
我是先看到了一张极其意料之外的图
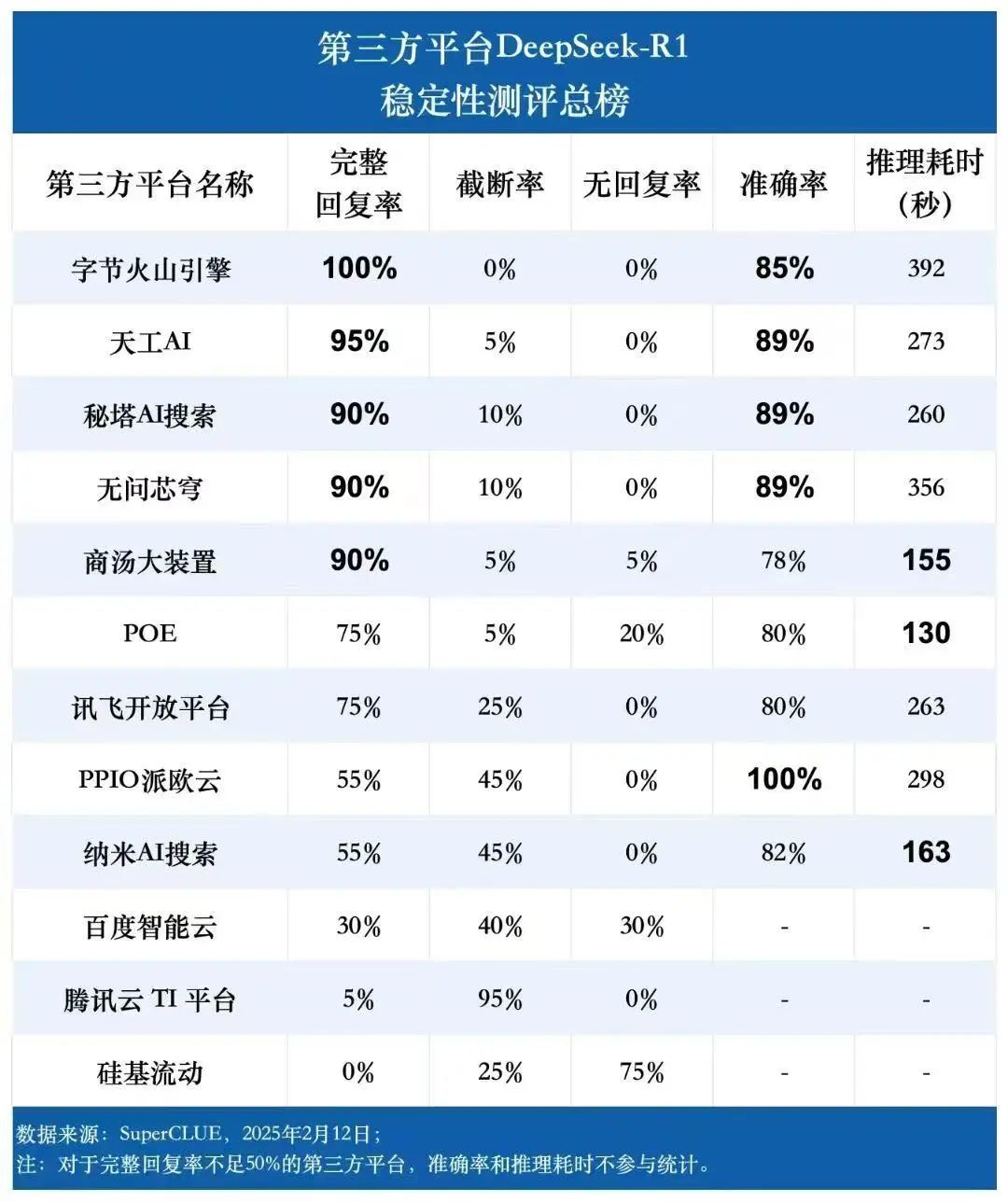
我相信
但凡做过一点开发的
都知道我在说什么
于是我就写了一个测试脚本
来真实测一下主流 API 供应商
DeepSeek 官方 + 阿里/火山/腾讯云 + 硅基流动
首先我要说
除了 DeepSeek 官方,其他家都很稳定
(这里没有吐槽官方的意思,毕竟情况特殊)
至少我没检测到超时或者断开
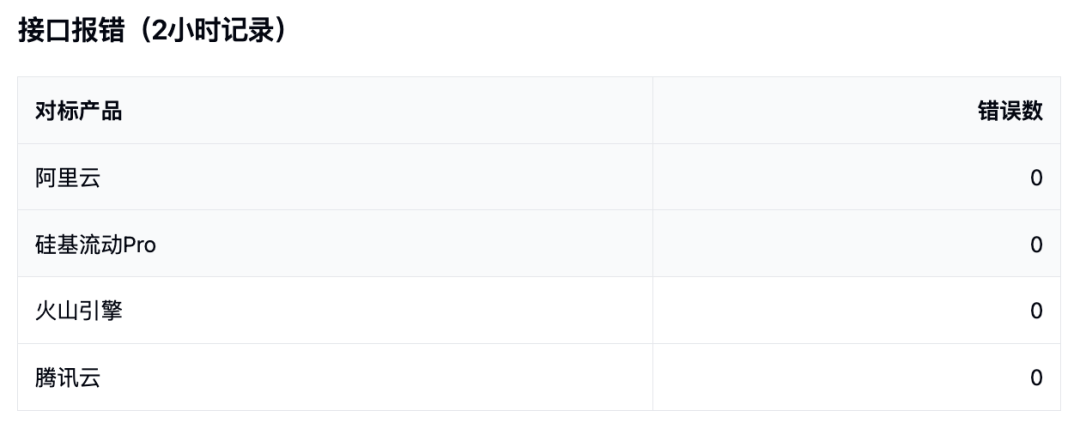
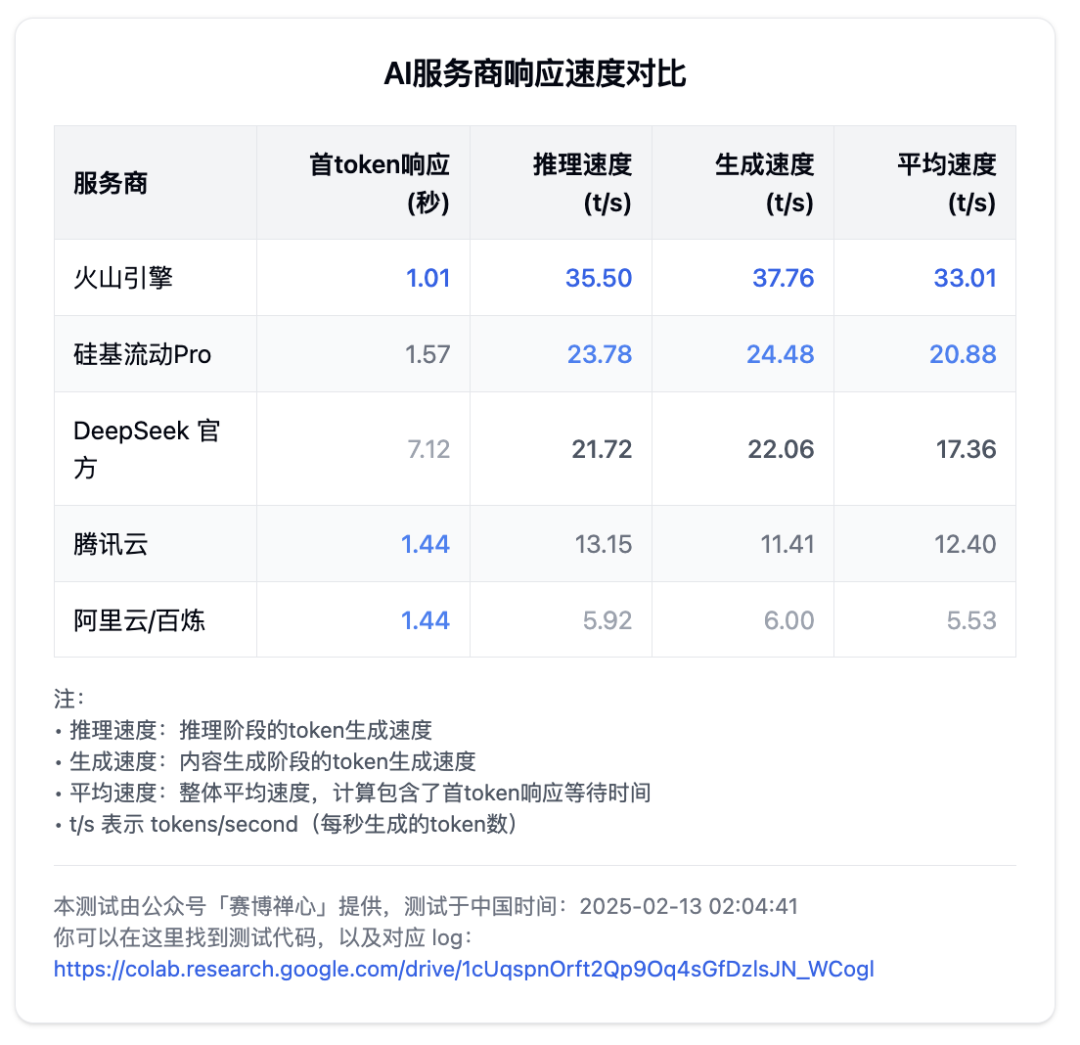
而对于速度
我在中国时间:2025-02-13 02:04:41
进行了测试,结果如下
这里是测试记录
https://colab.research.google.com/drive/1cUqspnOrft2Qp9Oq4sGfDzlsJN_WCogl
测试代码在后面

代码我放在了最后,可以自己跑
这个测试方法一点都不复杂,包含以下步骤:
-
通过 API 向模型服务器发送请求,记录当前时间为 t0
-
当模型返回第一个字符时,记录为 t1,此刻开始推理
-
当模型推理结束、开始生成内容时,记录为 t2
-
当生成结束时,记录为 t3
-
当 stream_options={“include_usage”: True} 的时候,模型会记录并输出以下信息
-
推理阶段所使用的 token,记做:T推
-
生成阶段所使用的 token,记做:T生
-
因此,可知:
-
模型的首响应时间:t1 – t0
-
模型的推理速度:T推/(t2-t1)
-
模型的生成速度:T生/(t3-t2)
-
模型的平均速度:(T推+T生)/(t3-t0)
在这里,我用的 Prompt 也非常简单(对于推理模型来说,太长的 prompt 也没意义)
#测试 prompt:给我写一首七言绝句,赞叹祖国的大好河山
以下是测试切片
测试样本,仅包括我常用的服务商,非常主观
DeepSeek 官方 + 阿里/火山/腾讯云 + 硅基流动
火山引擎:
首 token 响应时间:1.01 秒
Reasoning 部分:318 tokens,用时:8.96 秒,推理速度:35.50 tokens/s
Content 部分:118 tokens,用时:3.12 秒,生成速度:37.76 tokens/s
总体生成:436 tokens,总用时:13.21 秒,平均速度:33.01 tokens/s
硅基流动(Pro):
首 token 响应时间:1.57 秒
Reasoning 部分:180 tokens,用时:7.57 秒,推理速度:23.78 tokens/s
Content 部分:82 tokens,用时:3.35 秒,生成速度:24.48 tokens/s
总体生成:262 tokens,总用时:12.55 秒,平均速度:20.88 tokens/s
DeepSeek 官方:
首 token 响应时间:7.12 秒
Reasoning 部分:496 tokens,用时:22.83 秒,推理速度:21.72 tokens/s
Content 部分:119 tokens,用时:5.39 秒,生成速度:22.06 tokens/s
总体生成:615 tokens,总用时:35.43 秒,平均速度:17.36 tokens/s
腾讯云/腾讯知识引擎:
首 token 响应时间:1.44 秒
Reasoning 部分:629 tokens,用时:47.82 秒,推理速度:13.15 tokens/s
Content 部分:158 tokens,用时:13.85 秒,生成速度:11.41 tokens/s
总体生成:787 tokens,总用时:63.47 秒,平均速度:12.40 tokens/s
阿里云/百炼:
首 token 响应时间:1.44 秒
Reasoning 部分:96 tokens,用时:16.21 秒,推理速度:5.92 tokens/s
Content 部分:34 tokens,用时:5.67 秒,生成速度:6.00 tokens/s
总体生成:130 tokens,总用时:23.51 秒,平均速度:5.53 tokens/s
测试代码如下
import timefrom openai import OpenAIimport datetimeimport pytzdef count_tokens(text):return len(text.split())def test_provider(provider_config, messages):"""根据传入的 provider 配置及消息,测试生成过程,并统计各阶段指标。如果测试过程中出现任何错误,则打印错误信息并跳过当前服务商。"""provider_name = provider_config.get("name", "Unnamed Provider")print(f"\n---------------------------")print(f"开始测试服务商:{provider_name}")print(f"---------------------------\n")try:api_key = provider_config.get("api_key")base_url = provider_config.get("base_url")model = provider_config.get("model")# 初始化客户端(请确保你使用的 OpenAI 客户端支持这些参数)client = OpenAI(api_key=api_key, base_url=base_url)# 初始化 token 计数器与文本变量reasoning_tokens = 0content_tokens = 0overall_tokens = 0reasoning_text = ""content_text = ""# 初始化计时变量start_time = time.time()first_token_time = None# 用于记录 reasoning 与 content 部分开始与结束的时刻reasoning_start_time = Nonereasoning_end_time = Nonecontent_start_time = Nonecontent_end_time = None# 发起流式请求response = client.chat.completions.create(model=model,messages=messages,stream=True,stream_options={"include_usage": True},)# 遍历每个流式响应块for chunk in response:# 若 chunk 中没有 choices 信息,则检查是否有 usage 信息打印后继续if not chunk.choices:if chunk.usage:print("\n\n【Usage 信息】")print(chunk.usage)continue# 获取第一个 choice 的 deltadelta = chunk.choices[0].delta# 尝试获取 reasoning 与 content 片段(可能为空字符串)reasoning_piece = getattr(delta, 'reasoning_content', "")content_piece = getattr(delta, 'content', "")# 记录首个 token 到达时间(仅记录一次)if first_token_time is None and (reasoning_piece or content_piece):first_token_time = time.time() - start_time# 如果有 reasoning 内容if reasoning_piece:if reasoning_start_time is None:reasoning_start_time = time.time()reasoning_text += reasoning_piecetokens = count_tokens(reasoning_piece)reasoning_tokens += tokensoverall_tokens += tokensreasoning_end_time = time.time() # 每次更新,最终记录最后一次收到的时刻print(reasoning_piece, end='', flush=True)# 如果有 content 内容elif content_piece:if content_start_time is None:content_start_time = time.time()content_text += content_piecetokens = count_tokens(content_piece)content_tokens += tokensoverall_tokens += tokenscontent_end_time = time.time() # 每次更新print(content_piece, end='', flush=True)total_time = time.time() - start_timereasoning_time = (reasoning_end_time - reasoning_start_time) if (reasoning_start_time and reasoning_end_time) else 0content_time = (content_end_time - content_start_time) if (content_start_time and content_end_time) else 0# 输出测试指标print("\n\n【%s】" % provider_name)if first_token_time is not None:print(f"首 token 响应时间:{first_token_time:.2f} 秒")else:print("未收到 token 响应。")print(f"Reasoning 部分:{reasoning_tokens} tokens, 用时:{reasoning_time:.2f} 秒, 生成速度:{reasoning_tokens / reasoning_time if reasoning_time > 0 else 0:.2f} tokens/s")print(f"Content 部分:{content_tokens} tokens, 用时:{content_time:.2f} 秒, 生成速度:{content_tokens / content_time if content_time > 0 else 0:.2f} tokens/s")print(f"总体生成:{overall_tokens} tokens, 总用时:{total_time:.2f} 秒, 生成速度:{overall_tokens / total_time if total_time > 0 else 0:.2f} tokens/s")print("\n---------------------------\n")return {"provider": provider_name,"first_token_time": first_token_time,"reasoning_tokens": reasoning_tokens,"reasoning_time": reasoning_time,"content_tokens": content_tokens,"content_time": content_time,"overall_tokens": overall_tokens,"total_time": total_time}except Exception as e:# 如果出现任何错误,则打印错误信息并跳过该服务商print(f"服务商 {provider_name} 测试过程中发生错误:{e}")print("\n---------------------------\n")return Noneif __name__ == "__main__":# 待测试的对话消息(此处为示例:写一首七言绝句赞美祖国大好河山)messages = [{'role': 'user','content': "给我写一首七言绝句,赞叹祖国的大好河山"}]# 定义各服务商的配置providers = [{"name": "DeepSeek 官方","api_key": "你的 API Key", # 请替换为真实 API Key:https://platform.deepseek.com/api_keys"base_url": "https://api.deepseek.com","model": "deepseek-reasoner"},{"name": "阿里云/百炼","api_key": "你的 API Key", # 请替换为真实 API Key:https://bailian.console.aliyun.com/?apiKey=1#/api-key"base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1","model": "deepseek-r1"},{"name": "硅基流动Pro","api_key": "你的 API Key", # 请替换为真实 API Key:https://cloud.siliconflow.cn/account/ak"base_url": "https://api.siliconflow.cn/v1","model": "Pro/deepseek-ai/DeepSeek-R1"},{"name": "火山引擎","api_key": "你的 API Key", # 请替换为真实 API Key:https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey?apikey=%7B%7D"base_url": "https://ark.cn-beijing.volces.com/api/v3","model": "你的接入点" # 火山引擎这里叫接入点,在这里创建:https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint?config=%7B%7D},{"name": "腾讯云","api_key": "你的 API Key", # 请替换为真实 API Key:https://console.cloud.tencent.com/lkeap"base_url": "https://api.lkeap.cloud.tencent.com/v1","model": "deepseek-r1"},]# 循环对每个服务商进行测试print(f"本次测试开始于中国时间:{datetime.datetime.now(pytz.timezone('Asia/Shanghai')).strftime('%Y-%m-%d %H:%M:%S')}")for provider in providers:test_provider(provider, messages)
(文:赛博禅心)