

新智元报道
新智元报道
【新智元导读】清华大学团队在强化学习领域取得重大突破,开发出DSAC及DSAC-T系列算法,有效解决强化学习中的过估计问题,提升学习效果稳定性;团队还提出DACER算法,将扩散模型与在线强化学习结合,进一步刷新性能记录;RAD优化器为强化学习训练稳定性提供保障,相关成果将集成入开源软件GOPS,推动具身智能发展。
想象一下幼儿的成长过程,在不断探索与试错中积累经验、提升智慧。这正是强化学习的核心思想:通过与环境的互动,不断调整策略以最大化长期回报。
从上世纪末期以来,强化学习技术快速发展,2016年AlphaGo击败围棋世界冠军李世石展示出这项技术解决复杂问题的巨大潜力。

然而,将强化学习应用于机器人,在真实世界中产生智能,还面临许多挑战,主要是因为真实世界的环境更加复杂多变,现有技术难以应对这种复杂性,导致学习效果不稳定。
清华大学深度强化学习实验室长期深耕强化学习的基础理论和应用,于近期连续取得关键性技术突破!
研究人员模拟人类对自然世界的真实感知模式,突破传统强化学习依赖点估计处理连续动作空间的局限,构建动作空间概率模型,在复杂环境中动态调整动作概率分布,开发出DSAC(Distributional Soft Actor-Critic)及DSAC-T系列算法。在基准测试环境中,该系列算法取得了大幅的性能提升,并以50%以上的优势领先于OpenAI的PPO和Deepmind的DDPG算法。
在刚刚落幕的机器学习顶会NIPS2024中,团队进一步将扩散模型与在线强化学习深度融合,发布了DACER算法。算法把扩散模型的反向过程定义为新策略近似函数,利用其强大表示能力提升性能,再次刷新了强化学习性能的世界记录。
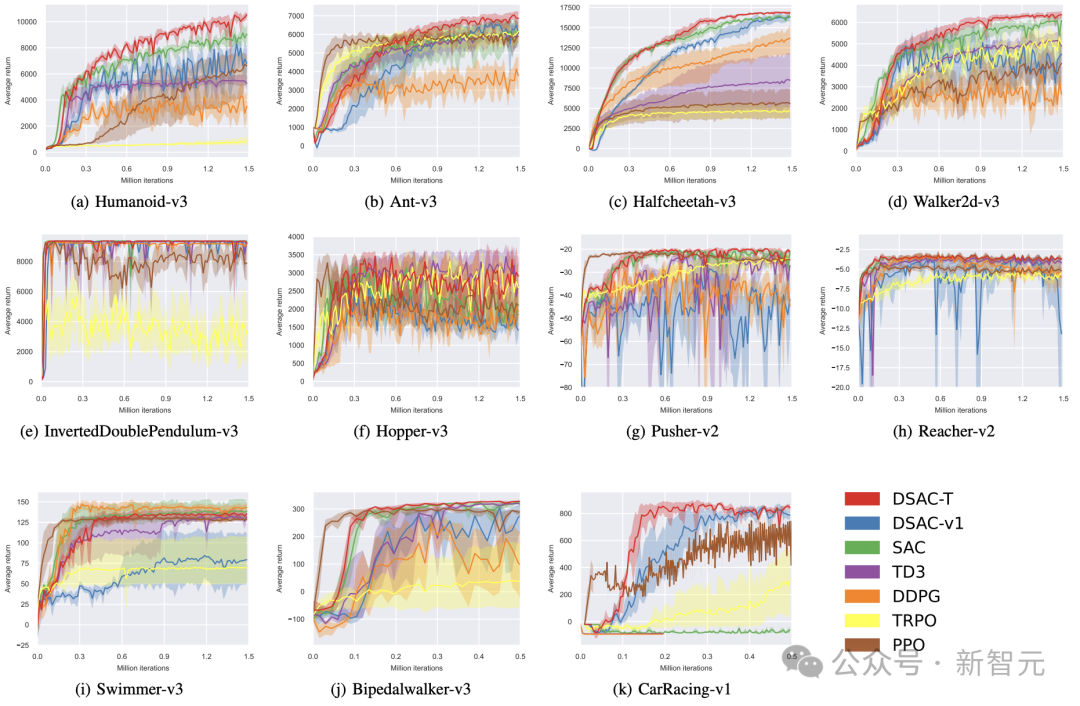
不同基准任务上的训练曲线
为保证强化学习训练效果的稳定性,团队提出了强化学习专用的神经网络优化器RAD。该优化器从动力学视角将神经网络参数优化建模为多粒子相对论系统演化,赋予参数独立自适应能力,确保训练长时域稳定与快速收敛。
相较于9个主流神经网络优化器,RAD优化器在12个测试环境及5种主流强化学习算法中综合性能均排名第一。特别在图像类标准测试环境Seaquest任务中,RAD性能达到当前流行的Adam优化器的2.5倍。
上述算法将逐步集成入团队开源的最优控制问题求解软件GOPS中。该软件以强化学习为核心理论,拥有完全自主知识产权,兼容多种机器人和工业仿真环境,能够有效地处理高维度、非线性、高动态等复杂场景的具身智能控制问题,目前已经应用于自动驾驶、物流机器人、特种作业机械臂、火箭回收等不同领域。
未来随着GOPS软件的进一步升级,现实世界的众多机器将可能拥有像人一样的智能,届时将迎来一个全新的具身智能时代。
DSAC和DSAC-T系列算法解读
⽽在时间差分学习中,这种估计误差⼜会被进⼀步放⼤,因为后⾯状态的过估计误差在更新过程中⼜会进⼀步传播到前⾯的状态中。
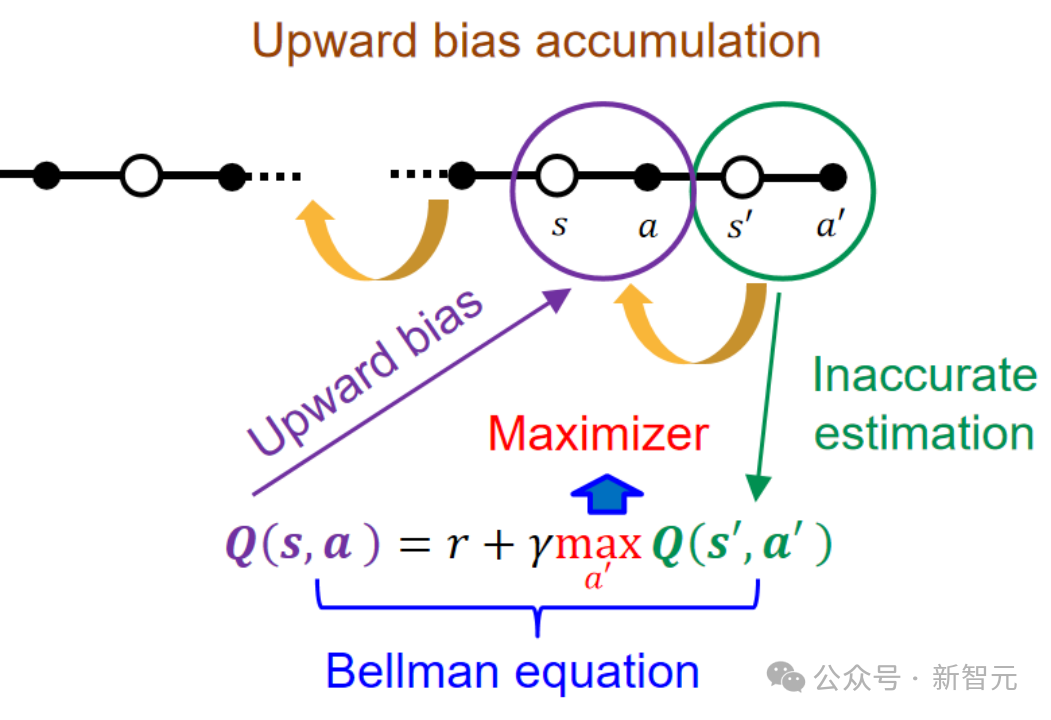
过估计原理
为了解决过估计问题,研究者提出著名的Double DQN算法及诸多以其为基础的变种,但是此类⽅法只能解决离散动作空间的问题。对于连续控制任务,以Clipped Double Q-learning为基础的TD3和SAC等算法则⾯临着低估问题。DSAC⾸次从理论层⾯发现和论证了分布式回报函数的学习降低Q值过估计的原理,并将分布式回报学习嵌⼊到Maximum Entropy架构中。

DSAC算法流程
事实上,⼈类⼤脑给出的奖励并不是⼀个单⼀的信号,⽽是基于某种概率分布,这也显示了分布式回报机制设计的合理性和巨⼤潜⼒。同时,与现有Distributional RL算法(如C51,IQN,D4PG等)不同的是,DSAC可以直接学习⼀个连续型分布式值函数,这避免了离散分布学习带来的⼈⼯设计分割区间需求。

Wikipedia简介:https://en.wikipedia.org/wiki/Distributional_Soft_Actor_Critic
DSAC算法是一种off-policy算法,可以通过学习连续的高斯值分布来有效提高值估计精度。然而DSAC算法也存在学习不稳定、参数敏感等缺点。
针对该问题,团队在DSAC算法的基础上进一步提出了DSAC-T: Distributional Soft Actor-Critic with Three Refinements算法。相较于DSAC,DSAC-T算法主要做了三方面改进:Expected value substituting、Twin value distribution learning与Variance-based critic gradient adjusting。
Expected value substituting:传统RL算法在策略评估阶段利用下一时刻的回报均值(即Q值)构建TD error,而DSAC算法参与critic更新时利用随机回报Z构建TD error,增加了critic更新梯度随机性,降低了学习稳定性。为此,DSAC-T利用随机回报Z和Q值的期望等价性,将值分布函数均值(即Q值)更新公式中下一时刻的随机回报替换为其均值,实现了算法性能提升。
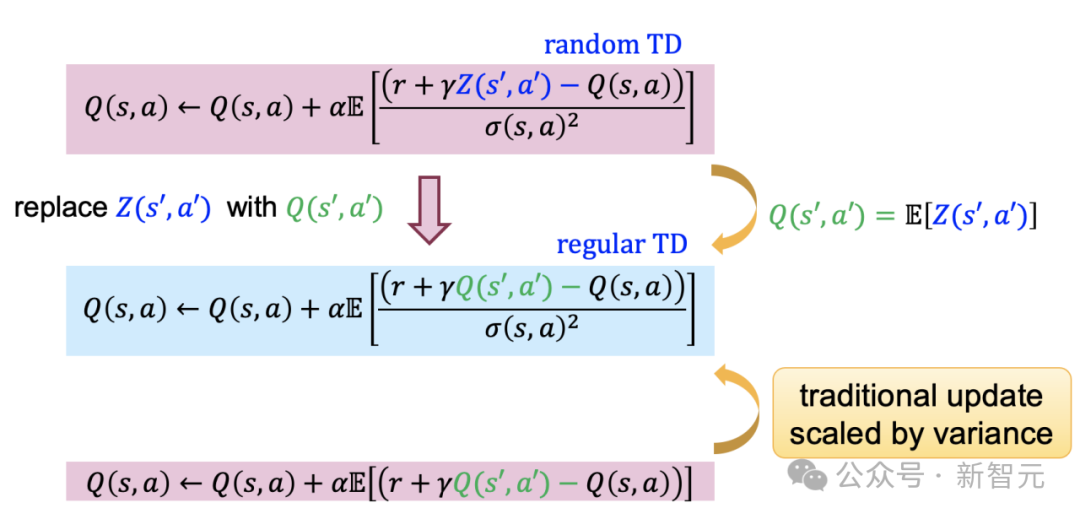
Expected value substituting
Twin value distribution learning:DSAC算法利用值分布学习极大抑制了过估计偏差,在此基础上,为进一步减轻值函数过估计偏差,DSAC-T结合douple-Q learning,在已有的值分布网络基础上额外独立训练了一个参数化的值分布网络。在进行actor和critic的梯度更新时,选择均值较小的值分布网络构建目标。
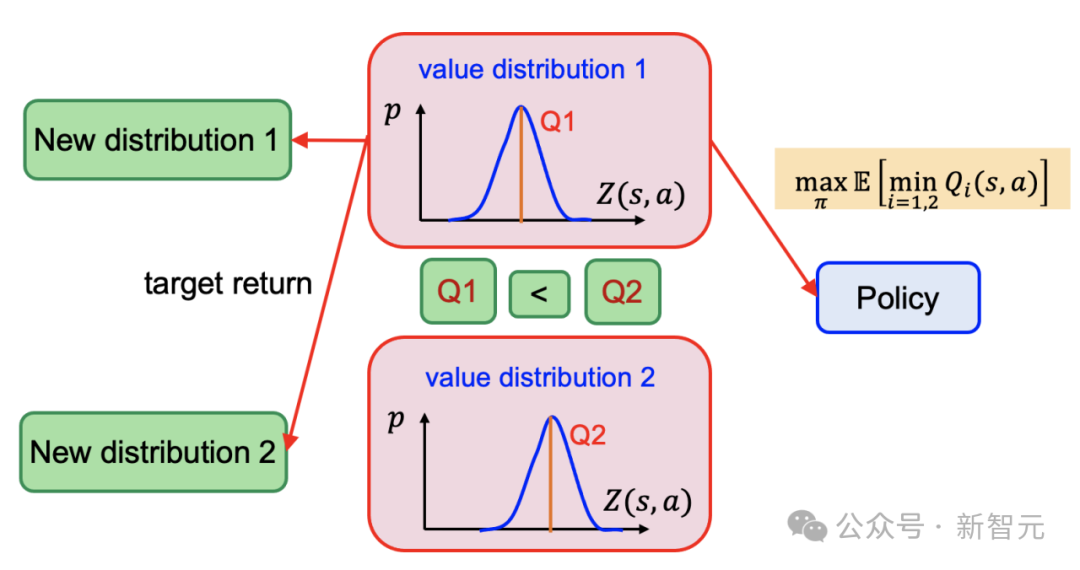
Twin value distribution learning
Variance-based critic gradient adjusting:为防止梯度爆炸,DSAC算法对随机TD error设置了固定的clipping boundary,该参数对任务reward量级极为敏感,严重依赖reward scaling的人工调校。
针对该问题,DSAC-T引入了方差相关的动态clipping boundary,实现了TD error边界的动态调节。此外,值分布函数更新梯度与值分布方差平方项/立方项成反比,导致了其学习过程对方差敏感。为此,DSAC-T引入gradient scaler降低方差变化对梯度的影响,进一步减小了算法对不同任务的参数敏感性。
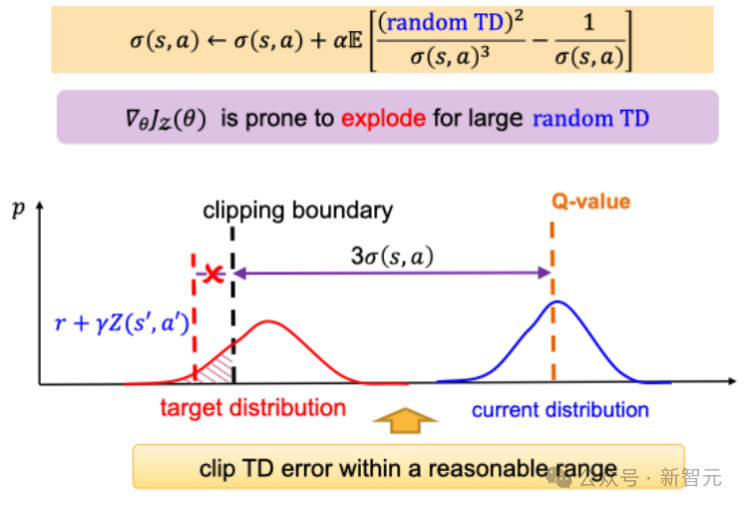
Variance-based critic gradient adjusting

论文代码:https://github.com/Jingliang-Duan/DSAC-v2
DACER算法解读
然而,扩散模型直接用于Online RL可能遇到的问题包括:1. 扩散模型的损失函数项本质上是一种模仿学习损失项,但与Offline RL不同,Online RL中并不存在可供模仿的数据;2. 扩散模型的反向过程无法进行解析求熵,这使得其难以与最大熵强化学习框架相结合,从而导致算法收敛性能不佳。
为了解决上述的问题,DACER(Diffusion Actor-Critic with Entropy Regulator)建立在去噪扩散概率模型(DDPM)的基础上。扩散模型的表示能力主要来源于反向扩散过程而非正向,因此将扩散模型的反向过程重新概念化为一种新的策略近似函数,利用其强大的表示能力来提升RL算法的性能。这个新策略函数的优化目标是最大化期望Q值。
在RL中,最大化熵对于策略探索至关重要,但扩散策略的熵难以解析确定。因此,算法选择在固定间隔处采样动作,并使用高斯混合模型(GMM)来拟合动作分布,可计算每个状态下策略的近似熵。这些熵的平均值之后被用作当前扩散策略熵的近似。最后,算法使用估计的熵来平衡扩散策略在训练过程中的探索与利用。
1. 扩散策略表征
将条件扩散模型的反向过程用作参数化策略
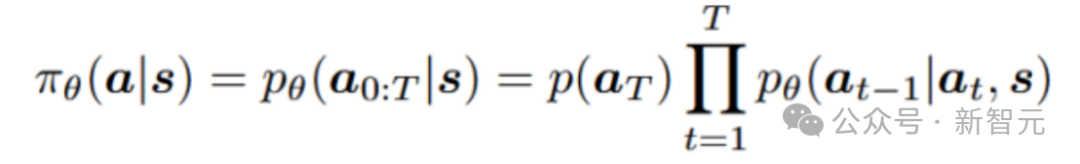
采样过程可以重新表述为:
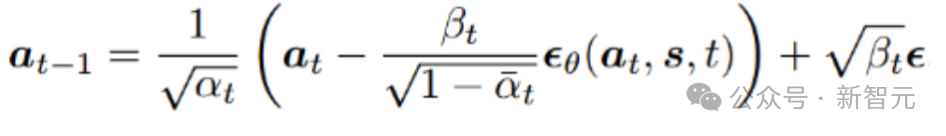
2. 扩散策略学习
在Online RL中,由于没有可供模仿的数据集,算法放弃了行为克隆项和模仿学习框架。策略学习的目标是最大化由扩散网络在给定状态下生成的动作的期望Q值:
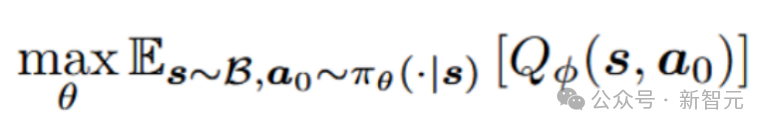
此外,算法使用先前提出的分布式Q学习的方法来缓解值函数的过估计问题。然而,直接使用上述扩散策略学习方法进行训练时,会因策略动作过于确定性而导致性能不佳。
3. 扩散策略与熵调节器
对于每个状态,我们使用扩散策略来采样N个动作,然后使用高斯混合模型(GMM)来拟合策略分布。可以通过以下方式估计对应于该状态的动作分布的熵:
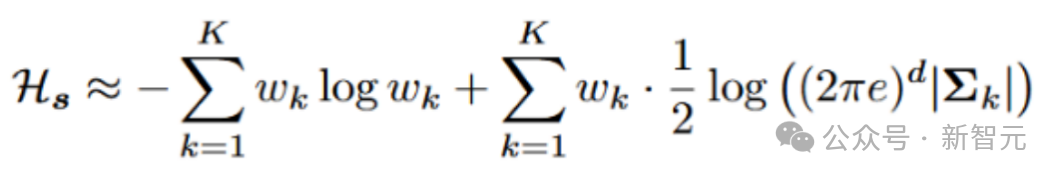
类似于最大化熵的RL,根据估计的熵学习一个参数α:
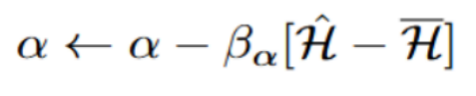
最终,使用下式在训练的采样阶段调整扩散策略的熵。熵调节机制是解锁探索潜能的关键。



论文链接:https://arxiv.org/pdf/2405.15177
RAD优化器解读
然而,目前主流的神经网络优化器(如SGD-M、Adam和AdamW等)虽然在缓解局部最优和加速收敛方面有所帮助,但其算法设计和参数选择均依赖于人工经验和实用技巧,缺乏对优化动态特性的解释与分析,难以从理论上保障RL训练的稳定性。
研究者从动力学视角出发,将神经网络参数的优化过程建模为多粒子相对论系统状态的演化过程,通过引入狭义相对论的光速最大原理,抑制了网络参数的异常更新速率,同时提供了各网络参数的独立自适应调节能力,从理论上引入了对RL训练稳定性和收敛性等动态特性的保障机制。
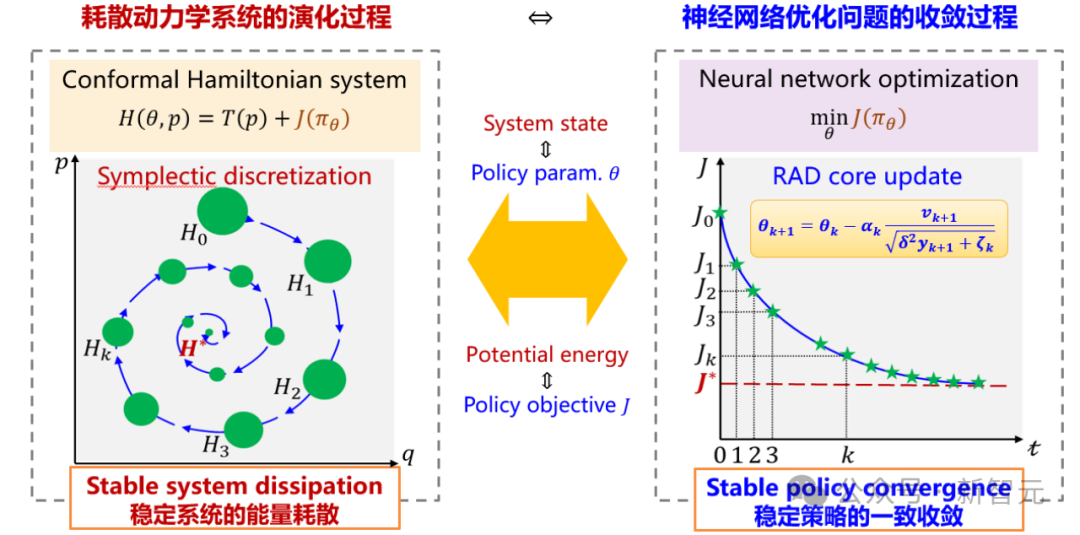
进而,研究者提出了既具备稳定动力学特性又适用于深度神经网络非凸随机优化的RAD优化器。特别的,当速度系数δ设为1且保辛因子ζk固定为小常数ε时,RAD优化器将退化为深度学习中广泛采用的Adam优化器。这一发现也为从动力学视角探究其他主流自适应梯度优化方法(如AdaGrad、NAdam、AdamW和Lion等)开辟了全新路径。

RAD算法流程

代码仓库:https://github.com/TobiasLv/RAD
GOPS软件简介
代码下载:https://github.com/Intelligent-Driving-Laboratory/GOPS



(文:新智元)