

RAG 系统的搭建与优化是一项庞大且复杂的系统工程,通常需要兼顾测试制定、检索调优、模型调优等关键环节,繁琐的工作流程往往让人无从下手。
近日,针对以上痛点,清华大学 THUNLP 团队联合东北大学 NEUIR 、面壁智能及 9#AISoft 团队共同推出了 UltraRAG 框架,该框架革新了传统 RAG 系统的开发与配置方式,极大降低了学习成本和开发周期。UltraRAG 不仅具备满足专业用户需求的“单反相机”级精细化配置能力,同时也提供类似“卡片机”的一键式便捷操作,让 RAG 系统的构建变得极简且高效。
更重要的是,相比传统 RAG 系统,UltraRAG 支持自动化地将模型适配到用户提供的知识库,有效避免了在“模型选型”时的反复纠结;同时,其 模块化设计 又能为科研需求快速赋能,帮助研究者在多种场景下自由组合、快速迭代。通过 UltraRAG,用户可以轻松完成从数据到模型的全流程管理,不论是要开展深度科研探索,还是进行快速业务落地,都能“随心所欲,得心应手”。

Github 地址:
https://github.com/OpenBMB/UltraRAG
UltraRAG 以其极简的 WebUI 作为核心优势之一,即便是无编程经验的用户,也能轻松完成 模型的构建、训练与评测。无论是快速开展实验,还是进行个性化定制,UltraRAG 均能提供直观且高效的支持。该框架集成了多种预设工作流,用户可根据具体需求灵活选择最优路径,无需编写繁琐代码,即可完成从数据处理到模型优化的全流程操作。
以下是操作演示:

UltraRAG 以自研的 KBAlign、DDR 等方法为核心,提供一键式系统化数据构建,结合检索与生成模型的多样化微调策略,助力性能全面优化。在数据构造方面,UltraRAG 覆盖从检索模型到生成模型的全流程数据构建方案,支持基于用户导入的知识库自动生成训练数据,显著提升场景问答的效果与适配效率。在模型微调方面,UltraRAG 提供了完备的训练脚本,支持 Embedding 模型训练及 LLM 的 DPO/SFT 微调,帮助用户基于数据构建更强大、更精准的模型。
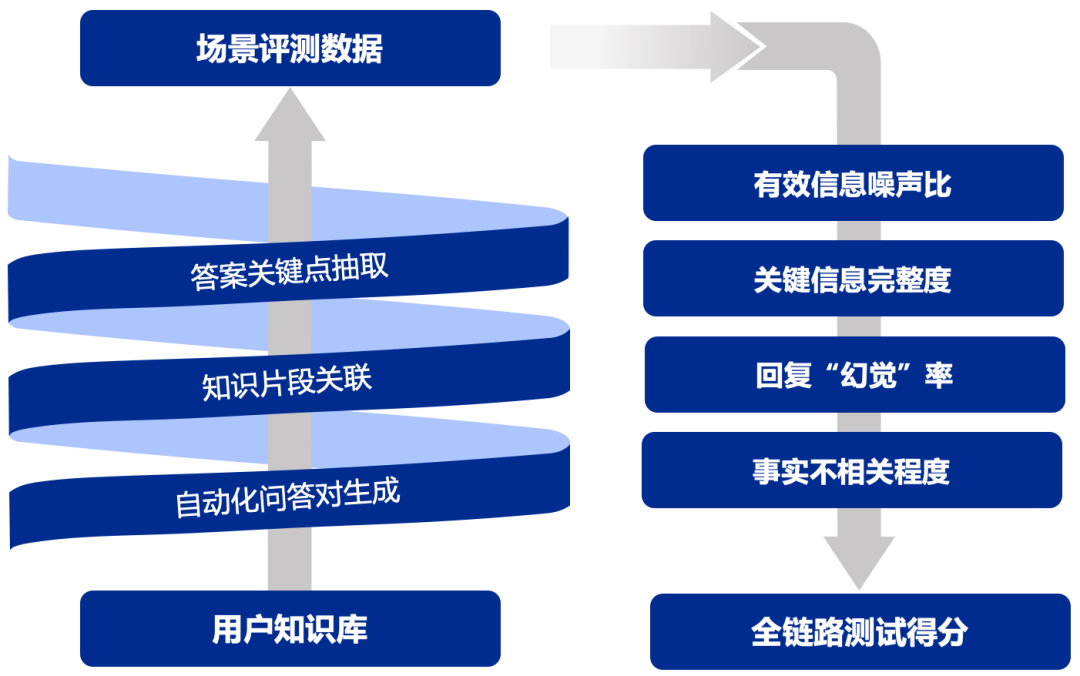
UltraRAG 以自研的 UltraRAG-Eval 方法为核心,融合针对有效与关键信息的多阶段评估策略,显著提升模型评估的稳健性,覆盖从检索模型到生成模型的多维评估指标,支持从整体到各环节的全面评估,确保模型各项性能指标在实际应用中得到充分验证。通过关键信息点锚定,UltraRAG 有效增强评估的稳定性与可靠性,同时提供精准反馈,助力开发者持续优化模型与方法,进一步提升系统的稳健性与实用性。
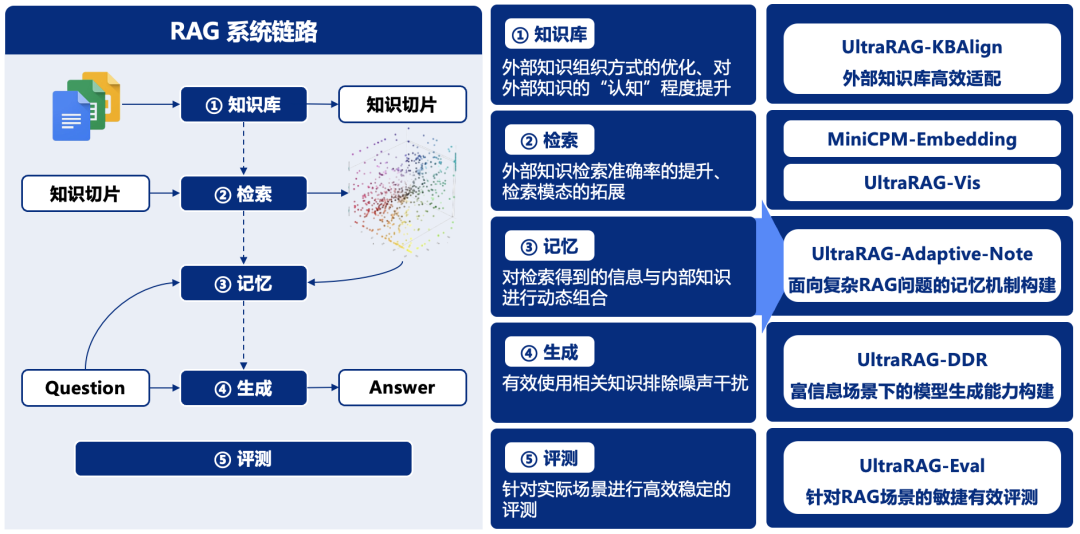
UltraRAG 内置 THUNLP-RAG 组自研方法及其他前沿 RAG 技术,支持整个模块化的持续探索与研发。UltraRAG 不仅是一个技术框架,更是科研人员与开发者的得力助手,助力用户在多种任务场景中高效寻优。随着功能的不断完善与升级,UltraRAG 将在更广泛的领域和应用场景中发挥关键作用,持续拓展 RAG 技术的应用边界,推动从学术研究到商业应用的全面发展。其 简洁、高效、灵活且易于上手 的特性,使 RAG 框架的部署与应用更加便捷,显著降低科研与项目开发的技术复杂度,帮助用户专注于创新与实践。
UltraRAG 系列引入多项创新技术,优化了检索增强生成中的知识适配、任务适应和数据处理,提升了系统的智能性和高效性。
-
UltraRAG-KBAlign: 提升大语言模型自适应知识库的能力,优化知识检索与推理过程。2.4B 模型通过自标注达到 GPT-4o 的标注性能,并在多个实验中超越 GPT-4o 本身。
-
UltraRAG-Embedding: 出色的中英文检索能力,支持长文本与稀疏检索。性能超过 bge-m3 10%。
-
UltraRAG-Vis:提出了纯视觉的 RAG Pipeline,通过引入 VLMs 对文档进行编码,避免了文档解析造成的信息丢失,相比传统 Text RAG Pipeline,部分任务在端到端性能上提升 25-39%。
-
UltraRAG-Adaptive-Note:通过动态记忆管理和信息收集,提升复杂问答任务中的解答质量。在 GPT-3.5-turbo、Llama3-8B、Qwen2-7B 等多个前沿模型上实验表明,自适应地动态记忆管理和信息收集策略相较基础检索增强生成模型可实现 3%~13.9% 的性能提升,并且尤其擅长处理具有复杂信息检索需求的问题。
-
UltraRAG-DDR:基于可微调数据奖励 (DDR) 优化检索增强生成,提升任务特定场景的系统性能。在 MiniCPM-2.4B、Llama3-8B 等多个前沿模型上实验表明,DDR 优化策略相较原始检索增强生成模型可实现 7% 以上性能提升。
-
UltraRAG-Eval:针对 RAG 场景设计的高效评测方案。通过少量种子文档,快速自动生成专业领域的 RAG 评测数据,并提供稳健的模型驱动评测指标与方法。
UltraRAG 各方法在国内外 AI 社区中享有一定的影响力和知名度,例如部分模型拥有三十万次下载量,有的曾在领域内顶尖机构受邀进行学术报告,还有的曾位居中文模型下载量榜首。
参考文献
https://arxiv.org/abs/2410.13509
Li, Xinze, Mei, Sen, Liu, Zhenghao, Yan, Yukun, Wang, Shuo, Yu, Shi, Zeng, Zheni, Chen, Hao, Yu, Ge, Liu, Zhiyuan, et al. (2024).RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards. arXiv preprint arXiv:2410.13509.
https://arxiv.org/abs/2410.10594
Yu, Shi, Tang, Chaoyue, Xu, Bokai, Cui, Junbo, Ran, Junhao, Yan, Yukun, Liu, Zhenghao, Wang, Shuo, Han, Xu, Liu, Zhiyuan, et al. (2024).Visrag: Vision-based Retrieval-Augmented Generation on Multi-Modality Documents. arXiv preprint arXiv:2410.10594.
https://arxiv.org/abs/2410.08821
Wang, Ruobing, Zha, Daren, Yu, Shi, Zhao, Qingfei, Chen, Yuxuan, Wang, Yixuan, Wang, Shuo, Yan, Yukun, Liu, Zhenghao, Han, Xu, et al. (2024).Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation. arXiv preprint arXiv:2410.08821.
https://arxiv.org/abs/2411.14790
Zeng, Zheni, Chen, Yuxuan, Yu, Shi, Yan, Yukun, Liu, Zhenghao, Wang, Shuo, Han, Xu, Liu, Zhiyuan, Sun, Maosong. (2024).KBAlign: Efficient Self Adaptation on Specific Knowledge Bases. arXiv preprint arXiv:2411.14790.
https://arxiv.org/abs/2408.01262
Zhu, K., Luo, Y., Xu, D., Wang, R., Yu, S., Wang, S., Yan, Y., Liu, Z., Han, X., Liu, Z., & others. (2024). Rageval: Scenario specific rag evaluation dataset generation framework.arXiv preprint arXiv:2408.01262.
参考信息:
前后的对比,隐私安全,举一个例子;传统方式 VS UltraRAG;
-
本地一键部署!你最佳的知识库管理助手
-
任何数据(举例),法律、个人信息、学科老师,上传数据、调优、即可为你解答
-
快速复现各种方法,为科研赋能
(文:AI前线)