

今天分享两个大模型 API 省钱黑技巧,希望能帮你省点钱。

秘籍一:文本转截图大法
这适用于费用主要花在输入token上的任务——那种输入巨长、输出很短的情况。

简单show 个case 吧还是——
一道简单的数学题:
小明有8支铅笔,小红给了他4支铅笔。现在小明一共有多少支铅笔?
我把它扔给ChatGPT,让它扩写:

于就是得到了一个超长prompt(其实也就928字):

为了确保输出token 数相当好公平比较,我手动补了一句“不要输出任何废话,直接给出答案对应的数字”
然后拼成两个messages 分别调用API:
import os
image_path = f'{os.path.expanduser("~/")}/Downloads/question.png'
messages_text = [
{
"role": "user",
"content": [
{
"type": "text",
"text": text
}
]
}
]
import base64
with open(image_path, "rb") as image_path:
base64_image = base64.b64encode(image_path.read()).decode('utf-8')
messages_image = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "low"
}
},
{
"type": "text",
"text": '不要输出任何废话,直接给出答案对应的数字'
}
]
}
]图片调用的结果如下:
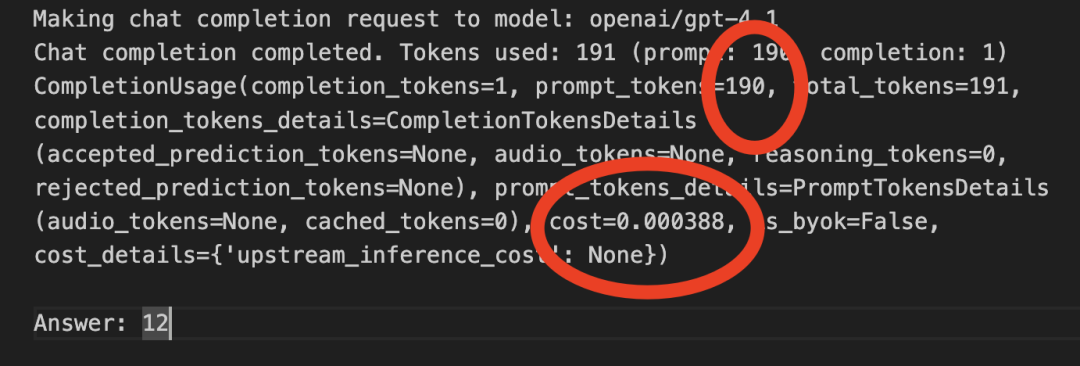
输入token 数为192,共花了0.000388$
纯文字调用的的结果:
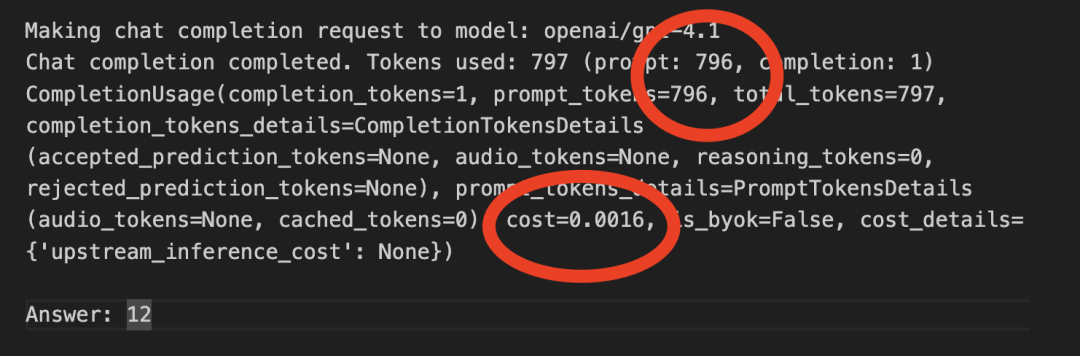
输入token 数为796,共花费0.0016$
效果完全没打折扣,但省了75%的钱。
直接看o3 给的分析好了:

需要注意的是,当文本超过425个token时,截图反而更便宜。
技术实现:
# API调用时必须设置detail参数为low
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": [{
"type": "image_url",
"image_url": {
"url": image_url,
"detail": "low" # 关键!不设置会按高分辨率计费
}
}]
}]
)
图片预处理:
# 压缩到512px以内,确保只占一个tile
convert input.png -resize 512x512 output.png
如果你也有点小聪明,可能就会产生一个狂野的想法——能不能把1000万token 压到一张图上,来突破context 不够长的问题?
只要我字号无限小,多少字都能放得下啊!
呃……你真是个大聪明啊!
你猜行不行?
祝你好运。
秘籍二:音频加速识别
如果你用过应该就会知道——OpenAI的语音识别模型Whisper 是按音频时长收费的,每分钟0.006美元。
那么问题来了:能不能把音频先压短,时长不就短了吗?
不就能省出钱了吗?
答案是:能,且效果真还行!
我们平时听播客不都2倍速吗?
AI 的耳力不能比我们差……
我vibe coding 了个测试脚本:
# 原始音频转3倍速
ffmpeg -i input.mp3 -filter:a "atempo=3.0" -ac 1 -b:a 64k output-3x.mp3
# 调用Whisper API
curl --request POST \
--url https://api.openai.com/v1/audio/transcriptions \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-Type: multipart/form-data' \
--form file=@output-3x.mp3 \
--form model=whisper-1
然后实测了个40分钟的Sam Altman 播客视频,结果如下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 倍速时能省67%,且质量还过得去。
建议:2.5倍速。
One More Thing
好吧,还有个骚操作——
既然自己能省钱,不能帮别人也省省吗?
把秘籍一和秘籍二包装成API 服务。
自己再赚点差价它不香吗?

我们来估算下利润率:
文本处理服务
-
用户发来5000字长文本,收费$0.02 -
我直接给截图处理,成本$0.0013 -
毛利润:93.5%
音频处理服务
-
用户发来1小时音频,收费$0.20 -
我得下个狠心直接3倍速处理,成本$0.08 -
毛利润:60%
来算算月入一万刀需要多少用量?
假设两种服务各占50%:
-
文本服务:需要处理26万次(每次赚$0.019) -
音频服务:需要处理4.2万小时(每次赚$0.12)
平均下来,每天处理8700次文本或1400小时音频。
好人做到底,核心代码也有了(Claude 写的):
from fastapi import FastAPI, UploadFile
import asyncio
from PIL import Image
import io
app = FastAPI()
@app.post("/optimize-text")
asyncdef optimize_text(text: str):
if len(text) > 255: # 超过阈值才截图
# 生成图片
img = text_to_image(text)
# 调用OpenAI
result = await call_openai_vision(img)
# 计算省了多少
saved = calculate_savings(text)
return {
"result": result,
"original_cost": saved["original"],
"optimized_cost": saved["optimized"],
"you_saved": saved["saved"]
}
else:
# 短文本直接转发
returnawait call_openai_text(text)
@app.post("/optimize-audio")
asyncdef optimize_audio(file: UploadFile):
# 智能选择加速倍数
duration = get_audio_duration(file)
speed = 2.5if duration > 30else2.0
# 处理音频
result = await process_audio_with_speedup(file, speed)
return {
"transcript": result,
"speed_used": speed,
"money_saved": f"${(duration * 0.006 * (1 - 1/speed)):.2f}"
}
def text_to_image(text: str) -> bytes:
"""把文本转成低分辨率图片"""
# 这里省略了具体实现
# 要点:黑白图、小字体、压缩到512px
pass
不过,记得要遵守OpenAI 的条款:
-
不能转卖裸API -
必须提供增值功能 -
要有隐私政策
另外,记得要自动判断是否需要截图(425 token 的阈值),不然可能钱没赚到,反而把自己给亏进去了……
最后,把从OpenAI 那里省下来的钱,一半给用户,一半自己留下。
皆大欢喜!
不过记得:
这篇文章就别转发了,不然就都自己干了没你赚钱的事了
BTW,其实这两大秘籍,也就一个真•靠谱,你猜是哪个?
以及,为什么?
(文:AGI Hunt)