

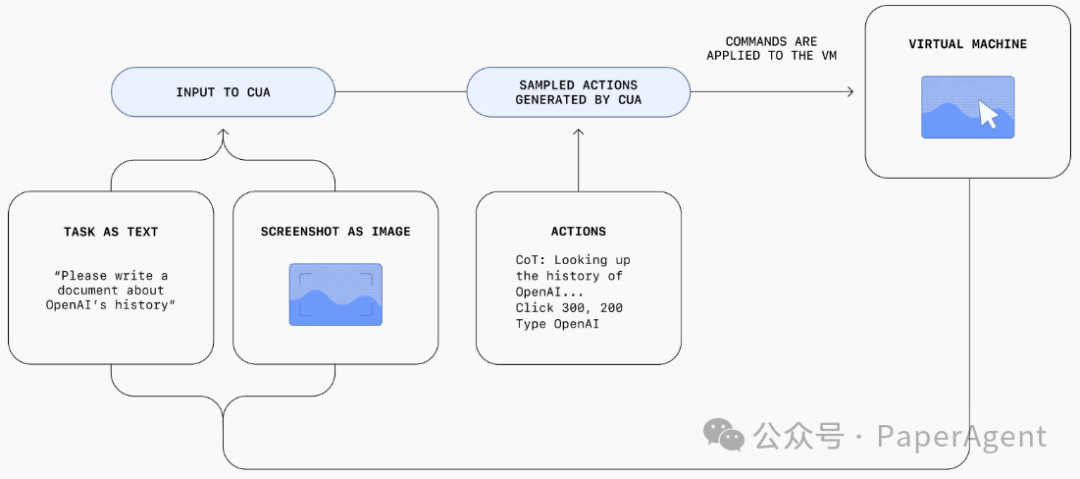
那么构建一个开源Computer-Using Agent,需要解决哪些技术挑战尼?
-
安全性:将操作系统隔离在安全、受控的环境中
-
点击事物:使人工智能能够精确点击以操纵 UI 元素
-
推理:让人工智能根据所见决定下一步做什么(或何时停止)
-
部署 LLM:以经济高效的方式托管开源模型
-
流式显示:寻找一种低延迟的方式来显示和录制沙箱视频
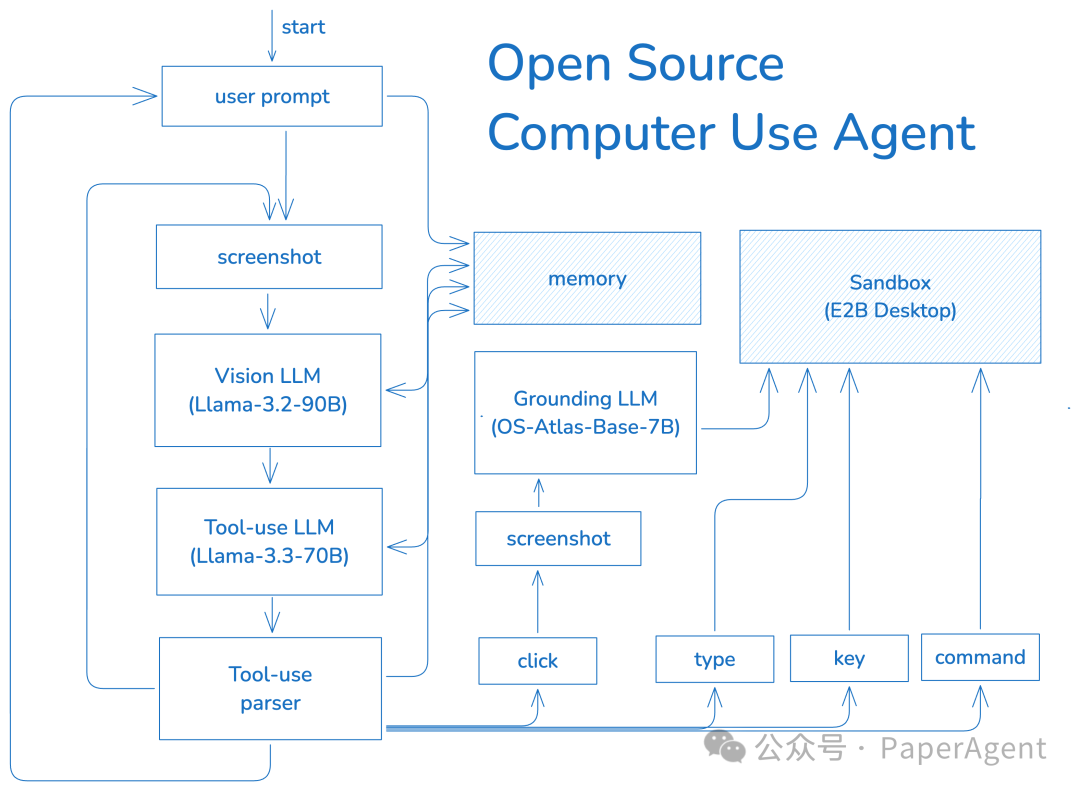
挑战一:安全
运行 AI Agent的理想环境应该易于使用、性能高且安全。让 AI Agent直接访问您的个人计算机和文件系统非常危险!它可能会删除文件或执行其他不可逆的操作。
挑战二:点击事物
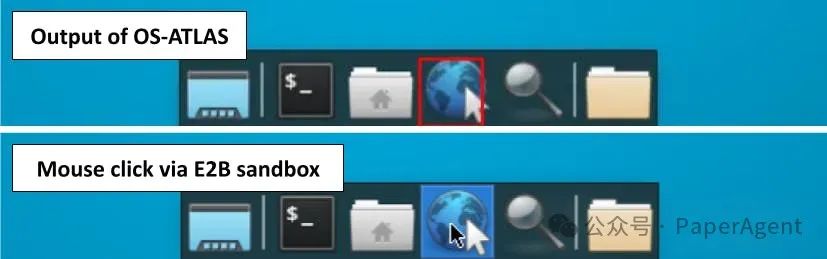
挑战3:推理

基于 LLM 的Agent的强大之处在于它们可以在多个动作之间做出决定,并使用最新的信息做出明智的决策。
在过去的一年里, LLM 做出这些决定的能力逐渐增强。第一种方法是简单地提示 LLM 以给定的文本格式输出操作,并在再次调用 LLM 之前将操作结果添加到聊天历史记录中。所有后续方法大致相同,使用微调来补充系统提示,这种通用能力被称为函数调用。
在单个 LLM 调用中结合视觉来指导工具使用可以尝试的开源模型:
-
Llama-3.2-90B-Vision-Instruct:查看沙盒显示,并决定下一步要采取的步骤
-
Llama 3.3-70B-Instruct:根据 Llama 3.2 做出决定,并以工具使用格式重新表述
-
OS-Atlas-Base-7B:是一个工具,Agent可以根据提示调用该工具来执行点击操作
挑战 4:部署LLM
Agent运行速度要快,所以在云端运行 LLM 推理,还希望它能够提供开箱即用的功能。
Llama 3.2 和 3.3以及OpenRouter、Fireworks AI 和官方 Llama API 都是不错的选择。
挑战 5:流式显示
为了查看 AI 正在做什么,希望从沙盒的屏幕获取实时更新。
ffmpeg -f x11grab -s 1024x768 -framerate 30 -i $DISPLAY -vcodec libx264 -preset ultrafast -tune zerolatency -f mpegts -listen 1 http://localhost:8080ffmpeg -reconnect 1 -i http://servername:8080 -c:v libx264 -preset fast -crf 23 -c:a aac -b:a 128k -f mpegts -loglevel quiet - | tee output.ts | ffplay -autoexit -i -loglevel quiet -这在互联网上工作得很好。服务器是 FFmpeg 的某种内置功能,但有一个限制,即它一次只能向一个客户端传输数据。因此,客户端必须使用 tee 命令来分割数据流,以便可以保存和显示它。
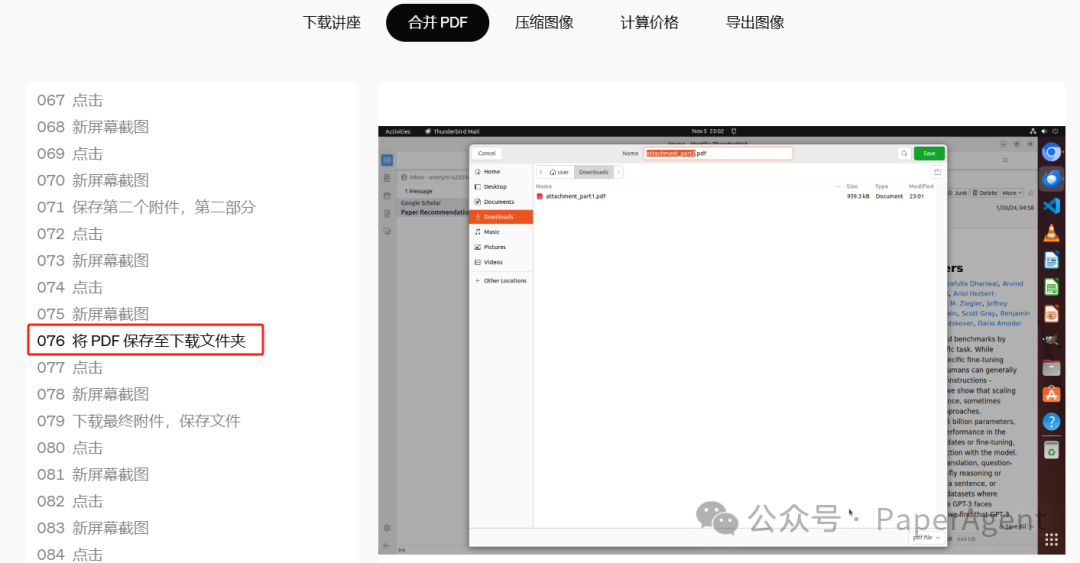
OpenAI智能体Operator合并PDF的任务执行全流程


https://blog.jamesmurdza.com/how-i-taught-an-ai-to-use-a-computerhttps://openai.com/index/computer-using-agent/
(文:PaperAgent)
AI 强者,国内智谱和清华UI-TARS都太差了,OpenAI才是硬道理!