

如今,视觉语言模型(VLM)在学术界和工业界到处“开花”,用处特别多。但这也带来了新麻烦,因为模型架构各式各样、训练数据五花八门、应用场景千差万别,以前评估模型的老方法根本应付不过来,变得又复杂又容易出错。好在 VLMEvalKit 出现了,它把丰富的基准数据集、厉害的评估策略还有对好多流行模型的支持都整合到一起,就像是给混乱的评估工作找到了一把万能钥匙,成了多模态领域特别重要的评估工具。
一、项目概述
VLMEvalKit 是专门用来评测大型视觉语言模型(LVLMs)的开源工具包。有了它,在各种基准测试里评估大型视觉语言模型就变得简单多了,不用再费老大劲准备数据,只要轻松按个键就行。而且,它对模型生成的结果有两种评测方式,一种是精确匹配,直接看模型答案和标准答案一样不一样;另一种是用另一个语言模型来提取答案,分析得更深入,这样就能从不同角度把模型性能摸得透透的。

二、主要功能
1.广泛的基准数据集支持
VLMEvalKit里有30多个很有用的基准测试数据集,像 MMBench 系列、MME、MathVista、COCO Caption、OCR VQA、ScienceQA_IMG、DocVQA 等等。这些数据集用处可大了,能测试模型从看懂简单图像、视频,到理解复杂科学文献配图的各种能力。就拿 MMBench 系列来说,里面有好多关于图像问答、描述场景的高质量样本,能准确试试模型对图像内容理解得深不深,说话顺不顺溜。不管是看模型认不认识常见东西,还是能不能把图像描述得清楚明白,这些数据集都能给出合适的测试场景。
2.多样化的模型兼容性
它支持50多个HF模型和差不多100个视觉语言模型,不管是API模型,还是开源的PyTorch、HuggingFace 模型,像有名的LLaVA、InstructBLIP、IDEFICS 这些,它都能评估。就连最新的GPT – 4v、Gemini、QwenVLPlus等新模型,它也能马上跟上支持。这就意味着,不管你是搞学术研究,钻研新模型,还是在工业上用商业化模型干活,VLMEvalKit 都能帮你看看自己用的模型跟别人的比起来咋样。
3.灵活的评估策略
VLMEvalKit 用生成式评估策略考察所有 LVLM,还提供两种评价方法让你选。精确匹配很直接,就像批改作业一样,把模型答案和标准答案一对比,答案明确的任务,像给图像打个简单标签,用这个方法一下就能看出对错。另一种是基于 LLM 的答案提取,这就高级一点,借助另一个语言模型,把原始模型输出的答案再分析一遍,提取出有用信息。要是碰到开放性问题,像让模型描述一幅复杂的艺术画,这种方法就能把模型到底水平咋样估摸得更准。
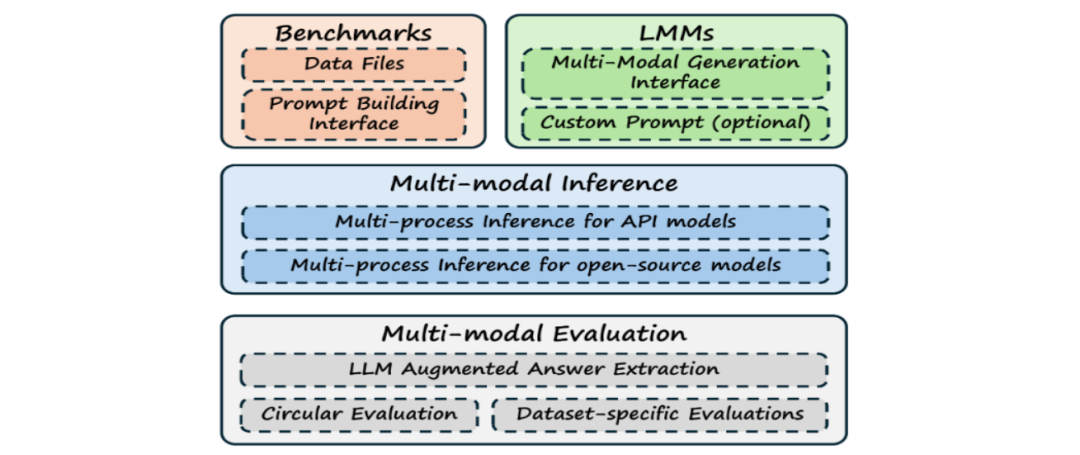
三、核心优势
1.一站式评估体验
以前评估视觉语言模型可麻烦了,要在好多工具、平台换来换去,又费时间又容易出错,数据格式不一样、工具衔接不好这些问题一堆。VLMEvalKit 把数据集管理、模型加载、指标计算这些事都弄到一个框架里,你只要简单配置一下,按个键就能快速评估好多基准数据集。这么一来,评估效率大大提高,那些因为工具换来换去、数据格式不对带来的错误也少了,评估工作就像上了高速公路,又快又顺又准。
2.便捷的操作界面
它设计了简单好用的命令行操作方式,就算你不太会编程,也能很快上手。只要设置几个简单参数,像告诉它模型在哪、用哪个数据集评估、选哪种评价方式,就能轻松让评估流程跑起来。这种简单的设计,让更多人能参与到视觉语言模型的研究开发里来,大家一起使劲,技术更新就更快了。
3.高度的灵活性与可定制性
在评估策略上,你可以根据任务需求和模型特点,随便选精确匹配还是基于 LLM 的答案提取,还能微调一些细节参数,让评估效果达到最好。在数据集选择上,既可以用它自带的标准数据集,这些数据集都很靠谱;要是你有特殊需求,也能方便地导入自己的数据集。不管你是专注某个专业领域评估模型,还是探索新任务,VLMEvalKit 都能给你合适的支持。
四、应用场景
1.教育领域
在智能教育辅助系统里,VLMEvalKit 能帮我们看看视觉语言模型能不能理解教材图片、教学视频。比如数学课本上有几何图形问题,模型得像个老师一样,明白图形特点、关系,学生提问了,能讲得清楚。用 VLMEvalKit 评估一下,就能挑出好用的模型,让教育资源变好,学生学知识更容易。
2.智能客服
电商、金融这些行业的智能客服,经常收到客户发的图片、视频,像产品坏了的照片、操作视频啥的。视觉语言模型得赶紧看懂,还得回答准。VLMEvalKit 就像个裁判,能评估客服模型性能,保证它们能处理好多媒体信息,让客户满意,减轻人工客服压力。
3.科学研究
在科学文献阅读辅助工具开发中,VLMEvalKit 可以衡量模型对科研论文里图表、实验图像的解读能力。科研人员靠评估好的模型,能更快明白复杂实验数据、趋势,研究就快了。在生物医学、天文学这些要看大量图像的领域,VLMEvalKit 能帮着选出最适合的模型,让科研更顺。
4.文档自动化
企业办公自动化有好多文档要处理,有些还带图片、图表。视觉语言模型能帮忙分类、提取信息。VLMEvalKit 通过评估模型处理文档的性能,帮企业选出最好的模型,办公效率提高了,人力成本也降下来了。
五、快速使用
1、安装和设置必要的密钥
安装
-
克隆VLMEvalKit仓库:`git clone https://github.com/open-compass/VLMEvalKit.git`
-
进入仓库目录:`cd VLMEvalKit`
-
安装VLMEvalKit:`pip install -e .`
设置密钥
-
使用API模型进行推理或使用LLM API作为评判者或选择提取器时,需要设置API密钥。
-
可以将密钥放在`$VLMEvalKit/.env`文件中,或直接设置为环境变量。
-
示例`.env`文件内容:
# .env 文件,将其放置在 $VLMEvalKit 下# 专有 VLMs 的 API 密钥# QwenVL APIsDASHSCOPE_API_KEY=# Gemini w. Google Cloud BackendsGOOGLE_API_KEY=# OpenAI APIOPENAI_API_KEY=OPENAI_API_BASE=# StepAI APISTEPAI_API_KEY=# REKA APIREKA_API_KEY=# GLMV APIGLMV_API_KEY=# CongRong APICW_API_BASE=CW_API_KEY=# SenseChat-V APISENSECHAT_AK=SENSECHAT_SK=# Hunyuan-Vision APIHUNYUAN_SECRET_KEY=HUNYUAN_SECRET_ID=# 你可以设置一个评估时代理,评估阶段产生的 API 调用将通过这个代理进行EVAL_PROXY=
在对应键值空白处填写密钥,这些API密钥将在进行推理和评估时自动加载。
2、检查配置
-
所有VLMs都在`vlmeval/config.py`中配置。
-
对于某些VLMs(如MiniGPT-4、LLaVA-v1-7B),需要额外的配置(在配置文件中配置代码/模型权重根目录)。
-
在评估时,使用`vlmeval/config.py`中`supported_VLM`指定的模型名称来选择VLM。
-
确保在开始评估之前,可以成功使用VLM进行推理,使用命令`vlmutil check {MODEL_NAME}`。
3、开始评测
使用`run.py`进行评估
1)参数:
-
`–data (list[str])`: 设置在VLMEvalKit中支持的数据集名称。
-
`–model (list[str])`: 设置在VLMEvalKit中支持的VLM名称。
-
`–mode (str, 默认值为‘all’, 可选值为[‘all’, ‘infer’])`: 当mode设置为“all”时,将执行推理和评估;当设置为“infer”时,只执行推理。
-
`–nproc (int, 默认值为4)`: 调用API的线程数。
-
`–work-dir (str, default to ‘.’)`: 存放测试结果的目录。
-
`–nframe (int, default to 8)`: 从视频中采样的帧数,仅对视频多模态评测集适用。
-
`–pack (bool, store_true)`: 一个视频可能关联多个问题,如`pack==True`,将会在一次询问中提问所有问题。
2)用于评测图像多模态评测集的命令
使用`python`或`torchrun`来运行脚本:
# 使用 `python` 运行时,只实例化一个 VLM,并且它可能使用多个 GPU。# 这推荐用于评估参数量非常大的 VLMs(如 IDEFICS-80B-Instruct)。# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-80B-Instruct 进行推理和评估python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-80B-Instruct 仅进行推理python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose --mode infer# 使用 `torchrun` 运行时,每个 GPU 上实例化一个 VLM 实例。这可以加快推理速度。# 但是,这仅适用于消耗少量 GPU 内存的 VLMs。# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-9B-Instruct、Qwen-VL-Chat、mPLUG-Owl2。在具有 8 个 GPU 的节点上进行推理和评估。torchrun --nproc-per-node=8 run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct qwen_chat mPLUG-Owl2 --verbose# 在 MME 上使用 Qwen-VL-Chat。在具有 2 个 GPU 的节点上进行推理和评估。torchrun --nproc-per-node=2 run.py --data MME --model qwen_chat --verbose
3)用于评测视频多模态评测集的命令
使用`python`运行时,只实例化一个VLM,并且它可能使用多个GPU。
# 在MMBench-Video上评测IDEFCIS2-8B, 视频采样8帧作为输入,不采用pack模式评测torchrun --nproc-per-node=8 run.py --data MMBench-Video --model idefics2_8b --nframe 8# 在MMBench-Video上评测GPT-4o (API模型), 视频采样16帧作为输入,采用pack模式评测python run.py --data MMBench-Video --model GPT4o --nframe 16 --pack
评估结果将作为日志打印出来,结果文件也会在目录`$YOUR_WORKING_DIRECTORY/{model_name}`中生成,以`.csv`结尾的文件包含评估的指标。
4、部署本地语言模型作为评判 / 选择提取器
默认设置使用OpenAI的GPT作为评判LLM,也可以使用LMDeploy部署本地评判LLM。
安装LMDeploy:
pip install lmdeploy openai部署本地评判LLM:
lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333获取由LMDeploy注册的模型名称:
from openai import OpenAIclient = OpenAI(api_key='sk-123456',base_url="http://0.0.0.0:23333/v1")model_name = client.models.list().data[0].id
配置对应环境变量,以告诉VLMEvalKit如何使用本地评判LLM:
OPENAI_API_KEY=sk-123456OPENAI_API_BASE=http://0.0.0.0:23333/v1/chat/completionsLOCAL_LLM=<model_name you get>
运行第2步中的命令,使用本地评判LLM来评估VLM。
注意事项:
-
如果希望将评判LLM部署在单独的一个GPU上,并且由于GPU内存有限而希望在其他GPU上评估VLM,可以使用`CUDA_VISIBLE_DEVICES=x`这样的方法。
-
如果本地评判LLM在遵循指令方面不够好,评估过程可能会失败,请通过issues报告此类失败情况。
-
可以以不同的方式部署评判LLM,例如使用私有LLM(而非来自HuggingFace)或使用量化LLM,具体参考LMDeploy doc文档。
六、结语
VLMEvalKit 作为开源的视觉语言模型评估工具包,功能强、优势多、应用广,给多模态人工智能发展加了大马力。它解决了评估模型的好多难题,操作简单,社区活跃,让技术门槛变低,大家能共享知识、创新技术。以后视觉语言模型肯定还会发展,VLMEvalKit 也会跟着进步,帮我们探索多模态智能的更多可能。不管你是刚接触多模态领域的新手,还是经验老到的专家,都值得好好研究、用用 VLMEvalKit。
七、项目地址
项目地址:https://github.com/open-compass/VLMEvalKit
论文地址:https://arxiv.org/html/2407.11691v2
(文:小兵的AI视界)
哇塞,这个VLMEvalKit简直就是视觉语言模型评估界的神器!操作起来so方便,功能so强大,完全没让人觉得卡顿。尤其是它支持那么多不同的模型和场景,简直是为我量身定制的工具了。如果能再多加一些交互界面优化,简直可以称为全能型评估大师啦!