
当硅谷巨头用万卡集群堆砌算力高墙时,一群中国极客用2048块低端GPU改写了游戏规则。

算力困局下的「厨房革命」
高昂的芯片价格和惊人的能源消耗,正将人工智能变成一场少数巨头才能参与的烧钱游戏。
英伟达H100芯片价格突破4.5万美元,OpenAI单日电费高达70万美元,全球AI竞赛似乎陷入「算力军备竞赛」的怪圈。但在这个看似固化的战场边缘,DeepSeek用557.6万美元的训练成本,在2048块被硅谷淘汰的A100芯片上,跑出了对标GPT-4o的模型——这个数字仅是谷歌训练同类模型耗资的1/200。
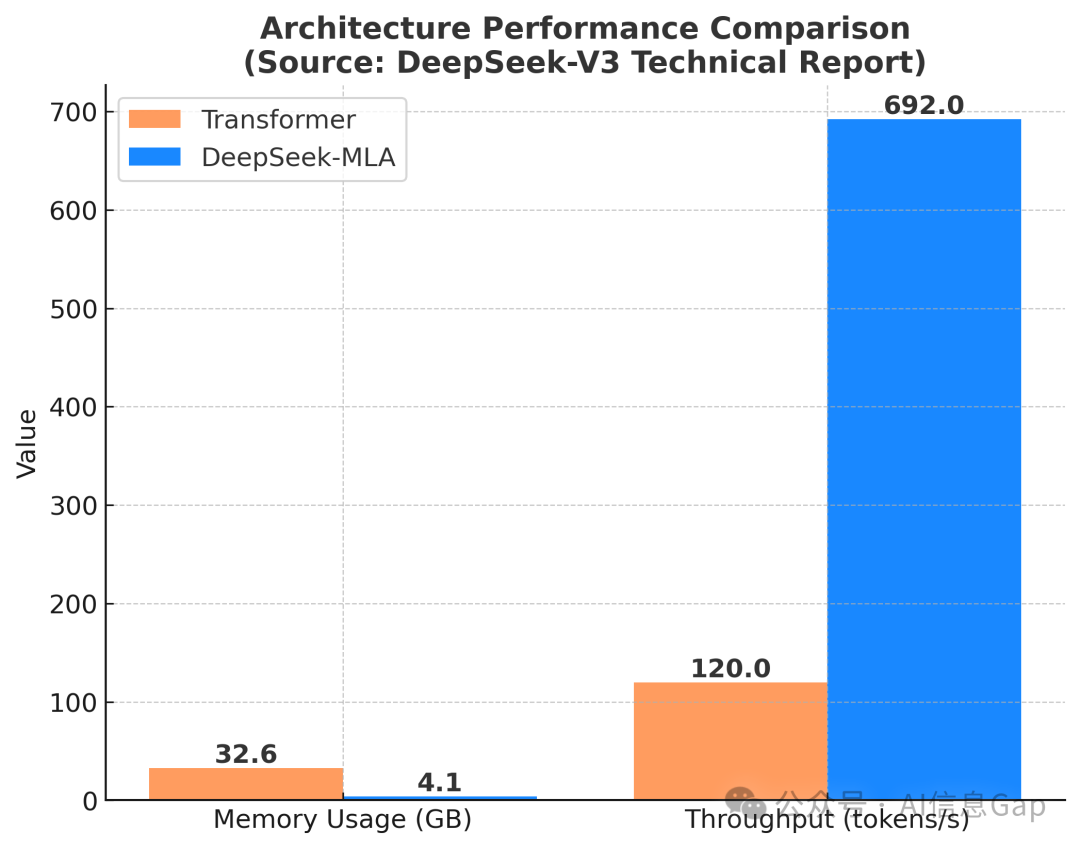
「好厨师不该抱怨灶台」——梁文锋在内部技术文档中的这句批注,成为这场「厨房革命」的最佳注脚。当美国切断高端芯片供应,他们用动态张量并行技术将显存占用压缩至传统架构的13% ,就像顶级大厨用普通菜刀雕出满汉全席,将有限的资源利用到了极致。
颠覆规则的四大「中国解法」
1. 注意力机制的量子纠缠
DeepSeek-V3所采用的MLA(多维度潜在注意力) 架构通过巧妙的拆解和组合,让每个token处理成本降至0.0003美元,这是全球首个实现「注意力自由」的模型。MLA的秘密在于将传统72头注意力拆解为1024个「微注意力单元」,如同把探照灯换成萤火虫矩阵,在降低能耗的同时实现全景覆盖。
2. 内存炼金术
DeepSeek自研的梯度累积策略,让单卡可训练参数量突破240亿。这相当于在10平米房间塞进整个图书馆——不是靠压缩书架,而是发明了「可折叠知识载体」,一种更高效的知识存储和调用方法。
3. 数据蒸馏工厂
用自研的「知识提纯」算法,从万亿token中萃取出价值密度最高的3%。就像从长江取一瓢饮,但这瓢水必须包含青藏雪山的纯净、三峡的激荡、入海口的包容。
4. 开源武器化
当OpenAI将API调用费设为0.03美元/千token,DeepSeek直接开源模型权重,并附上53页「烹饪手册」。这种「开放且自信」的“降维打击”让全球开发者自发成为其技术布道者,形成指数级扩张的创新生态。
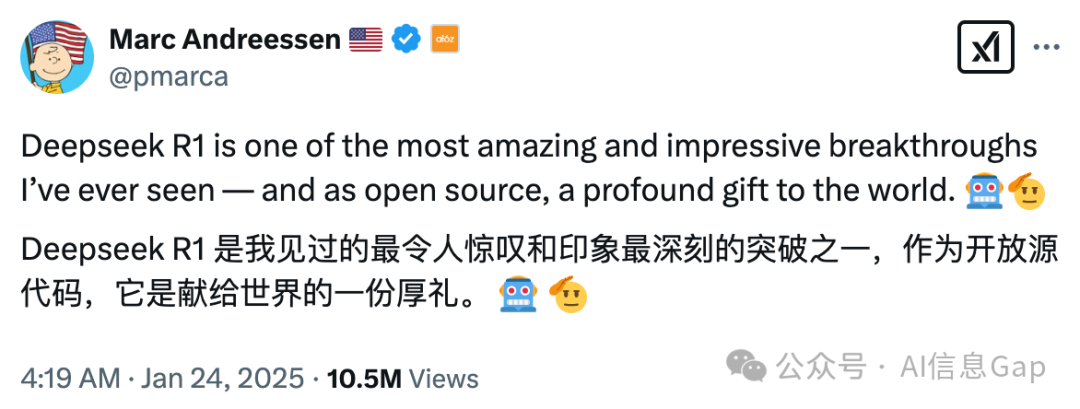
著名风投a16z的联合创始人马克·安德森(Marc Andreessen)对此评价道:“DeepSeek-R1是我见过的最令人惊叹、最令人印象深刻的突破之一,作为开源模型,它是献给世界的一份厚礼。”
随后,他又补充:“DeepSeek-R1是AI的“斯普特尼克时刻”。”
极客军团的「反内卷」人才观
「我们不需要AI神童,只需要会解数学题的年轻人」——在DeepSeek2024校招海报上,这句掷地有声的宣言击中了所有被大厂算法题虐哭的毕业生。DeepSeek的应届生培养体系像极了武侠小说中的「珍珑棋局」,看似无解,实则暗藏玄机,旨在发掘真正的高手。
-
第1月:手写反向传播算法,禁用任何深度学习框架 -
第3月:在单机环境下复现 GPT-2架构 -
第6月:用100块GPU完成千亿参数模型训练
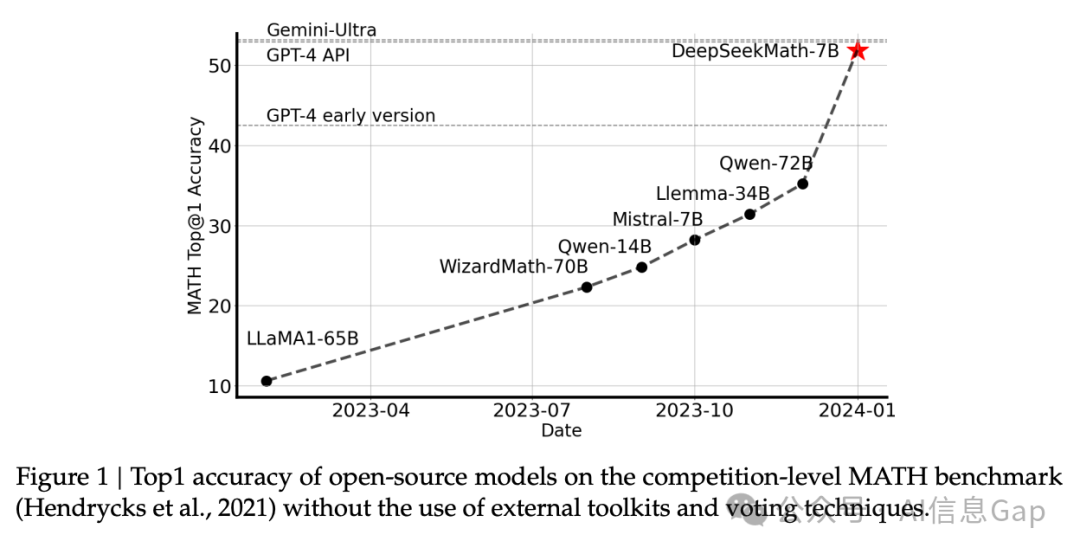
这种「自废武功」式的训练,让DeepSeek团队在2024年国际数学推理大赛中,用7B小模型击败谷歌280B参数的Gemini Ultra,上演了一场“蚂蚁撼大象”的奇迹。
DeepSeek启示录:AI新篇章
1. 效率优先主义崛起
DeepSeek-V3的单位算力性能达到OpenAI的17倍,这预示着AI竞赛将从「堆芯片」转向「拼算法」。就像燃油车时代过渡到电动车,马力不再是唯一指标。
2. 软件定义硬件的逆袭
DeepSeek用CUDA替代方案将A100芯片利用率提升至92% ,这记「化骨绵掌」让价值10亿美元的H100集群相形见绌。未来算力市场的定价权,可能从芯片厂转移到算法工程师手中。
3. 寒武纪大爆发前夜
当训练成本降至百万美元级,全球已涌现327个开源大模型,AI正在真正进入一个百花齐放的时代。这像极了寒武纪生命大爆发——当生存门槛降低,奇点进化将呈现指数级绽放。
结语:算力霸权的黄昏
当DeepSeek团队用“游戏显卡”跑出GPT-4级别模型时,他们不仅证明了工程创新的力量,更昭示着一个崭新时代的来临:在这个时代,算力将像电力一样普惠,而真正的护城河,永远是人类对未知永不停歇的好奇。
「所有伟大的创新,都始于对现状的不合理拆解」——DeepSeek展示厅里那台被拆装37次的飞跃牌收音机,仍在无声讲述着这个真理。
算力霸权终将落幕,而创新的时代,才刚刚开始。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)