
智东西2月6日报道,今天凌晨谷歌发布了性能更强的Gemini 2.0 Pro实验版,以及主打低价的Gemini 2.0 Flash-Lite预览版,并且正式开放轻量级的Gemini 2.0 Flash最新版本。
其中,Gemini 2.0 Flash-Lite是Gemini 2.0系列的新变体,每百万tokens 0.3美元,是谷歌目前最便宜的模型。而Gemini 2.0 Pro实验版具备原生多模态能力,支持文本和音视频间的相互转换。Gemini 2.0 Flash的实验版于去年12月首发,最新版本为完整版。
此外,Gemini 2.0 Flash Thinking实验版现免费开放使用,还可以访问、提炼并总结YouTube视频内容。
谷歌AI Studio产品负责人Logan Kilpatrick在X发帖称,这几款“谷歌史上最强大的模型”现可供所有开发人员使用。
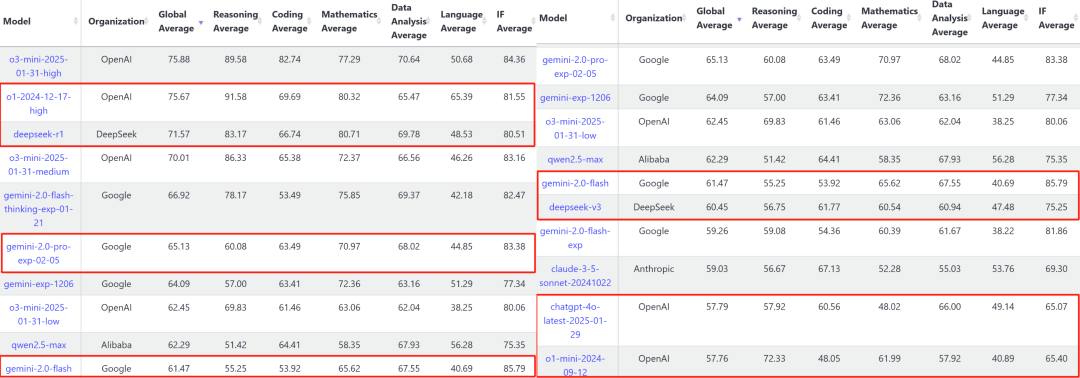
截至发稿,在Chatbot Arena大模型排行榜上,Gemini 2.0 Flash Thinking实验版和Gemini 2.0 Pro实验版已冲上榜首,综合得分反超ChatGPT-4o和DeepSeek-R1,势头强劲。
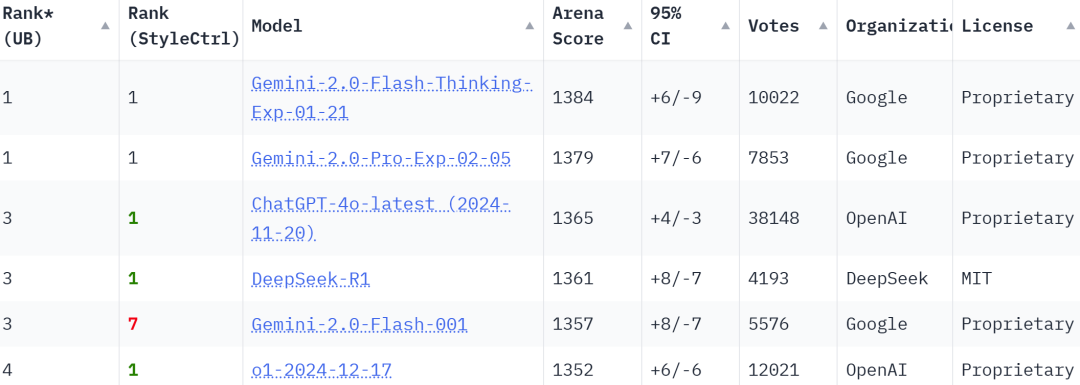
▲Chatbot Arena大模型排行榜Language总榜,综合考虑了大模型的数学、编码、多语种处理等方面的能力(图源:Chatbot Arena官网)
现在,Gemini 2.0 Flash新版、Gemini 2.0 Pro实验版和Gemini 2.0 Flash-Lite预览版,均可以通过谷歌AI Studio和Vertex AI调用其API。这些Gemini 2.0模型的变体各自设有不同的价格和性能优势。
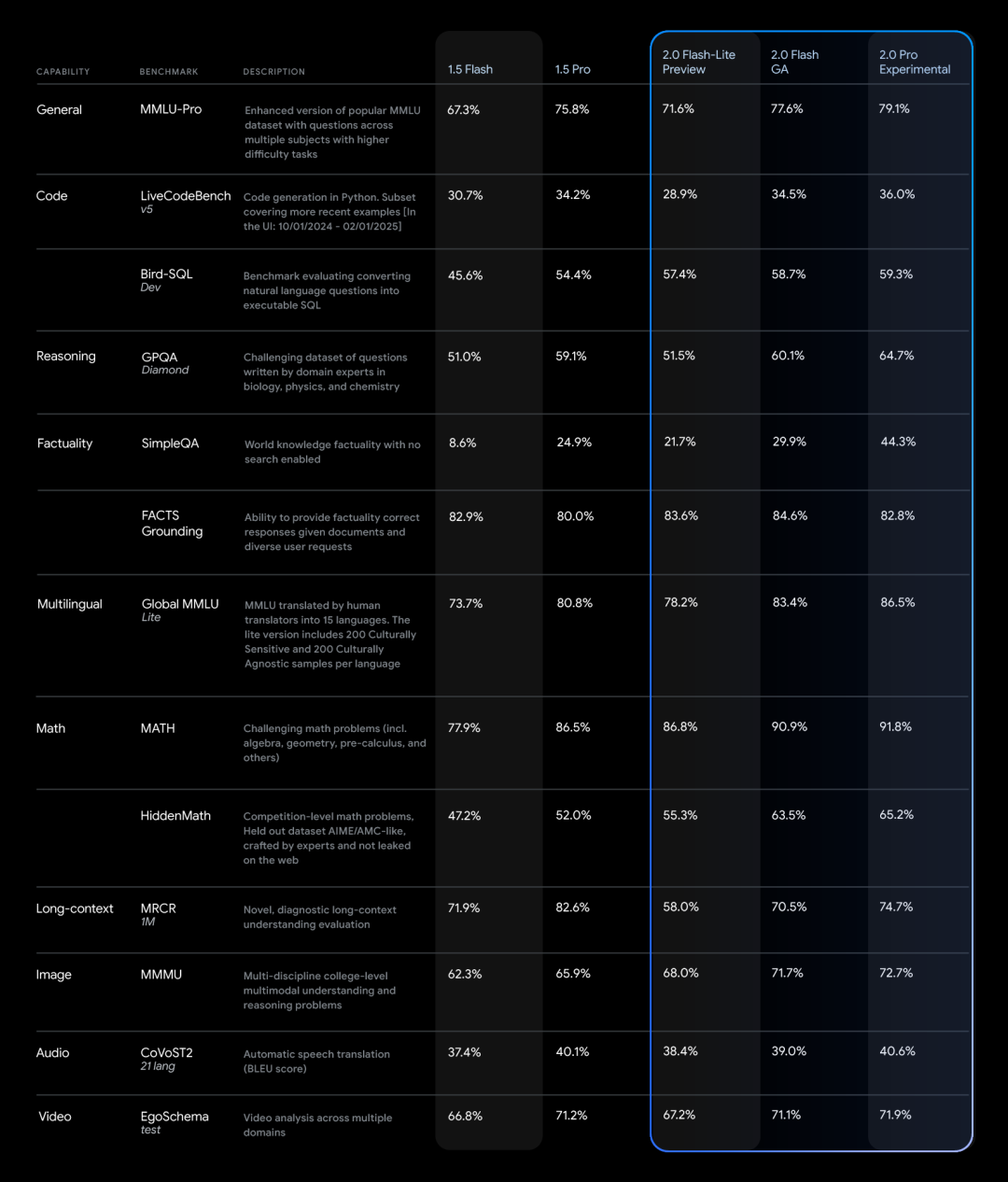
据谷歌官网信息,Gemini 2.0 Flash和Gemini 2.0 Flash-Lite侧重轻量级部署,两者的上下文窗口长度最多支持100万个tokens,并且取消了Gemini 1.5 Flash长文本和短文本处理的定价区别,均统一按单位token计价。Gemini 2.0 Flash现每百万tokens文本输出需花费0.4美元,以处理长文本为例,其比Gemini 1.5 Flash的定价便宜了一半。
同时,Lite版本针对大规模文本输出的场景实现了成本优化,每百万tokens文本输出定价0.3美元。谷歌CEO桑达尔·皮查伊(Sundar Pichai)用“高效且强大”来形容这款模型。

除了推出价格更便宜的新模型Gemini 2.0 Flash-Lite,谷歌Gemini 2.0的新变体性能也有所提升。
相比于Lite版,Gemini 2.0 Flash的多模态交互功能更全面一些,按计划可支持图像输出,以及文本、音频、视频等模态的双向实时低延迟输入和输出。

而Gemini 2.0 Pro实验版则是谷歌自称旗下在编码性能和复杂提示方面表现最好的模型。该模型的上下文窗口可达200万个tokens,通用能力较前代的75.8%提升至79.1%,编码和推理能力与Gemini 2.0 Flash、Gemini 2.0 Flash-Lite拉开了明显差距。
Gemini应用程序团队在X上发帖称,Gemini Advanced用户现可通过模型下拉菜单访问Gemini 2.0 Pro实验版,Gemini 2.0 Flash Thinking实验版则免费向Gemini应用用户开放。
此外,该团队透露Gemini 2.0 Flash Thinking实验版可以与YouTube、谷歌搜索和谷歌地图联动使用。
受开源、低成本、高性能DeepSeek-R1推出的影响,模型开发成本成为了圈内热议的话题。
谷歌2024年第四季度财报刚发布不久,在电话会议上,皮查伊先是肯定了DeepSeek所实现的成绩,但同时也提出Gemini系列模型在成本、性能、延迟三者关系的平衡中,仍处于领先地位,且整体表现优于DeepSeek的V3和R1模型。
而从由杨立昆及其团队搭建的LiveBench大模型性能基准测试排行来看,Gemini 2.0 Flash总体排名高于DeepSeek V3和OpenAI的o1-mini,但落后于DeepSeek-R1和OpenAI的o1。
谷歌此次推出的Gemini 2.0 Flash-Lite,可谓代表谷歌打出了一张“价格牌”。
一位长期关注AI玩法、在X上有近万粉丝的网友,试用了DeepSeek V3、GPT-4o-mini、Gemini 2.0 Flash。该网友称新版的Gemini 2.0 Flash在性能和成本上均超过另外两个模型。
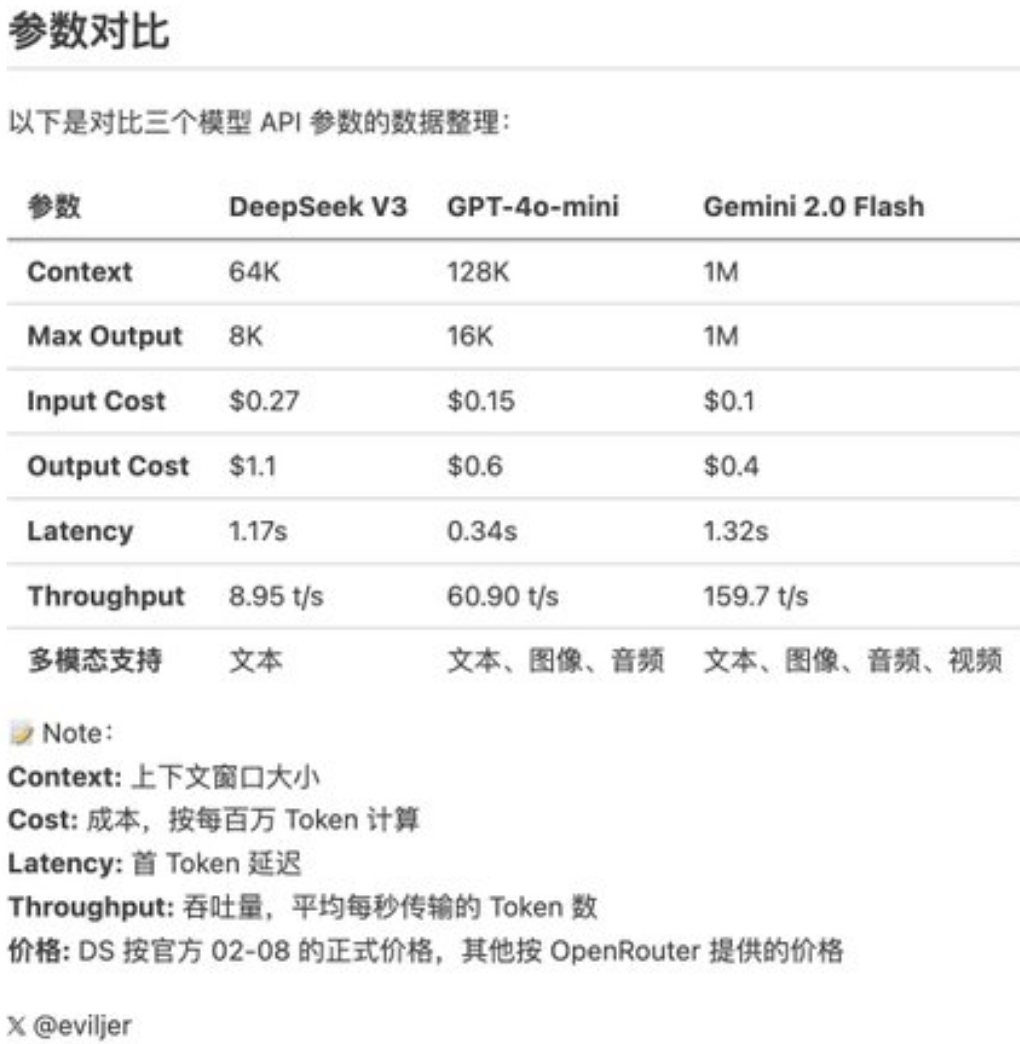
具体来看,Gemini 2.0 Flash每百万tokens的输入成本为0.1美元,输出成本为0.4美元,两项数据均远低于DeepSeek V3。该网友在X上写道:“Gemini 2.0 Flash正式版成本为GPT-4o-mini的三分之一,同时速度是后者的3倍。”

DeepSeek掀起的这波大模型价格战,对海外大模型市场的直接或间接影响仍在持续。
谷歌推出比轻量级还轻量的Gemini 2.0 Flash-Lite,OpenAI向所有用户免费开放了ChatGPT搜索功能,Meta内部团队加紧研究大模型降价策略。
目前来看,大模型领域还没有哪家能稳坐第一的宝座,各项测评数据你追我赶,变相降价吸引和留存用户。卷性价比也有助于大模型从技术开发,真正走向后续的应用落地。
(文:智东西)
