大模型开源力量又加一员!阶跃星辰今天开源了他们的视频生成模型Step-Video-T2V和语音模型Step-Audio。
根据技术报告中的评测结果,阶跃 Step-Video-T2V 的参数量和模型性能目前在全球开源视频生成领域都处于领先水平;而阶跃 Step-Audio 则是业内首款产品级的开源语音交互模型。目前,已经可以在跃问 App 内体验。
以下内容来自官方稿件。
01
阶跃 Step-Video-T2V:
更好的开源视频生成大模型
阶跃 Step-Video-T2V 模型的参数量达到 300 亿,可以直接生成 204 帧、540P 分辨率的高质量视频,这意味着能确保生成的视频内容具有极高的信息密度和强大的一致性。从我们获得的测评结果来看,它是目前全球范围内参数量最大、性能最好的开源视频生成大模型。
为了对开源视频生成模型的性能进行全面评测,我们发布并开源了针对文生视频质量评测的新基准数据集 Step-Video-T2V-Eval。该测试集包含 128 条源于真实用户的中文评测问题,旨在评估生成视频在运动、风景、动物、组合概念、超现实、人物、3D 动画、电影摄影等 11 个内容类别上质量。

(图为 Step-Video-T2V-Eval 评测结果)
评测结果显示,Step-Video-T2V 的模型性能在指令遵循、运动平滑性、物理合理性、美感度等方面的表现均显著超过市面上既有的效果最佳的开源视频模型。
在生成效果上,Step-Video-T2V 在复杂运动、美感人物、视觉想象力、基础文字生成、原生中英双语输入和镜头语言等方面具备强大的生成能力,且语义理解和指令遵循能力突出,能够高效助力视频创作者实现精准创意呈现。
Step-Video-T2V 对复杂运动场景具有优异的把控能力,无论是高雅优美的芭蕾舞、对抗激烈的空手道、紧张刺激的羽毛球,还是高速翻转的跳水,都能展现。在下面这个视频中,模型对熊猫、地面坡度、滑板等多个事物之间的空间关系、大幅度运动的规律都有着深刻的理解,生成的画面真实且符合物理规律。而生成复杂运动,理解物理空间规律也是当下视频生成模型最大的挑战。
Step-Video-T2V 是运镜大师,支持推、拉、摇、移、旋转、跟随等多种镜头运动方式,以及不同景别之间的切换,能够很好地生成大幅度运镜。
Step-Video-T2V 是“十级画师”,生成的人物形象更逼真、更生动,细节更丰富,表情更自然。五官、发型、皮肤纹理都更加细腻。
目前,大家在跃问网页端(https://yuewen.cn/videos)和跃问 App 上,都可以体验 Step-Video-T2V 的视频生成能力 。
Step-Video-T2V相关部署链接、体验入口、技术报告链接:
GitHub:https://github.com/stepfun-ai/Step-Video-T2V
Hugging Face:https://huggingface.co/stepfun-ai/stepvideo-t2v
技术报告:https://arxiv.org/abs/2502.10248
02
阶跃 Step-Audio:
业内首款产品级开源语音交互模型
阶跃 Step-Audio 是行业内首个产品级的开源语音交互模型,能够根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,能和用户自然地进行高质量对话。模型生成的语音具有自然流畅、情商高等特征,同时也能支持不同角色的音色克隆,满足影视娱乐、社交、游戏等行业场景下应用需求。

在 LlaMA Question、Web Questions 等五大主流公开测试集中,Step-Audio 模型性能均超过了行业内同类型开源模型,位列第一。Step-Audio 在 HSK-6(汉语水平考试六级)评测中的表现尤为突出,是最懂中国话的开源语音交互大模型。比如下面这段对话中,模型能够深入理解中文的博大精深,而不会被「绕晕」。
Step-Audio 也具有高情商的特征,熟知人情世故,当用户面临各种人生问题,它都可以像好朋友一样提供贴心陪伴并帮你出主意。
Step-Audio 也是「韵律大师」,它不仅能理解语言的韵律和节奏,更能将这些元素巧妙地编织成一段动感十足的 Rap。
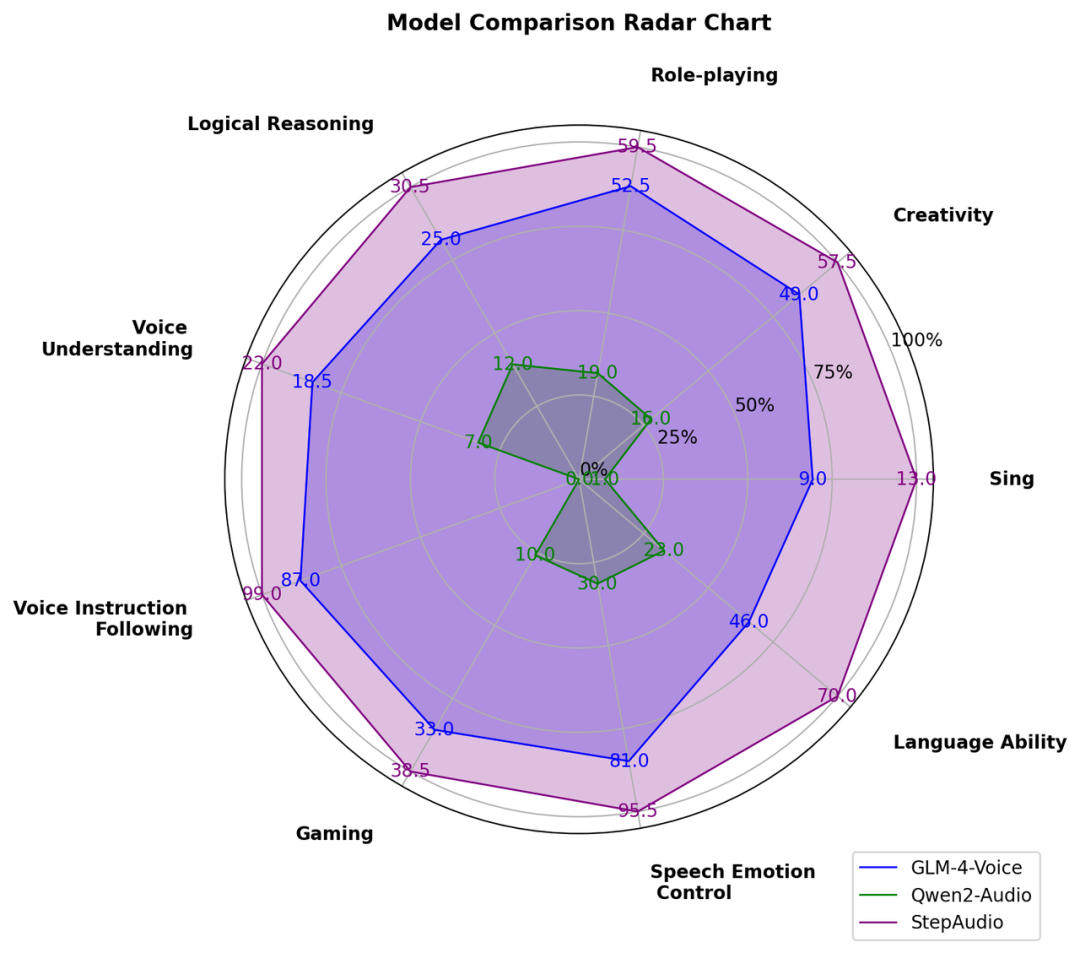
此外,由于目前行业内语音对话测试集相对缺失,我们自建并开源了多维度评估体系 StepEval-Audio-360 基准测试,从角色扮演、逻辑推理、生成控制、文字游戏、创作能力、指令控制等 9 项基础能力的维度对开源语音模型进行全面测评。通过人工横评后的结果显示,Step-Audio 的模型能力十分均衡,且在各个维度上均超过了此前市面上效果最佳的开源语音模型。
模型及技术报告链接如下,
GitHub:https://github.com/stepfun-ai/Step-Audio
Hugging Face:https://huggingface.co/collections/stepfun-ai/step-audio-67b33accf45735bb21131b0b
技术报告:https://github.com/stepfun-ai/Step-Audio/blob/main/assets/Step-Audio.pdf
(文:Founder Park)