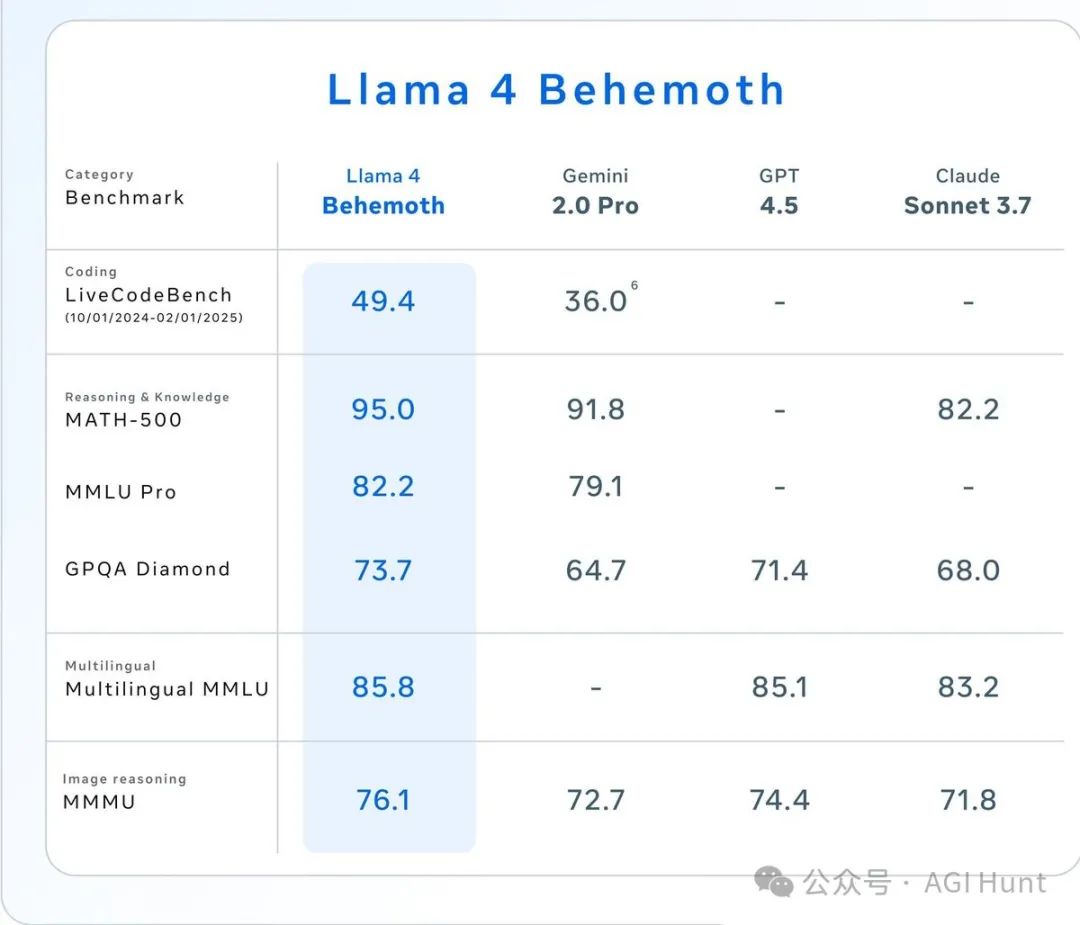
虽然Llama 4 Behemoth还在训练中,但已经在多个STEM基准测试中超越了GPT4.5、Claude Sonnet 3.7和Gemini 2.0 Pro。
这是Meta迄今最强大的模型,怪不得叫「巨兽」啊!
技术创新拉满,长上下文处理能力飞跃
Llama 4系列模型在技术上也是亮点频出。
首先是采用了iRoPE架构(交错旋转位置嵌入),这让它能够支持惊人的1000万token上下文窗口。
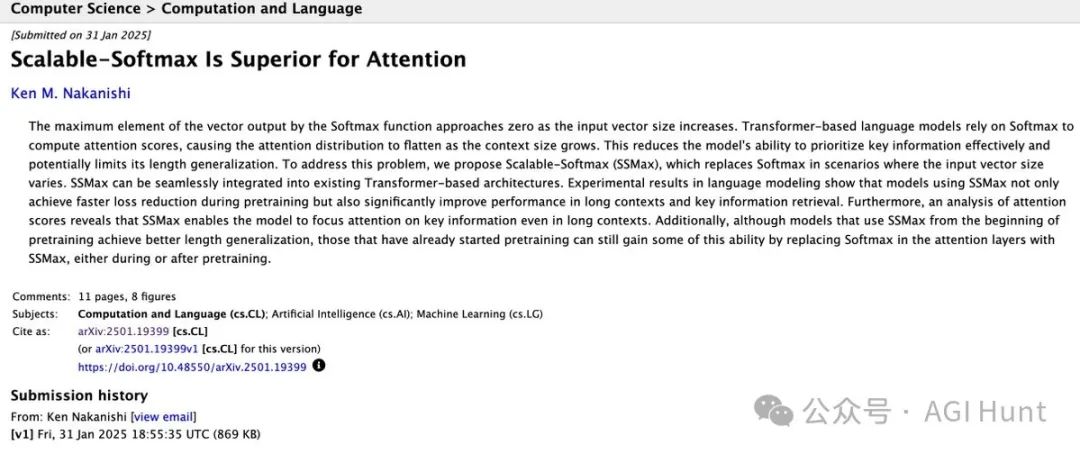
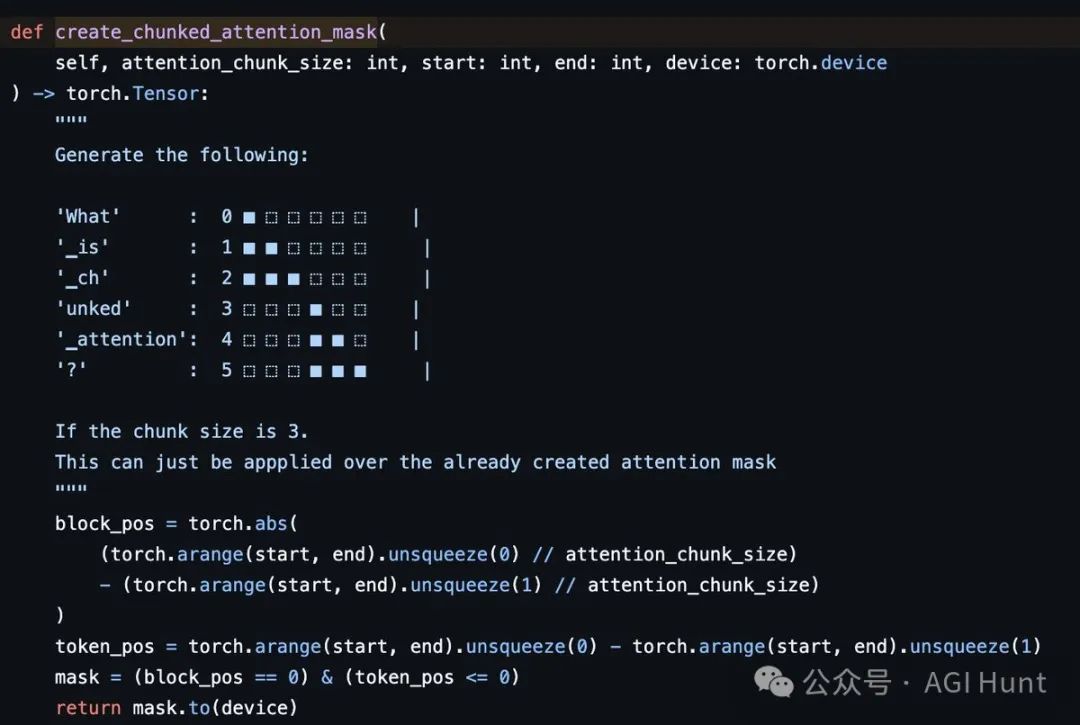
与传统的注意力机制不同,Llama 4还引入了分块注意力机制而非滑动窗口,以及缩放查询状态的技术,让Softmax在长上下文处理中表现更佳。
研究显示,这种注意力缩放技术让模型在处理超长文本时依然能保持高效,解决了随着上下文长度增加,Softmax概率分布变平的问题。
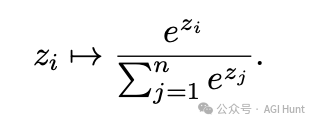
还不止这些,Llama 4还用上了FP8精度训练,在32K GPU上达到了390 TFLOPs/GPU的效率,以及MetaP技术自动调整超参数。
这种创新也带来了实打实的效果:Scout模型可以在不到3分钟的时间内,读取一个包含90万token的GitHub仓库并撰写指南!
多模态能力强大,轻松处理图像视频
Llama 4系列最大的突破之一就是原生支持多模态。
它使用MetaCLIP作为视觉编码器进行早期融合,能同时理解文字和图像的关系。
预训练就支持最多48张图像,实测也能轻松处理8张图片的输入。

特别是Maverick模型,图像接地能力一流,能够将用户提示与相关视觉概念精准对齐,并将模型响应锚定到图像中的具体区域。
Maverick的多模态能力打破了此前开源模型的天花板,让人在体验上几乎感受不到与闭源模型的差距。
在各种图像理解、识别和推理任务上,它都表现出了非凡的能力。
训练策略独特,共同蒸馏效果显著
传统模型训练和Llama 4的差别也不小。Meta团队采用了轻量级SFT结合大规模强化学习的策略,显著提升了模型在推理和编码方面的能力。

训练过程分为**「中期训练」阶段,通过新训练配方提升核心能力,包括使用专门数据集扩展长上下文;以及后训练流程**:轻量级SFT > 在线RL > 轻量级DPO。
更厉害的是,他们还使用了新型蒸馏损失函数,动态加权软硬目标,让小模型也能继承大模型的优秀能力。
不少专家认为,这种训练策略是Llama 4能够在有限的参数量下实现如此强大能力的关键。
特别是在RL阶段,Meta团队还只选择了更难的提示进行强化,这使得模型在复杂任务上的表现更加出色。
合作伙伴众多,多平台已上线
Meta并没打算独享这次技术突破,而是与众多合作伙伴一起,让Llama 4惠及全球开发者。
Hugging Face、Together Compute、SnowflakeDB、Ollama、Databricks等平台都已上线Llama 4 Scout和Maverick模型。

在Groq平台上,Llama 4 Scout和Maverick更是实现了无与伦比的速度。
甚至在M3 Ultra上使用MLX,Llama 4 Maverick也能实现50 token/sec的生成速度!

使用须知,许可有变化
值得注意的是,Meta为Llama 4制定了新的许可协议,与之前版本有些不同:
-
月活跃用户超过7亿的公司必须向Meta申请特殊许可证
-
必须在网站、界面、文档等显著位置显示「Built with Llama」
-
使用Llama材料创建的AI模型名称必须以「Llama」开头
-
分发时必须包含特定的归属声明,放在「Notice」文本文件中

这些新的限制引发了一些讨论,有人认为这是Meta在为自己的品牌建立更强的认知,也有人担心这可能会影响模型的开放性。
但总体来看,Llama 4的许可协议仍然比大多数闭源模型要开放得多。
虽然比DeepSeek 还是差远了。
行业专家热烈反响,点评不断
Llama 4一经发布,立刻引发了AI圈内众多专家的讨论和点评。
Meta的Russ Salakhutdinov教授表示:
Llama 4原生支持多模态、采用专家混合技术,性能显著提升,效率无与伦比,所有模型均易于部署,适应不同使用场景。
Tanishq Mathew Abraham博士对Llama 4的内部结构做了进一步解读:
「Llama 4采用早期融合MetaCLIP作为视觉编码器,比Llama-3多10倍的多语言令牌,通过新训练配方进行『中期训练』以提升核心能力,并使用专门数据集扩展长上下文能力。」
lmarena.ai(前身为lmsys.org)在推特上分享了Llama 4 Maverick在Arena排行榜上的成绩:
「Meta的Llama 4 Maverick在Arena排行榜上跃居第二,成为第四个突破1400分的组织。作为开源模型名列第一,超越了DeepSeek,并在多个任务上并列第一。」
Maxime Labonne则透露:
「Llama 4 Maverick初印象显示,其在文本处理上的表现不及Deepseek R1,在双base64字符串解码测试中失败。不过聊天能力似乎更优,但与推理模型相比这并不意外。」
Jeremy Howard对Llama 4表达了喜忧参半的看法:
「感谢Llama 4作为开放权重的模型发布,但其庞大的MoE结构使得即使在量化后也难以在消费级GPU上运行。Mac设备因其大内存可能更适合运行Llama 4,特别是在MoE模型上,因为激活的参数较少。」
Ethan Mollick教授则指出:
「尽管Llama Behemoth是一款强大的开源模型,但其性能与Gemini 2.5相比仍有显著差距。目前,开源模型尚未达到闭源模型的先进水平。」
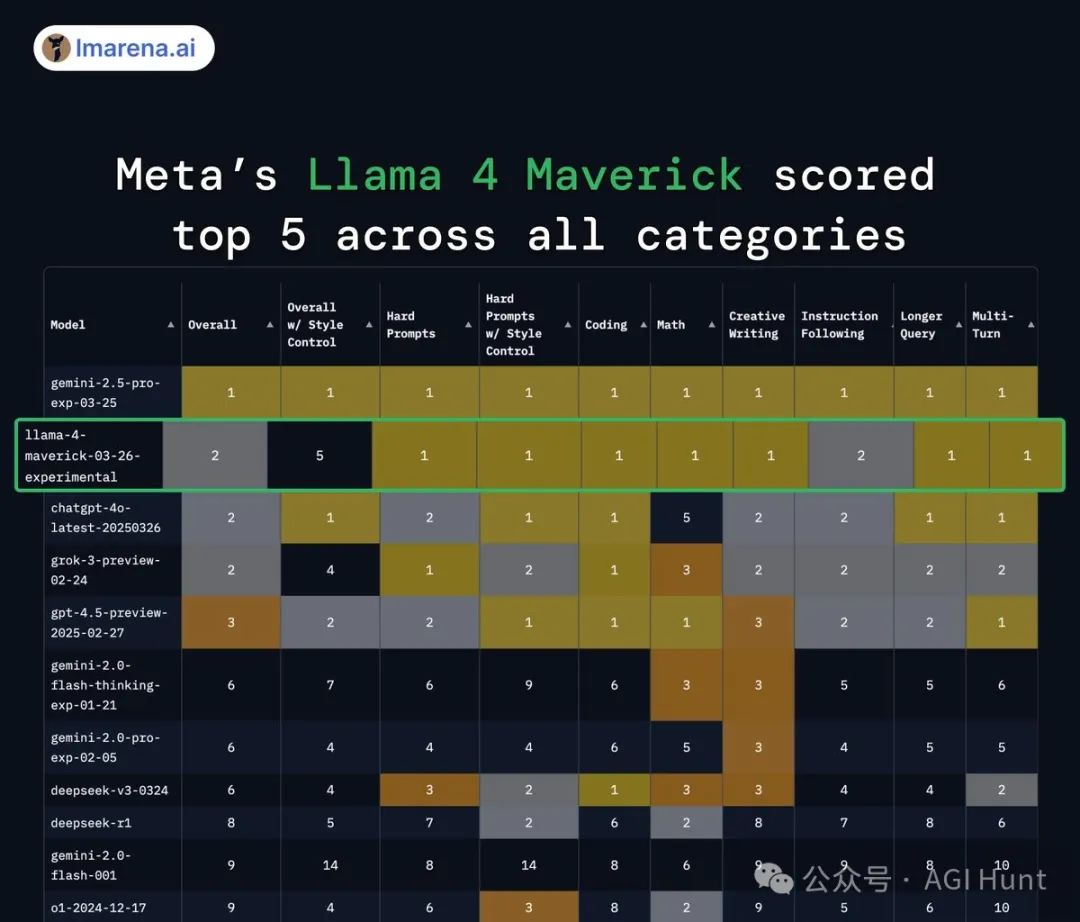
rohan anil展示了Llama 4 Maverick在多个类别中的优异表现:
「Meta 的 Llama 4 Maverick 在所有类别中都进入了前五名。特别是在高难度提示、编程、数学、创意写作、长查询和多轮对话等方面,获得了第一名。」
Matt Shumer分享了一个令人振奋的消息:
「Llama 4最重要的部分是,其最大版本Behemoth目前仍在训练中,发布时预计将超越GPT-4.5/Sonnet 3.7水平。虽然现在评价为GPT-4.5/Sonnet 3.7级别,但由于训练还在继续,发布时性能将更强。这对开源社区是一大胜利。」

TDM却表达了一些失望:
「Meta Llama 4的发布未能达到部分专家的期望。缺乏本地模型,被认为无法超越Gemma的密度。Scout 109B/17A模型在细粒度稀疏性方面表现不佳。虽然这些模型可能非常强大,但Meta的表现并未超出预期。」
wh注意到了Llama 4架构中的一个有趣细节:
「Llama 4在局部注意力块中采用了分块注意力机制而非滑动窗口,这一设计既有趣又略显奇怪。在局部注意力中,token索引8191和8192无法直接交互,它们交互的唯一方式是通过NoPE全局注意力层。」
xjdr提到了一个令人兴奋的可能性:
「通过适当的温度调优和大量的高带宽内存(HBM),L4 Maverick模型在当前形态下有望达到1亿参数。虽然1000万上下文长度听起来很疯狂,但这仅是Magic AI计划用真实大型语言模型尝试的上下文长度的十分之一。」
关于Llama 4的性能秘密,rohan anil提出了六点理论:
「Llama 4 Maverick的卓越表现可能归功于:交替密集/混合专家有助于泛化;密集共享确保不丢失任何令牌,MoE学习残差;MetaP进一步改善泛化;共蒸馏中的动态权重帮助避开较差的教学信号;更高的总参数与激活比率;以及训练设置、课程等因素。」
模型基础性能全面提升
Llama 4在各个评测中表现亮眼,尤其是Maverick,在Hard Prompts、Coding、Math、Creative Writing、Longer Query和Multi-Turn等多个类别中都能排进前五。
在LMArena上,Llama 4 Maverick不仅成为开源模型中的第一名,超越了DeepSeek,还在多个关键指标上与封闭源模型平分秋色。
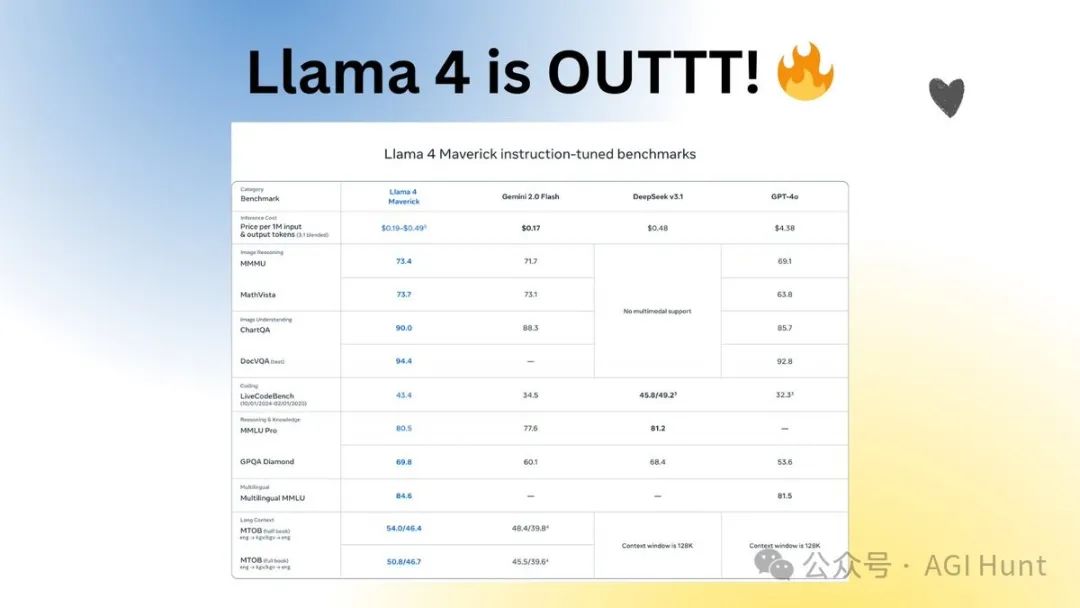
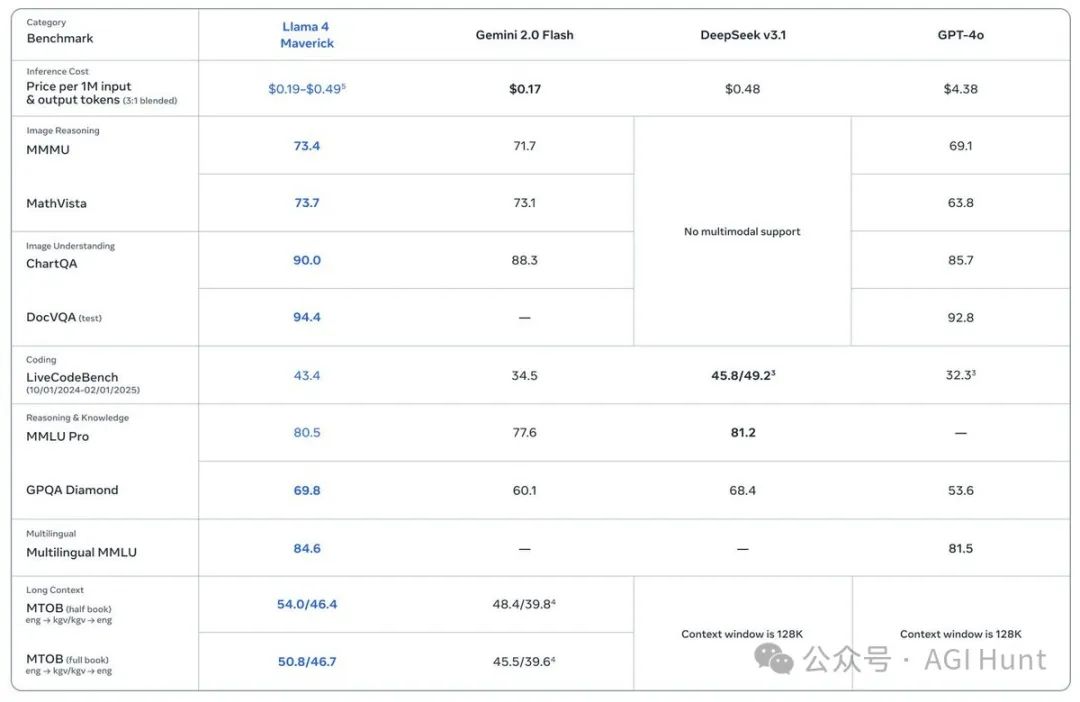
与Llama 3 405B相比,Maverick的评分从1268跃升至1417,进步明显。
在性能与成本比上,Llama 4 Maverick更是达到了行业领先水平,每百万tokens的服务成本估计仅在**
更厉害的是,Llama 4系列模型的实用性也得到了显著提升。
据AI at Meta介绍,Llama 4支持12种语言的多语言写作任务,开发者还可以根据Llama 4社区许可证和可接受使用政策,为这12种语言之外的语言微调Llama 4模型。
Llama 4的多语言能力也远超前代。
Vaibhav Srivastav指出,Llama 4 Maverick(402B)和Scout(109B)模型原生支持多语言,联合预训练文本、图像和视频达到30T+ tokens,是Llama 3的两倍。
实用工具链已经就绪
为了方便开发者快速上手Llama 4,Meta和合作伙伴们也准备了丰富的工具链。
Red Hat AI宣布Llama 4 Herd已获得vLLM项目的Day 0支持,开发者可以立即使用这些模型进行推理。
Sanyam Bhutani也分享了详细的入门指南,演示了如何利用Llama 4处理长上下文任务。
Together AI作为Meta的发布合作伙伴,推出了支持多模态输入的Llama 4 Maverick和Llama 4 Scout。
这两款模型在12种语言的多语言图像/文本理解、创意写作和多文档分析方面表现出色。
GroqCloud™也在第一时间上线了Meta的Llama 4 Scout和Maverick模型,提供了即时的访问、快速的性能和最低的成本。
FireworksAI与Meta合作,让Llama 4模型支持高达1000万tokens的长上下文处理,创下了开源模型的新纪录。
更多惊喜在路上
Meta表示,Llama 4系列还将继续推出更多模型。
目前披露的Llama 4 Reasoning将于下月公布更多消息,而Llama 4 Behemoth的完整版本预计将在训练完成后推出。
据不完全统计,Behemoth拥有288B激活参数、16个专家和高达2T的总参数,来自这个「巨兽」的蒸馏也让Scout和Maverick模型受益匪浅。
更令人兴奋的是,据Ahmad Al-Dahle透露,Meta正在训练一个拥有2T参数的模型,这将是目前最大且性能最佳的基模型,而且该公司计划不久后将其开源。

Aston Zhang也分享了关于Llama 4的更多细节,称其实现了行业领先的10M+多模态上下文长度,相当于20多小时视频的处理能力。
这一突破得益于iRoPE架构的开发,为AGI的长期无限上下文目标迈出了重要一步。
Baseten则宣布,Scout模型在8xH100上可服务百万token,Maverick模型取代了Llama 3.1 405B,在8xH100 FP8上可服务约一半上下文,而完整上下文及更快速度需要H200或B200支持。
TuringPost总结道,Llama 4系列模型凭借其采用MoE架构以提高效率、支持10M token的超长上下文处理以及多模态能力,已经成为了AI领域的重要里程碑。
看来,Meta在开源AI领域的长期承诺并非虚言,这次的Llama 4系列真的展现了其在人工智能领域的雄心与实力!
不过,不论未来Llama系列会带来多少惊喜,
最期待的仍然是——
DeepSeek R2 能够全线狙击LlaMa 的过去、现在和未来!
(文:AGI Hunt)