
后训练:基础模型上的大规模强化学习
-
直接将强化学习 (RL) 应用于基础模型,而无需依赖监督微调 (SFT) 作为初步步骤。这种方法允许模型探索解决复杂问题的思路 (CoT),从而开发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展示了自我验证、反思和生成长 CoT 等功能,标志着研究界的一个重要里程碑。值得注意的是,这是第一个公开研究,验证了 LLM 的推理能力可以纯粹通过 RL 来激励,而无需 SFT。
-
引入了用于开发 DeepSeek-R1 的流水线。该流水线包含两个 RL 阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个 SFT 阶段,作为模型推理和非推理能力的种子。
蒸馏:小模型同样强大
-
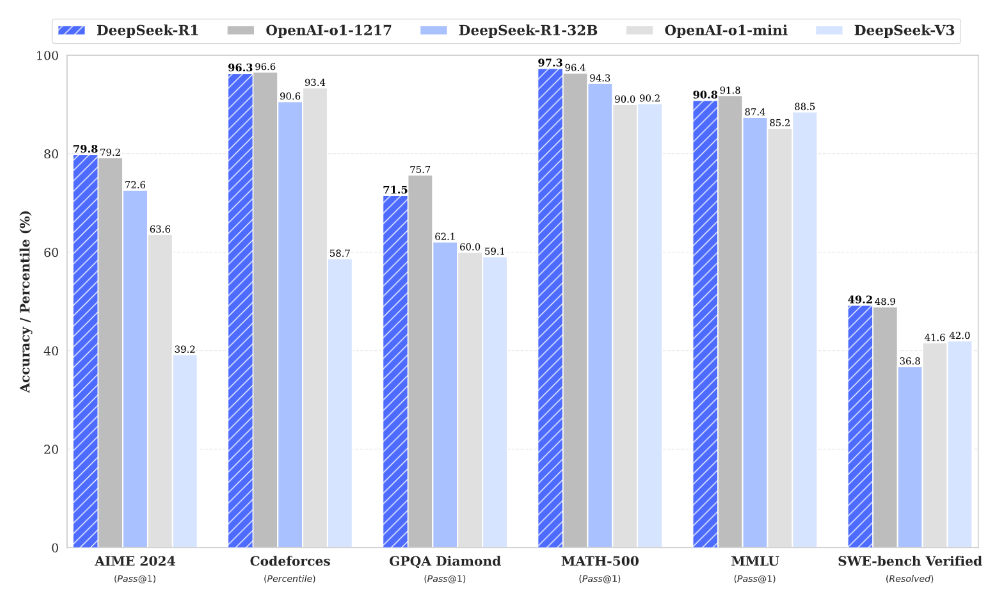
证明了较大模型的推理模式可以提炼为较小的模型,与通过强化学习在小型模型上发现的推理模式相比,其性能更佳。开源的 DeepSeek-R1 及其 API 将有利于研究界在未来提炼出更好的小型模型。
-
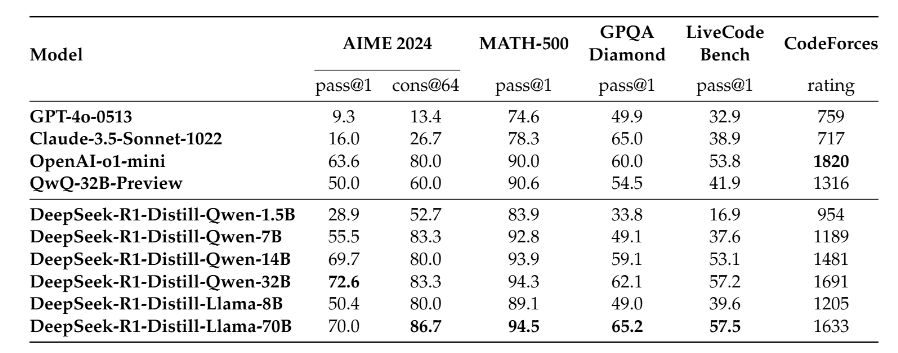
利用 DeepSeek-R1 生成的推理数据,对研究社区中广泛使用的多个稠密模型进行了微调。评估结果表明,经过提炼的较小稠密模型在基准测试中表现优异,超越OpenAI-o1-mini。向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B checkpoints 。
https://github.com/deepseek-ai/DeepSeek-R1/blob/dev/DeepSeek_R1.pdf
(文:PaperAgent)
这不就是让 inferior 小模型装逼吗?