
以后硬核创新会越来越多。现在可能还不容易被理解,是因为整个社会群体需要被事实教育。当这个社会让硬核创新的人功成名就,群体性想法就会改变。我们只是还需要一堆事实和一个过程。
—— DeepSeek 创始人梁文锋
这几天,DeepSeek 全球爆火,但由于这家公司过于低调,未有宣发,使得大众对这家极具潜力的科技企业知之甚少——无论是其创立背景、业务范围,还是产品布局。
在整理完所有材料后,我便撰写了此篇 江湖录 :
目前的 AI 玩家,是怎样的背景,在卷那些事儿,以及在招哪些人
本篇是江湖录的第二篇,也可能是有关 DeepSeek 的最全的历史过往。
本文所有 DeepSeek 相关图片,除非备注,均源自官方发布渠道及其应用程序截图。特别鸣谢「暗涌」发布的两篇对梁文锋先生的深度访谈,其中的真知灼见为本文提供了宝贵的研究素材。
去年此时,幻方量化的朋友找到我,问:“要不要在国内做大模型?”而我,只单纯的喝了半下午的咖啡。果然,人生还是看选择的。
这里所提的幻方量化,便是 DeepSeek 的出资方,或者说母体。

所谓量化,便是不由人力,而用算法来进行决策的投资机构。幻方量化的成立时间不算长,起步于 2015 年。到了 2021 年,时年六岁的幻方量化,其资产管理规模便已突破千亿,被誉为中国 “量化四大天王” 之一。
幻方的创始人梁文锋,也正是日后 DeepSeek 的创立者,是个“非主流”的 80 后金融领导者:他没有海外留学经历,也不是奥林匹克竞赛获奖者,毕业于浙江大学电子工程系人工智能专业,土生土长的技术专家,行事低调,每天“看论文,写代码,参与小组讨论”。
梁文锋的身上没有传统企业老板的习气,更像一位纯粹的 “技术极客”。多位业内人士和 DeepSeek 的研究员,给了梁文锋极高的评价:“兼具强大的infra工程能力和模型研究能力,又能调动资源”、“既可以从高处做精准判断,又可以在细节上强过一线研究员”的人,同时有着“令人恐怖的学习能力”。
早在成立 DeepSeek 之前,幻方便已开始在 AI 行业进行了长远布局。2023 年 5 月,梁文锋在接受暗涌采访时提到: “2020 年 OpenAI 发布 GPT3 后,人工智能发展的方向已经非常清晰,算力将成为关键要素;但即便 2021 年,我们投入建设萤火二号时,大部分人还是无法理解”。
基于这一判断,幻方开始构建起自己的算力基建。“从最早的1张卡,到2015年的100张卡、2019年的1000张卡,再到一万张,这个过程是逐步发生的。几百张卡之前,我们托管在IDC,规模再变大时,托管就没法满足要求了,就开始自建机房。”
之后,《财经十一人》报道,“国内拥有超过 1 万枚 GPU 的企业不超过 5 家,而除几家头部大厂外,还包括一家名为幻方的量化基金公司”。而通常认为,1 万枚英伟达 A100 芯片是做自训大模型的算力门槛。
梁文锋在之前的采访中,还提到了一个很有趣的点:很多人会以为这里边有一个不为人知的商业逻辑,但其实,主要是好奇心驱动。
DeepSeek 初见
在 2023 年 5 月接受暗涌采访时,当被问及 “前不久,幻方发公告决定下场做大模型,一家量化基金为什么要做这样一件事?”
梁文锋的回答掷地有声:“我们做大模型,其实跟量化和金融都没有直接关系。我们独建了一个名为深度求索的新公司来做这件事。幻方的主要班底里,很多人是做人工智能的。当时我们尝试了很多场景,最终切入了足够复杂的金融,而通用人工智能可能是下一个最难的事之一,所以对我们来说,这是一个怎么做的问题,而不是为什么做的问题。“
并非出于商业利益驱动,也非追逐市场风口,单单只是对 AGI 技术本身的探索渴望, 以及对 “最重要、最困难的事” 的执着追求,“深度求索” 这一名称在 2023年5月已被正式确认。2023年7月17日, “杭州深度求索人工智能基础技术研究有限公司” 注册成立。
2023年11月2日,DeepSeek 交来了首篇答卷:DeepSeek Coder 代码大模型开源发布。这个模型包括 1B,7B,33B 多种尺寸,开源内容包含 Base 模型和指令调优模型。

在当时,在开源模型中,Meta 的 CodeLlama 是业内标杆。而 DeepSeek Coder 一经发布,比起 CodeLlama,便展示出多方位领先的架势:在代码生成上,HumanEval 领先 9.3%、MBPP 领先 10.8,DS-1000 领先 5.9%。
要知道,DeepSeek Coder 是 7B 模型,而 CodeLlama 却是 34B。另外,经过指令调优后的 DeepSeek Coder 模型更是全面超越了 GPT3.5-Turbo。
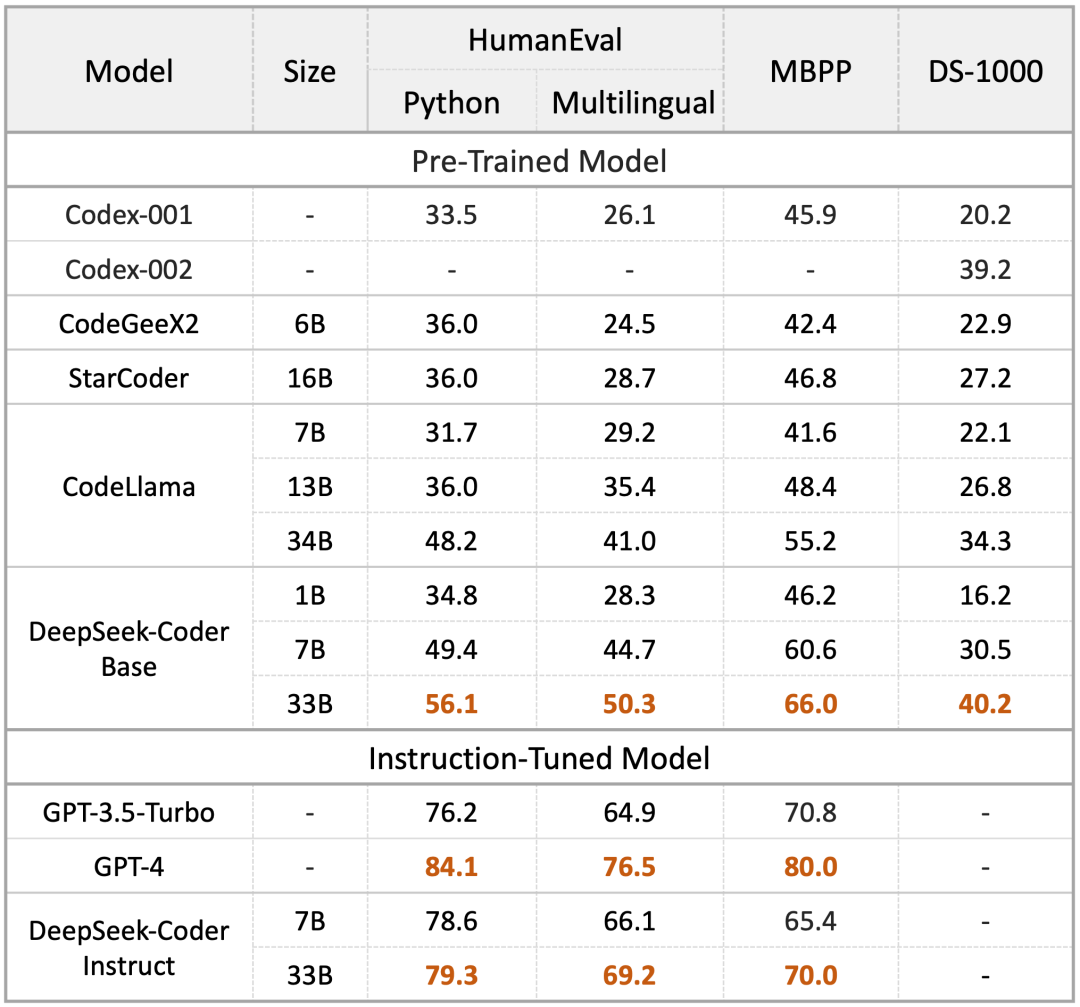
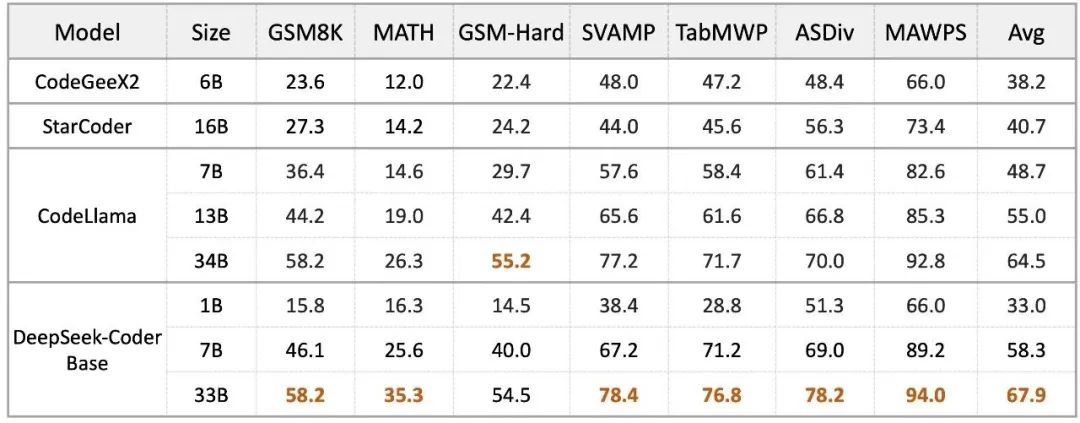
不仅在代码生成上可圈可点,DeepSeek Coder 也在数学和推理上秀了一波肌肉。
3日后,也就是 2023 年 11 月 5 日,DeepSeek 通过其微信公众号,连续发布了大量招聘内容,岗位包括:AGI 大模型实习生、数据百晓生、数据架构人才、高级数据采集工程师、深度学习研发工程师等招聘信息,开始积极扩充团队规模。
正如梁文锋所言,DeepSeek 在人才招聘上 “必卡的条件” 是 “热爱,扎实的基础能力”, 并且强调 “创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。创新往往都是自己产生的,不是刻意安排的,更不是教出来的。”
模型频发,践行开源
在 DeepSeek Coder 一鸣惊人之后,DeepSeek 将目光投向主战场:通用大模型。
2023年11月29日,DeepSeek 发布了其首款通用大语言模型 DeepSeek LLM 67B。这款模型对标的是 Meta 的同级别模型 LLaMA2 70B,并在近20个中英文的公开评测榜单上表现更佳。尤其突出的是推理、数学、编程等能力(如:HumanEval、MATH、CEval、CMMLU)。
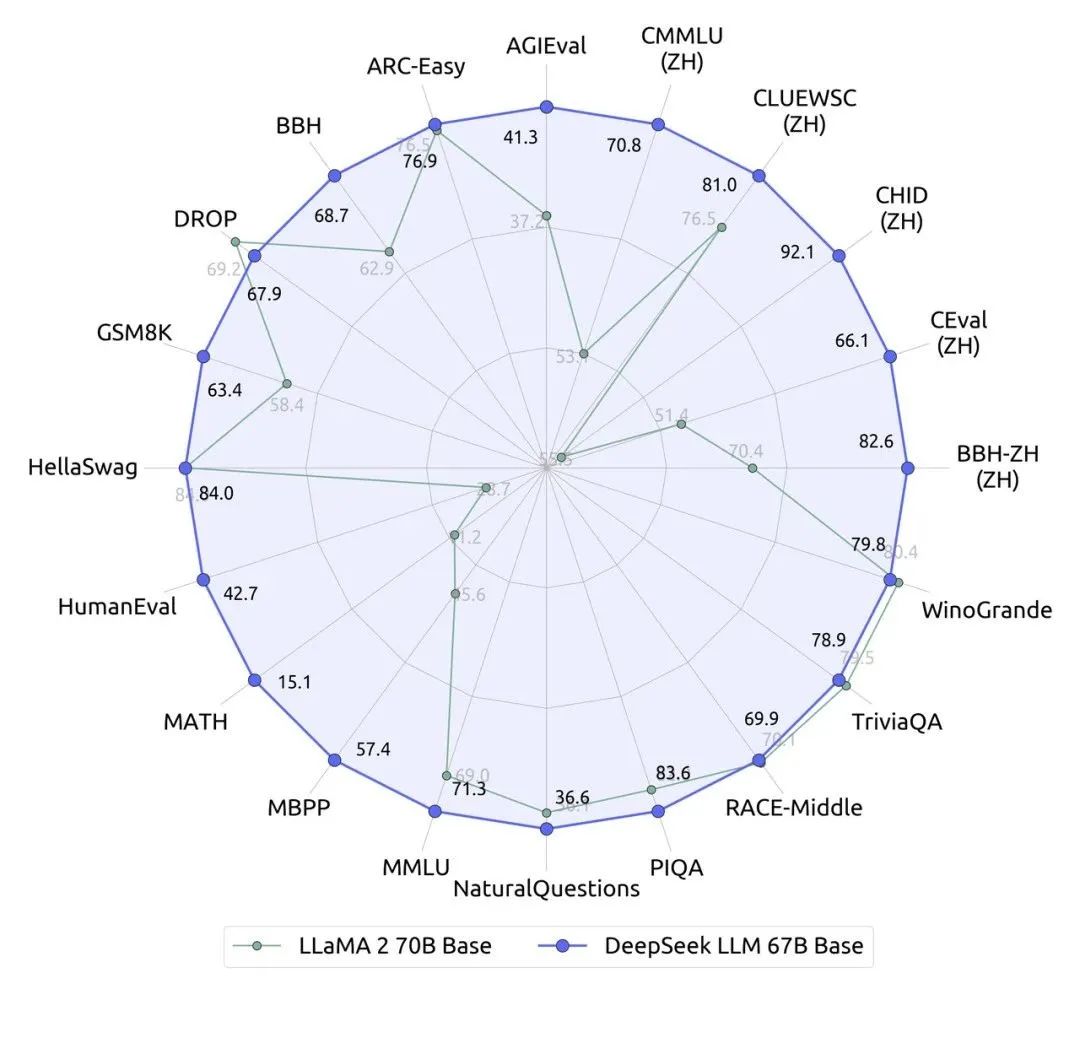
DeepSeek LLM 67B 同样选择了开源路线,并支持商用。为了进一步彰显其开源的诚意和决心,DeepSeek 史无前例地同步开源了 7B 和 67B 两种不同规模的模型,甚至将模型训练过程中产生的 9 个 checkpoints 也一并公开,供研究人员下载使用。这种近乎 “倾囊相授” 的操作,在整个开源社区都极为罕见。
为了更全面、更客观地评估 DeepSeek LLM 67B 的真实能力,DeepSeek 的研究团队还精心设计了一系列 “新题” 进行 “压力测试”,这些题目涵盖了匈牙利高中数学考试题、Google 指令跟随评测集、LeetCode 周赛题等高难度、高区分度的测试。测试结果令人振奋,DeepSeek LLM 67B 在样本外泛化能力方面表现出了惊人的潜力,其综合性能甚至直逼当时最先进的 GPT-4 模型。
2023年12月18日,DeepSeek 开源了文生 3D 模型 DreamCraft3D:可从一句话生成高质量的三维模型,实现了 AIGC 从 2D 平面到 3D 立体空间的跨越。比如,用户输入:“奔跑在树林中,搞笑的猪头和孙悟空身体的混合形像”,DreamCraft3D 便可以输出高质量的内容:

从原理上来说,这个模型先完成了文生图,然后再根据 2D 概念图,脑补出整体的几何结构:

在之后的主观评比中,相较于之前的生成方法,超过 90% 的用户表示 DreamCraft3D 的生成质量更具优势。

生成质量用户主观评价
2024年1月7日,DeepSeek 发布了 DeepSeek LLM 67B 技术报告。这份报告有 40+ 页,内容包含了 DeepSeek LLM 67B 的多项细节,包括自建 Scaling Laws、完整的模型对齐实践细节、以及全方位的 AGI 能力评估体系等等。
报告地址:https://arxiv.org/abs/2401.02954

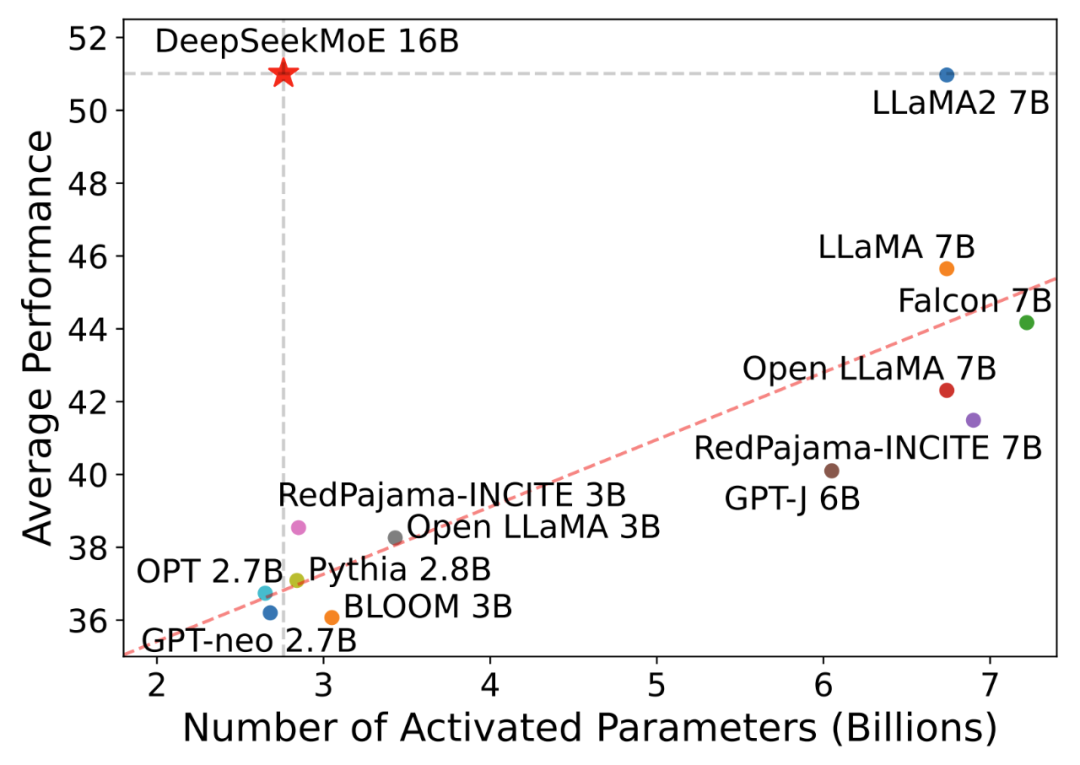
2024年1月11日,DeepSeek 开源了国内首个 MoE(混合专家架构)大模型 DeepSeekMoE:全新架构,支持中英,免费商用。MoE 架构在当时被普遍认为是 OpenAI GPT-4 性能突破的关键所在,而 DeepSeek 自研的 MoE 架构,在 2B、16B、145B 等多个尺度上均领先,同时其计算成本也非常值得称道。
2024年1月25日,DeepSeek 发布了 DeepSeek Coder 技术报告。这份报告对其训练数据、训练方法、以及模型效果进行了全面的技术剖析。在这份报告中,我们可以发现其首次构建了仓库级代码数据,并用拓扑排序解析文件之间依赖,显著增强了长距离跨文件的理解能力。而在训练方法上,增加了Fill-In-Middle方法,大幅提升了代码补全的能力。
报告地址:https://arxiv.org/abs/2401.14196

2024年1月30日,DeepSeek 开放平台正式上线,DeepSeek 大模型 API 服务启动测试。注册即送 1000 万 token,接口兼容 OpenAI API 接口,有 Chat/Coder 双模型可用。此时,DeepSeek 开始在技术研发之外,开始探寻技术服务商的道路。
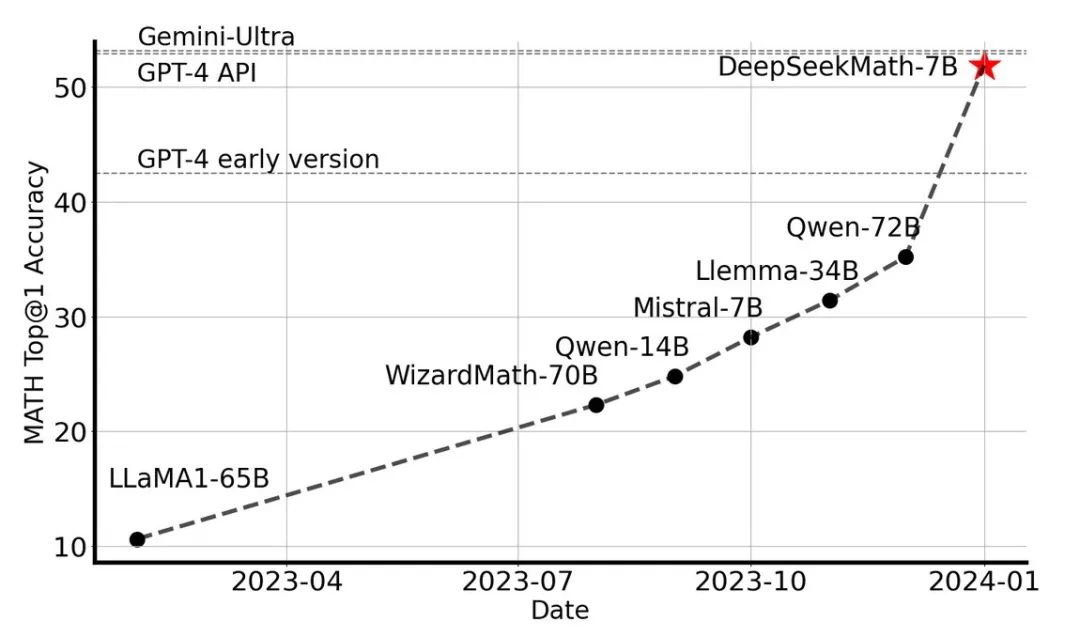
2024年2月5日,DeepSeek 发布了又一款垂直领域模型——数学推理模型 DeepSeekMath。这款仅有 7B 参数的模型,却在数学推理能力上直逼 GPT-4,在权威的 MATH 基准榜单上,力压群雄,超越了一众参数规模在 30B-70B 之间的开源模型。DeepSeekMath 的问世,充分展现了 DeepSeek 在垂直领域模型研发上的技术实力和前瞻布局。
2024年2月28日,为进一步扫除开发者使用 DeepSeek 开源模型的顾虑,DeepSeek 发布了开源政策 FAQ,对模型开源许可、商业使用限制等常见问题进行了详细解答,以更透明、更开放的姿态拥抱开源:

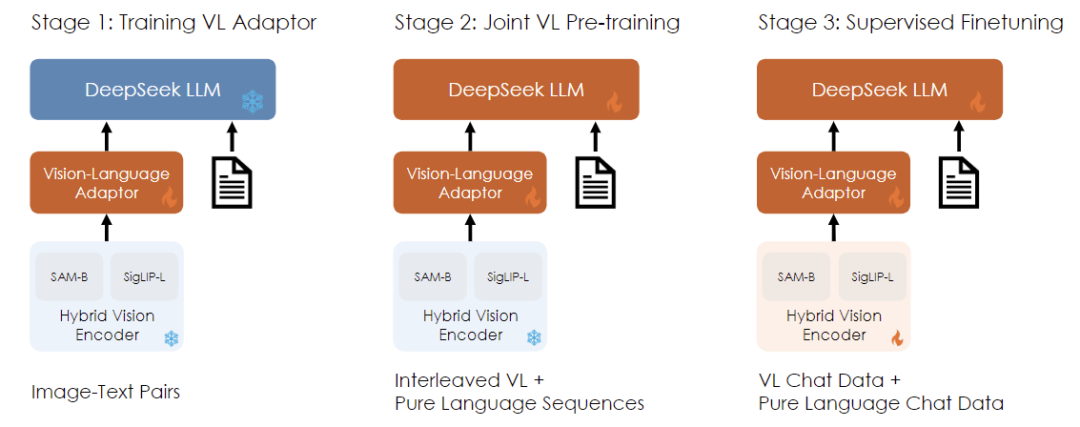
2024年3月11日,DeepSeek 开源发布了多模态大模型 DeepSeek-VL。这是 DeepSeek 在多模态 AI 技术上的初步尝试,尺寸为 7B 与1.3B,模型和技术论文同步开源。
2024年3月20日,幻方 AI & DeepSeek 再次受邀参加 NVIDIA GTC 2024 大会,创始人梁文锋发表了题为《和而不同:大语言模型价值观对齐解耦化》的技术主题演讲。探讨了如”单一价值观的大模型与多元社会文化之间的冲突“,“大模型价值观对齐解耦化”,“解耦化价值观对齐的多维度挑战” 等问题。展现了 DeepSeek 在技术研发之外,对 AI 发展的人文关怀和社会责任的思考。
2024年3月,DeepSeek API 正式推出付费服务,彻底引爆了中国大模型市场的价格战的序幕:每百万输入 Tokens 1 元,每百万输出 Tokens 2 元。

2024年,DeepSeek 顺利通过中国大模型备案,为其 API 服务的全面开放扫清了政策障碍。
2024年5月,DeepSeek-V2 通用 MoE 大模型的开源发布,价格战正式打响。 DeepSeek-V2 使用了 MLA(多头潜在注意力机制),将模型的显存占用率降低至传统 MHA 的 5%-13%,同时,也独辟蹊径地研发了 DeepSeek MoE Sparse 稀疏结构,将模型的计算量大大压缩。凭借于此,而这个模型保持着以「1元/百万输入,2元/百万输出」的 API 价格。
DeepSeek 的影响力非常大。对此,SemiAnalysis 首席分析师认为,DeepSeek V2论文“可能是今年最好的一篇”。同样的,OpenAI 前员工 Andrew Carr 则认为论文“充满惊人智慧”,并将其训练设置应用于自己的模型。
需知:这是一个对标 GPT-4-Turbo 的模型,而 API 价格只有后者的 1/70

2024年6月17日,DeepSeek 再度发力,开源发布了 DeepSeek Coder V2 代码大模型,并宣称其代码能力超越了当时最先进的闭源模型 GPT-4-Turbo。DeepSeek Coder V2 延续了 DeepSeek 一贯的开源策略,模型、代码、论文全部开源,并提供了 236B 和 16B 两种版本。DeepSeek Coder V2 的 API 服务也同步上线,价格依旧是「1元/百万输入,2元/百万输出」。

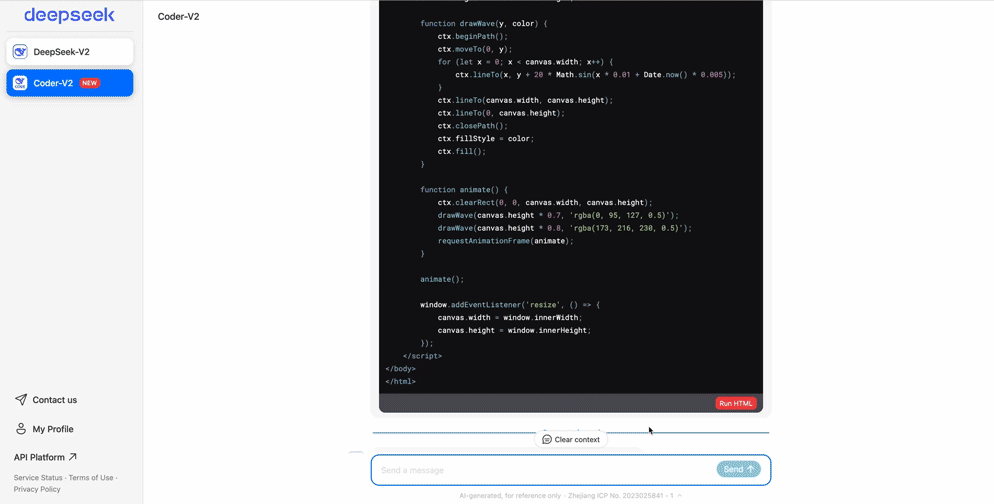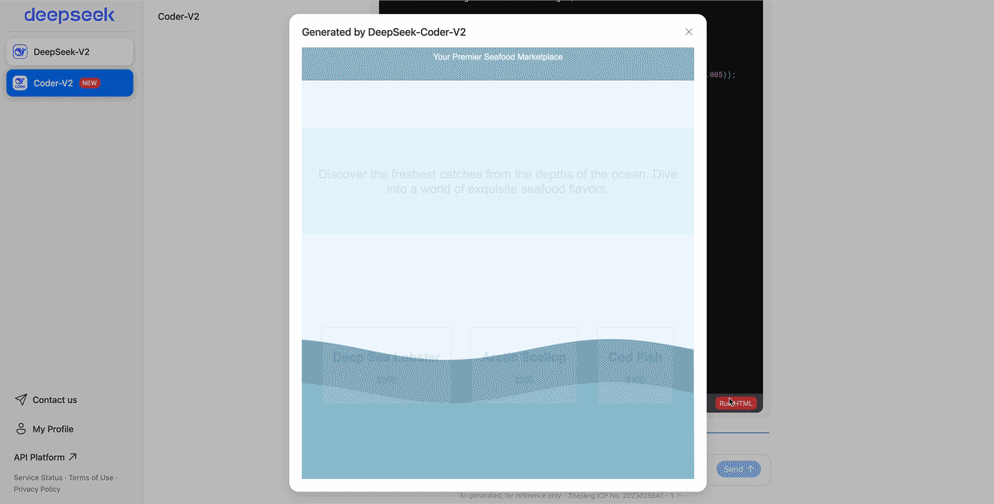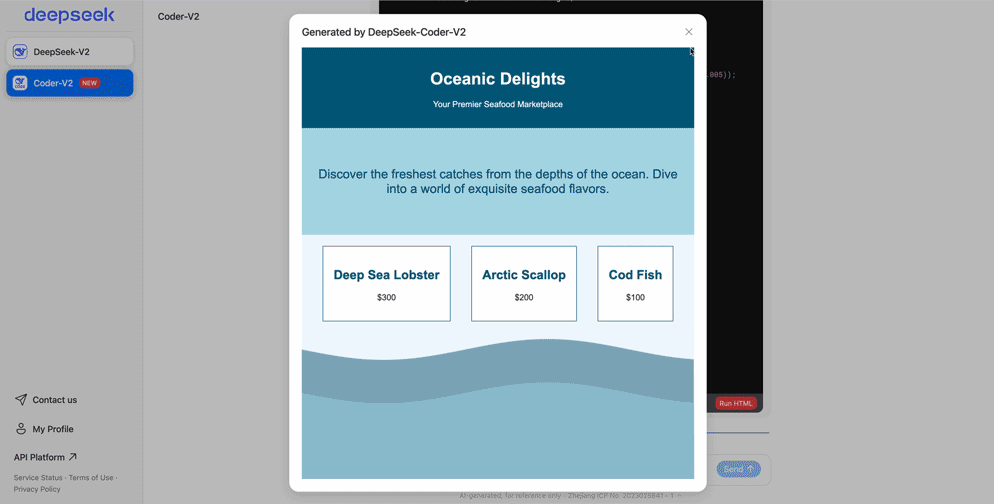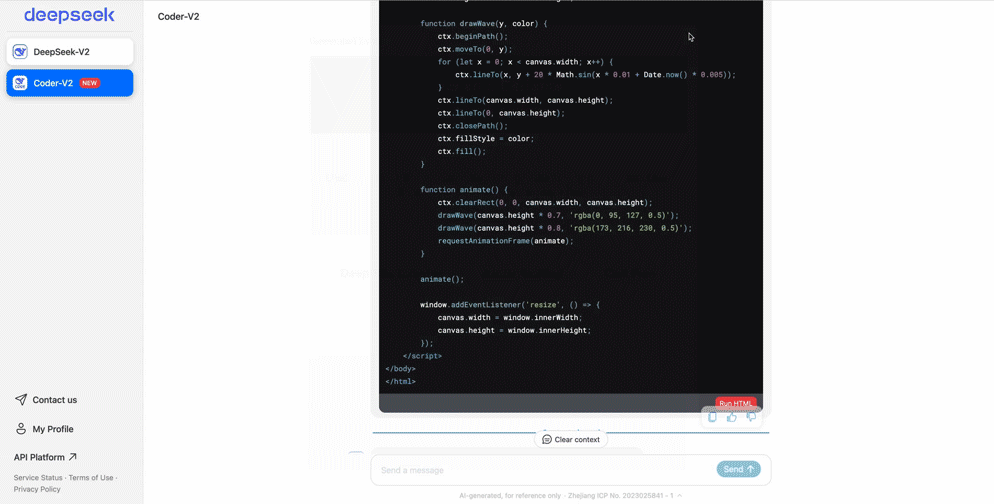
2024年6月21日,DeepSeek Coder 支持代码在线执行。在同一天,先是 Claude3.5 Sonnet 发布,并上新 Artifacts 功能,自动生成代码并直接在浏览器上运行。同一天的,DeepSeek 官网的代码助手也上线了同样的功能:生成代码,一键运行。
回顾一下这段时间的大事记:

持续突破,全球瞩目
2024 年 5 月,DeepSeek 通过 MoE 开源模型 DeepSeek V2,一战成名:对标 GPT-4-Turbo 的性能,但价格只要 1块钱/百万输入,这是 GPT-4-Turbo 的 1/70。那时,DeepSeek 成了业内知名的“价格屠夫”,进而,智谱、字节、阿里…等主流玩家迅速跟进,纷纷降价。也是那时,适逢又一轮 GPT 封号潮,大批 AI 应用,开始初尝国内模型。
在 2024 年七月,DeepSeek 创始人梁文锋,再次接受暗涌的报道,对于这次价格战进行了正面回应:“非常意外。没想到价格让大家这么敏感。我们只是按照自己的步调来做事,然后核算成本定价。我们的原则是不贴钱,也不赚取暴利。这个价格也是在成本之上稍微有点利润。”
可见,与众多牌桌选手掏钱做补贴不同的是,DeepSeek 在这个定价下,是有利润的。
有人会说:降价很像在抢用户,互联网时代的价格战通常如此
对此,梁文锋也回应到:“抢用户并不是我们的主要目的。我们降价一方面是因为我们在探索下一代模型的结构中,成本先降下来了,另一方面也觉得无论 API,还是 AI,都应该是普惠的、人人可以用得起的东西。”
那么,故事也就由着梁文锋的理想主义,继续展开。
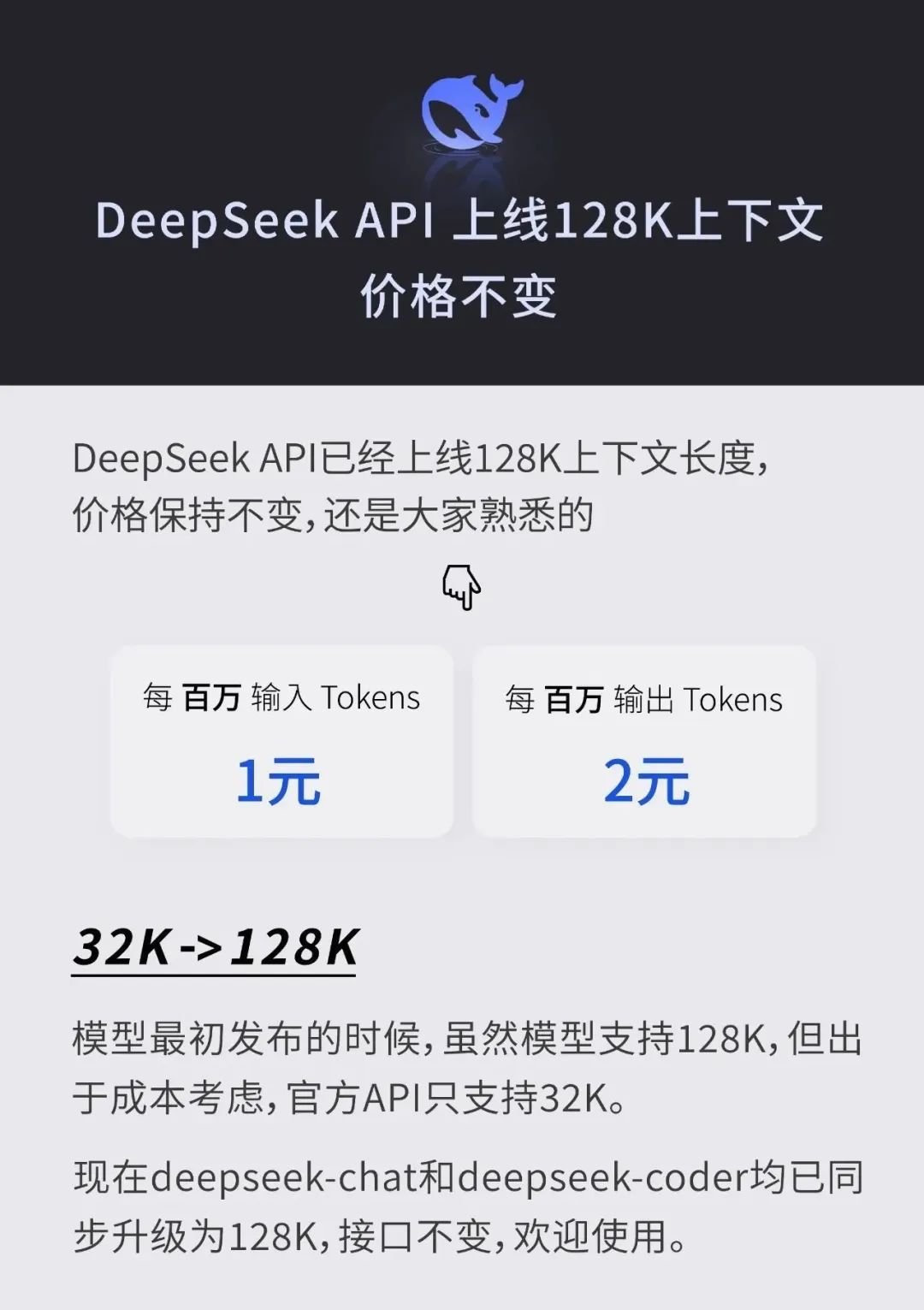
2024年7月4日,DeepSeek API 上线128K上下文 价格不变。模型的推理成本,与上下文长度密切相关。所以很多模型,对于这个长度,限制严苛:初版 GPT-3.5 只有 4k 的上下文。
而此时,DeepSeek 在保持价格不变的前提下(每百万输入 Tokens 1 元,每百万输出 Tokens 2 元),将上下文长度,从之前的 32k 提升到了 128k。
2024年7月10日,全球首届 AI 奥数竞赛(AIMO)结果揭晓,DeepSeekMath 模型成为了 Top 团队的共同选择,获奖的 Top4 团队不约而同地选择了 DeepSeekMath-7B 作为其参赛模型的基础,并在竞赛中取得了令人瞩目的成绩。
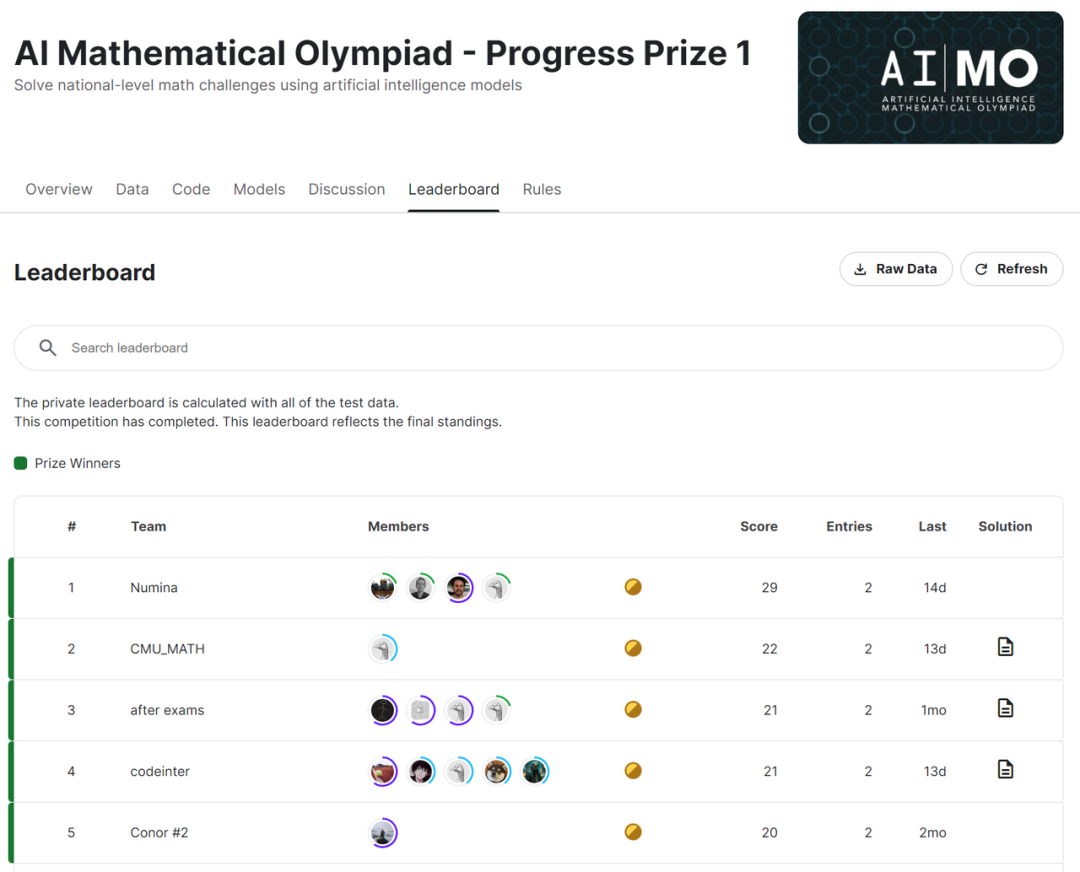
2024年7月18日,在 “全球大模型竞技场”(Chatbot Arena)榜单上,DeepSeek-V2 荣登开源模型榜首,超越了 Llama3-70B、Qwen2-72B、Nemotron-4-340B、Gemma2-27B 等一众明星模型,成为开源大模型的新标杆。

2024年7月,DeepSeek 持续广纳贤才,面向全球招募 AI 算法、AI Infra、AI Tutor、AI 产品等多个方向的顶尖人才,为未来的技术创新和产品发展储备力量。
2024年7月26日,DeepSeek API 迎来重要升级,全面支持续写、FIM(Fill-in-the-Middle)补全、Function Calling、JSON Output 等一系列高级功能。其中的 FIM 功能非常有趣,即:用户给出开头和结尾,大模型来填补中间的,非常适合编程的过程中,填充准确函数代码。以撰写斐波那契数列为例:

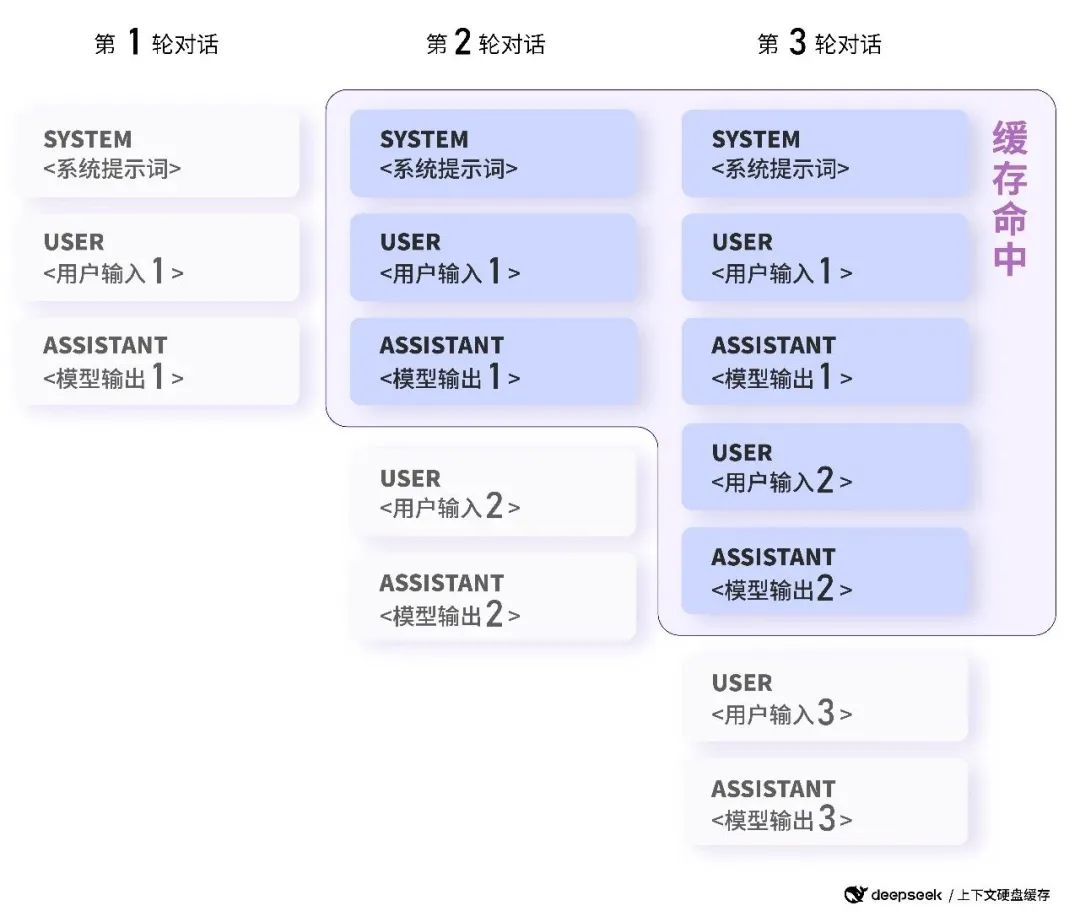
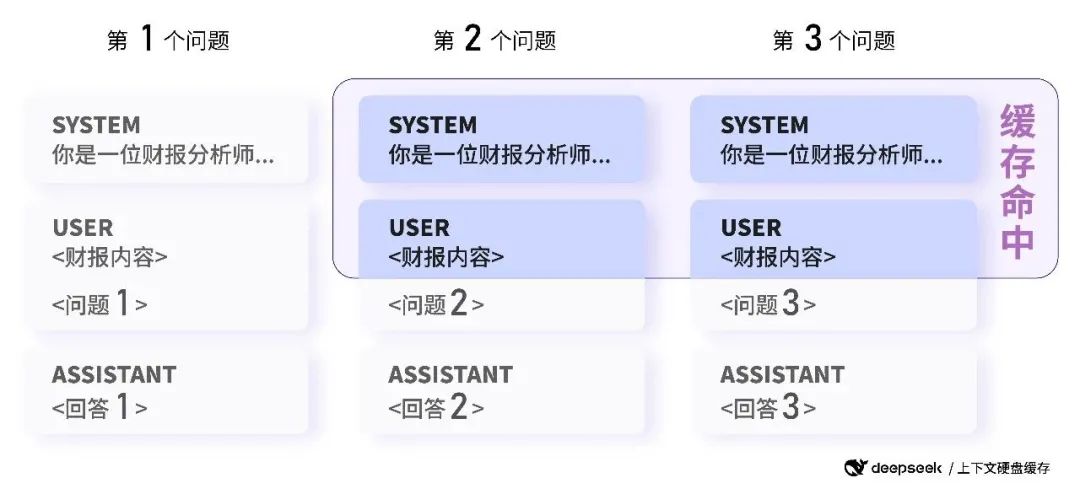
2024年8月2日,DeepSeek 创新性地引入了硬盘缓存技术,使得 API 价格斩向脚踝。之前 API 价格,每百万 token 只需 1 元。而现在,一旦命中缓存,API 费用直接降至 0.1 元。
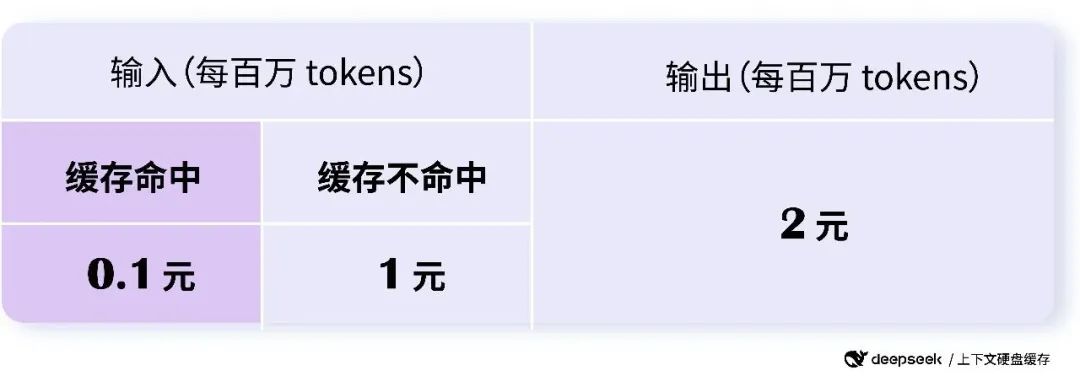
这个功能,在连续对话,以及批量处理任务时,非常实用。
2024年8月16日,DeepSeek 开源发布了其数学定理证明模型 DeepSeek-Prover-V1.5,这款模型在高中和大学数学定理证明测试中,均超越了多款知名的开源模型。
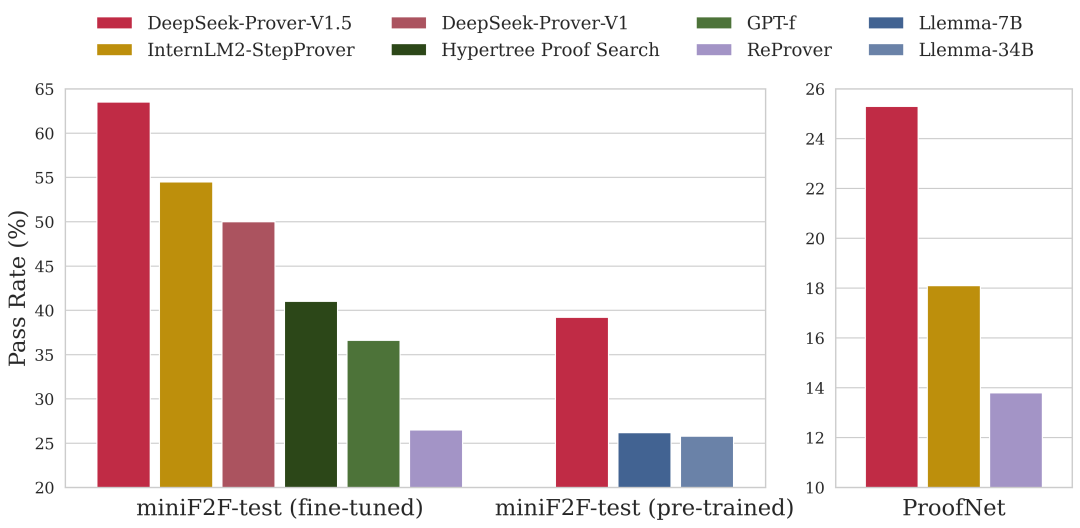
2024年9月6日,DeepSeek 开源发布了 DeepSeek-V2.5 融合模型。之前,DeepSeek 主要提供的是款模型:Chat 模型聚焦通用对话能力,Code 模型聚焦代码处理能力。而这次,两款模型合二为一,升级成了 DeepSeek-V2.5,更好的对齐了人类偏好,并还在写作任务、指令跟随等方面实现了显著提升。
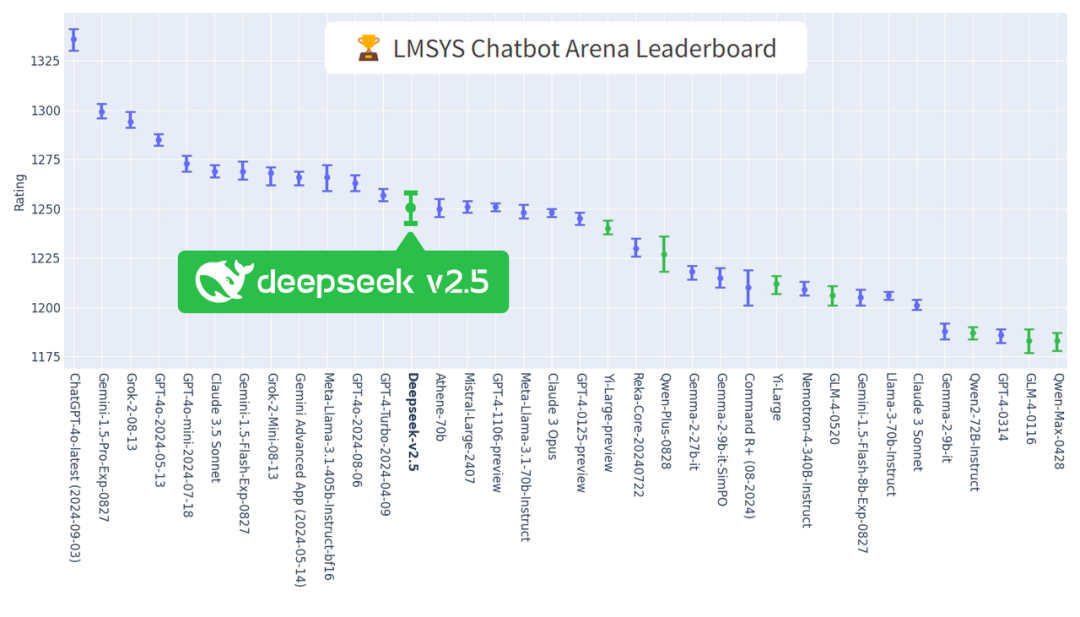
2024年9月18日,在 LMSYS 最新榜单上,DeepSeek-V2.5 再次上榜,并领跑国内模型,在多个单项能力上,也都刷新了国内模型的最好成绩。
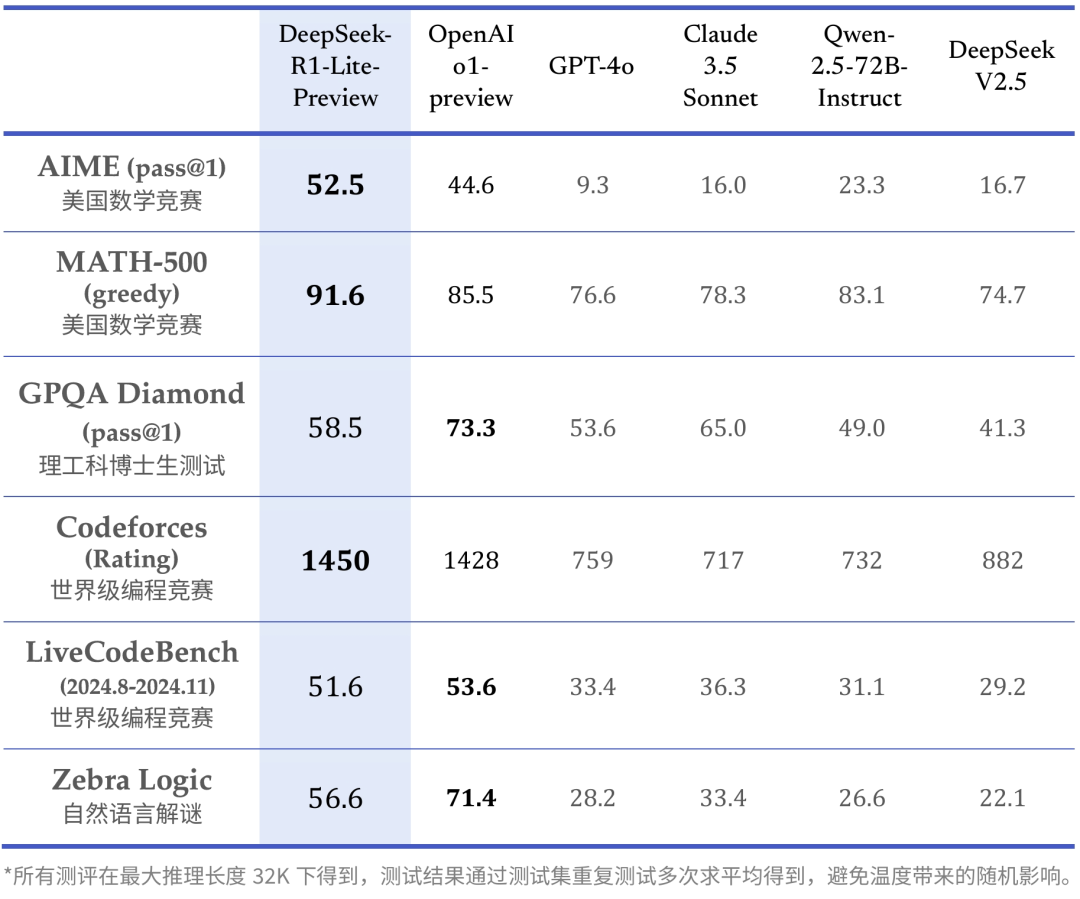
2024年11月20日,DeepSeek 在官网上线了 DeepSeek-R1-Lite,这是一款推理模型,媲美 o1-preview,也为之后 V3 的后训练,提供了足量的合成数据。
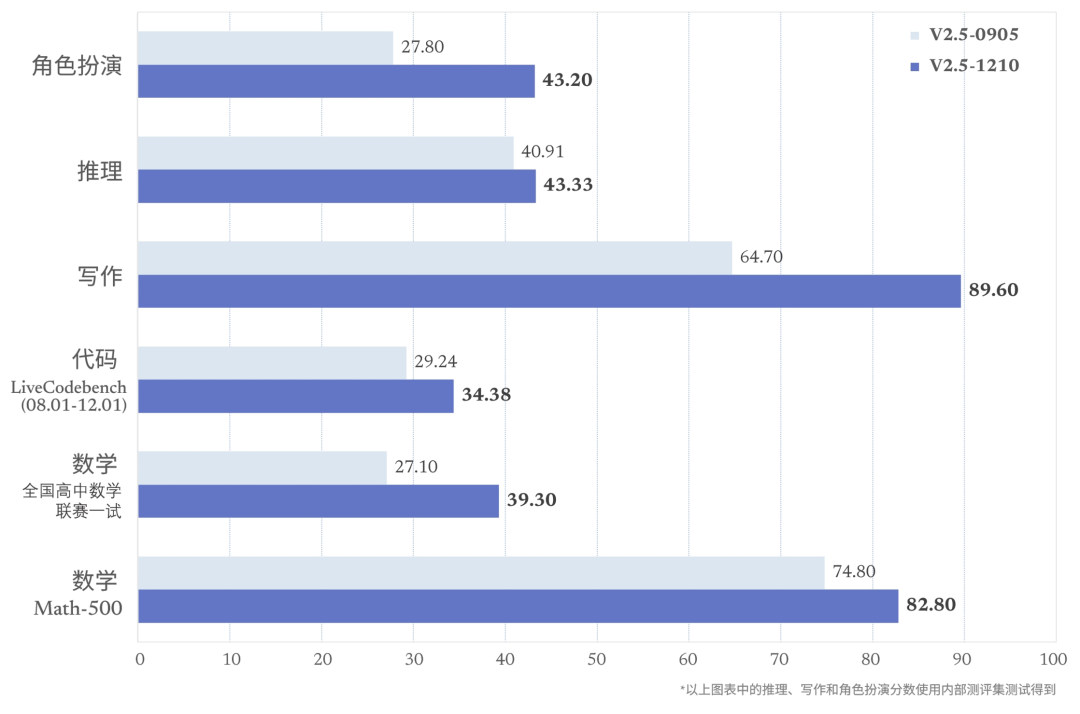
2024年12月10日,DeepSeek V2 系列迎来收官之作——DeepSeek-V2.5-1210 最终微调版发布。该版本通过后训练,全面提升了包括数学、代码、写作、角色扮演等在内的多方能力。
DeepSeek 的网页 APP 也随着此版本的到来,开放了联网搜索功能。
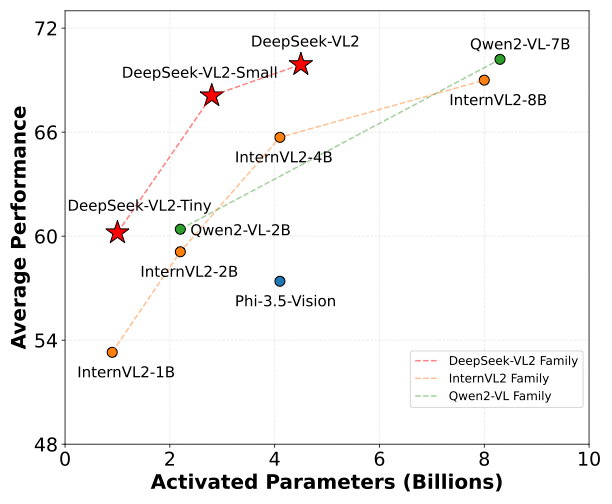
2024年12月13日,DeepSeek 在多模态领域再次发力,开源发布了多模态大模型 DeepSeek-VL2。DeepSeek-VL2 采用了 MoE 架构,视觉能力得到了显著提升,有 3B、16B 和 27B 三种尺寸,在各项指标上极具优势。
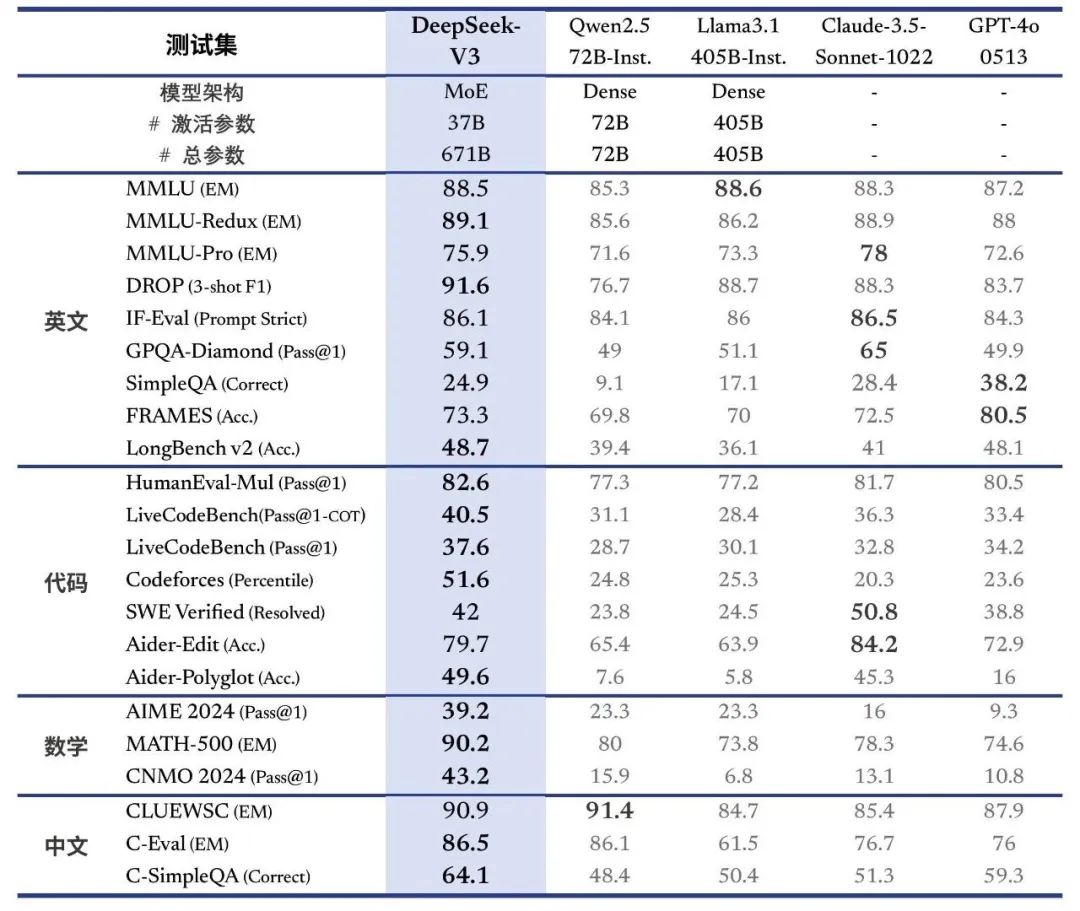
2024年12月26日,DeepSeek-V3 开源发布:训练成本估算只有 550 万美金。DeepSeek-V3 在性能上全面对标海外领军闭源模型,生成速度也大幅提升。
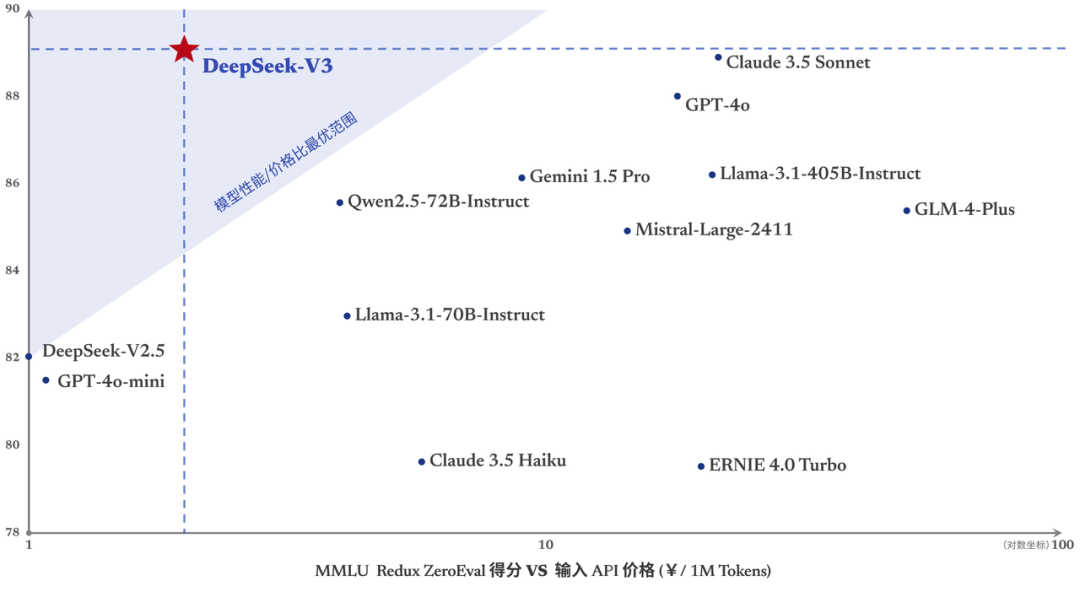
API 服务定价进行了调整,但同时为新模型设置了长达 45 天的优惠体验期。

这里有一份来自「赛博禅心」的详实解读:DeepSeek-V3 是怎么训练的|深度拆解
2025年1月15日,DeepSeek 官方 App 正式发布,并在 iOS/Android 各大应用市场全面上线。

2025年1月20日,临近春节,DeepSeek-R1 推理模型正式发布并开源。DeepSeek-R1 在性能上全面对齐 OpenAI o1 正式版,并开放了思维链输出功能。与此同时,DeepSeek 还宣布将模型开源 License 统一变更为 MIT 许可证,并明确用户协议允许 “模型蒸馏”,进一步拥抱开源,促进技术共享。
当日,「赛博禅心」便提供了一份详实解读:DeepSeek-R1 是怎么训练的|深度拆解
后面,这个模型大火,开创了时代:
DeepSeek 完全指南:这到底是怎样的存在?
于是,截止到了 2025年1月27日,DeepSeek App 成功超越 ChatGPT,登顶美国 iOS 应用商店免费应用下载榜首,成为了现象级的 AI 应用。
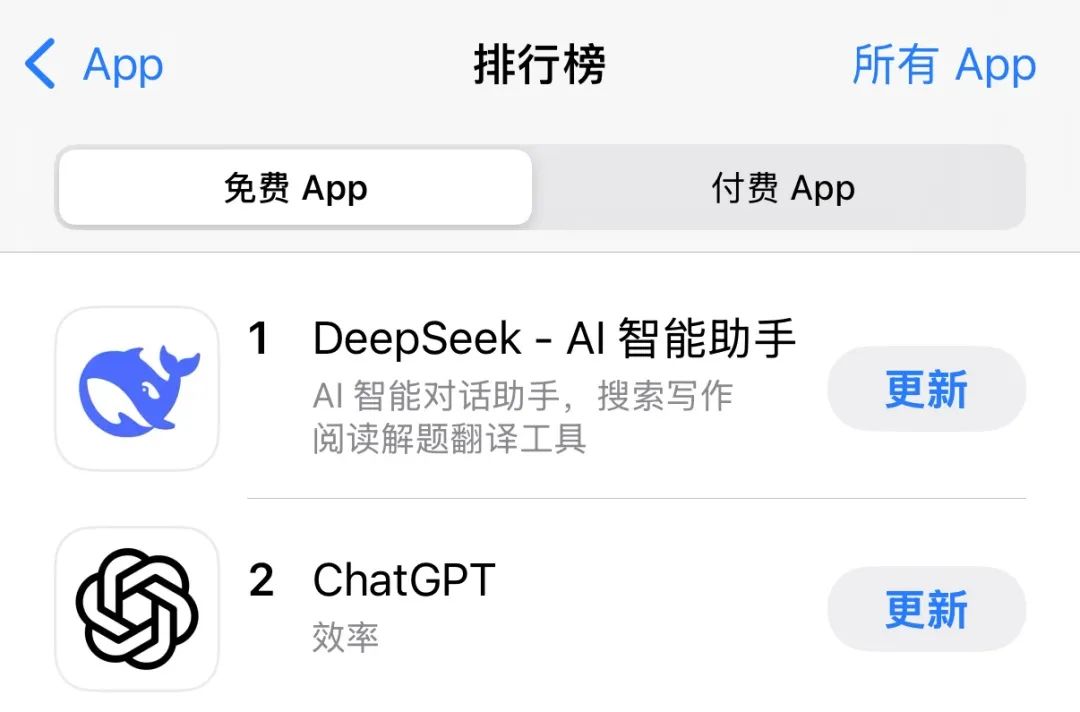
2025年1月27日,除夕凌晨1点,DeepSeek Janus-Pro 开源发布。这是一个多模态模型,名称来源于古罗马神话中的双面神“雅努斯”(Janus):它同时面向过去与未来。这也代表了模型的两种能力——既要进行视觉理解,又要进行图像生成,并在多个排行中霸榜。
DeepSeek 的爆火,旋即引发了全球科技震动,甚至直接导致了 NVIDIA 股价暴跌 18%,全球科技股市市值蒸发了约 1 万亿美元。 华尔街和科技媒体纷纷惊呼,DeepSeek 的崛起,正在颠覆全球 AI 产业格局,对美国科技巨头构成了前所未有的挑战。
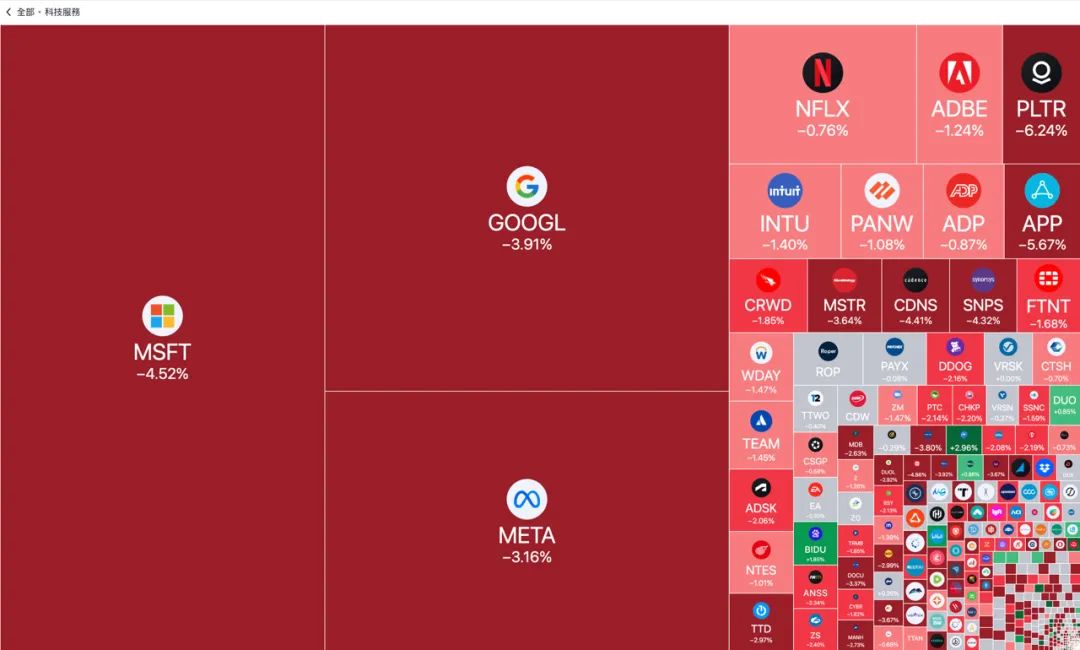
除夕之夜,美股上演了一出中国红
DeepSeek 的成功,也引发了国际社会对中国 AI 技术创新能力的高度关注和热烈讨论。美国总统特朗普罕见地公开赞扬 DeepSeek 的崛起是 “积极的”,并认为这是一个给美国敲响的 “警钟”。微软 CEO Satya Nadella 和 OpenAI CEO Sam Altman 也对 DeepSeek 表示赞赏,称其技术 “非常令人印象深刻”。
当然,我们也要知道,他们的赞扬一方面是对 DeepSeek 实力的认可,另一方面则是各有心思磨刀霍霍,比如 Anthropic 一遍认可着 DeepSeek 的成绩,一边号召美国政府加强对华芯片管制。
Anthropic CEO 发万字檄文:DeepSeek 崛起,白宫应加码管制
总结与展望
回顾 DeepSeek 的这两年,真所谓一部 “中国式奇迹”:从名不见经传的创业公司,到如今在全球 AI 舞台上大放异彩的 “东方神秘力量”,DeepSeek 用实力和创新,书写了一个又一个 “不可能”。
这场技术远征的深层意义,早已超越商业竞争的范畴。DeepSeek用事实宣告:在人工智能这个关乎未来的战略领域,中国企业完全有能力攀登核心技术高地。
特朗普口中的”警钟”,Anthropic暗藏的忌惮,恰恰印证了中国AI力量的不可忽视:不仅能乘风破浪,更在重塑潮水的方向
产品发布大事记
-
2023年11月2日: DeepSeek Coder 代码大模型
-
2023年11月29日: DeepSeek LLM 67B 通用模型
-
2023年12月18日: DreamCraft3D 文生 3D 模型
-
2024年1月11日: DeepSeekMoE MoE 大模型
-
2024年2月5日: DeepSeekMath 数学推理模型
-
2024年3月11日: DeepSeek-VL 多模态大模型
-
2024年5月: DeepSeek-V2 MoE 通用大模型
-
2024年6月17日: DeepSeek Coder V2 代码大模型
-
2024年9月6日: DeepSeek-V2.5 融合通用与代码能力模型
-
2024年12月13日: DeepSeek-VL2 多模态 MoE 大模型
-
2024年12月26日: DeepSeek-V3 全新系列通用大模型
-
2025年1月20日: DeepSeek-R1 推理模型
-
2025年1月20日: DeepSeek 官方 App (iOS & Android)
-
2025年1月27日: DeepSeek Janus-Pro 多模态模型
职业机会
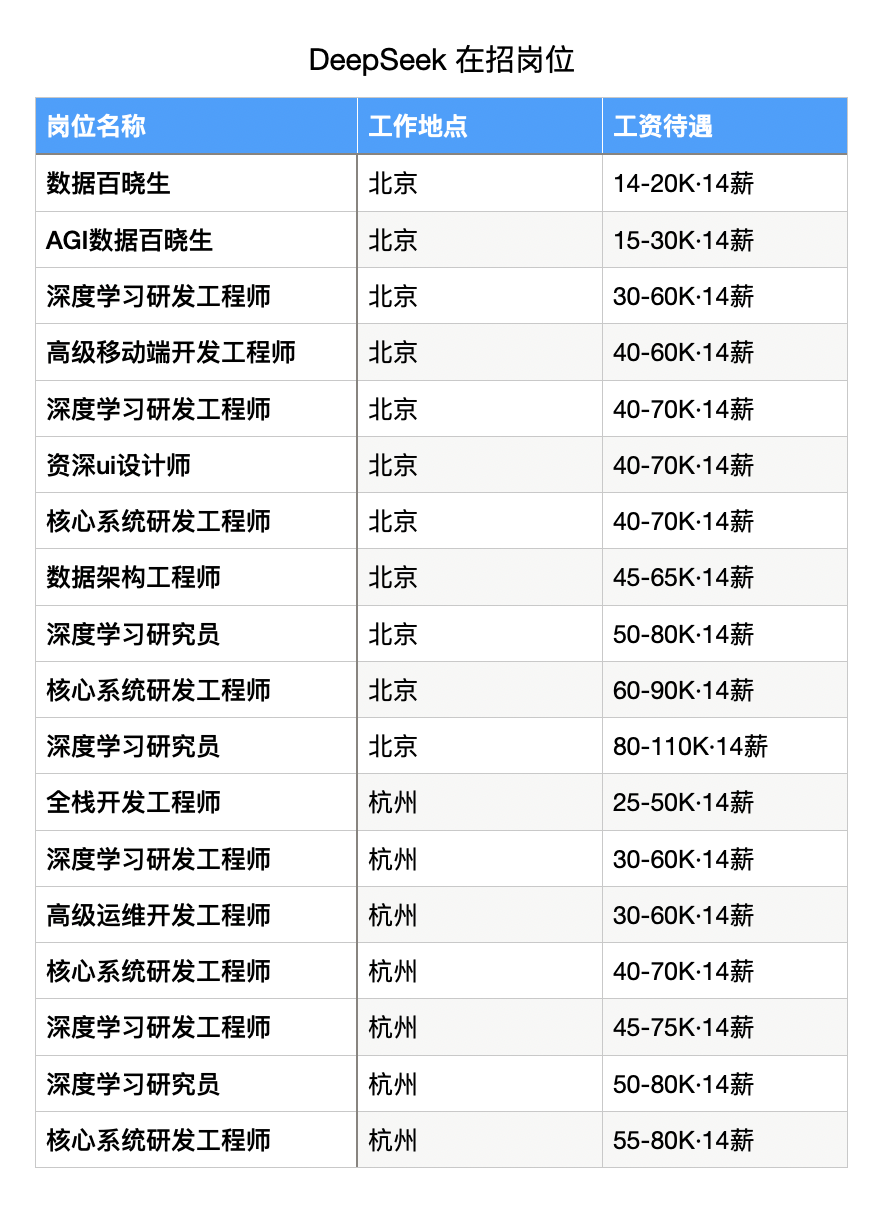
截止到 2025年2月2日,DeepSeek 有以下岗位在招,看看是否会与你有缘。
简历投递:talent@deepseek.com
你可以说是看到赛博禅心的招聘信息而来的,毕竟咱公众号的读者本就都很硬核。
但这并没什么用,DeepSeek 挑人,还是更看价值观和技术。
其他
本文是江湖录系列的第二篇,上一篇为:《六虎中的「多模态狂魔」:阶跃星辰|江湖录》
当然还会有第三、四、五、六篇。
如果您喜欢本内容,欢迎关注赛博禅心,追更本系列。
也可以点击下方的❤️,一键三连,让更多的朋友看到。
(文:赛博禅心)