
X-R1更新日志
-
2025.02.16 Support LoRA -
2025.02.15 Release Chinese Training -
2025.02.13 Release X-R1-3B, whick better follow format. colab inference -
2025.02.12 Release X-R1-1.5B config/wandb/model/log
0.5B/1.5B/3B 全开源
X-R1增加标准R1-Zero的训练脚本,一键运行训练0.5B/1.5B/3B 的标准实验:
bash ./scripts/run_x_r1_zero.sh
训练过程数据全公开,并且提供了在线的Colab平台测试程序
📈 wandb details | 🔥 Colab Inference | 🤗 Models
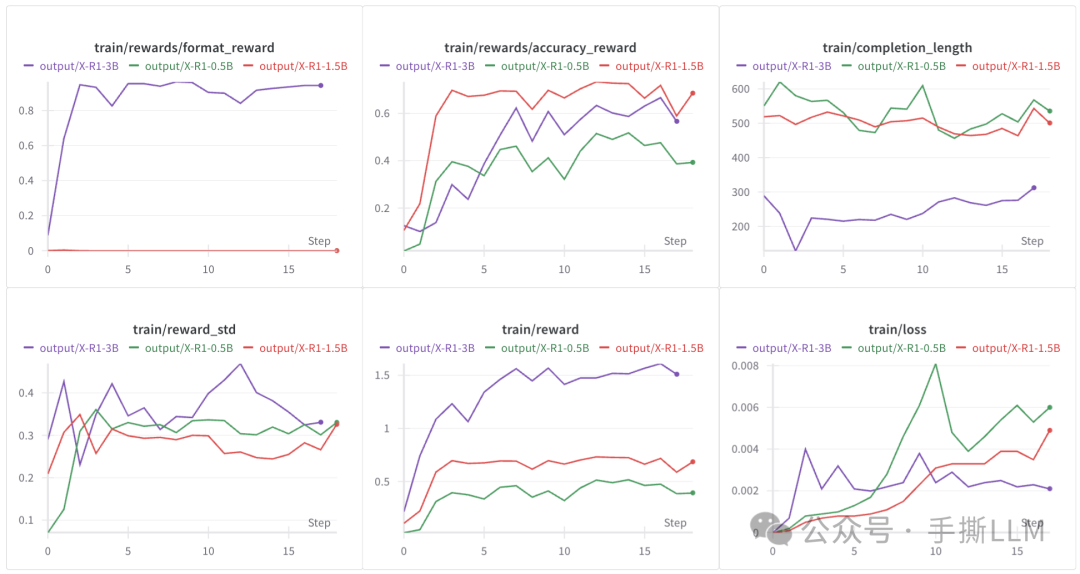
X-R1在没有SFT的情况下, 在4x3090(24G) GRPO训练0.5B/1.5B/3B ,模型通过纯强化学习训练得到了推理能力和格式跟随能力(3B模型格式奖励曲线),结果令人振奋。
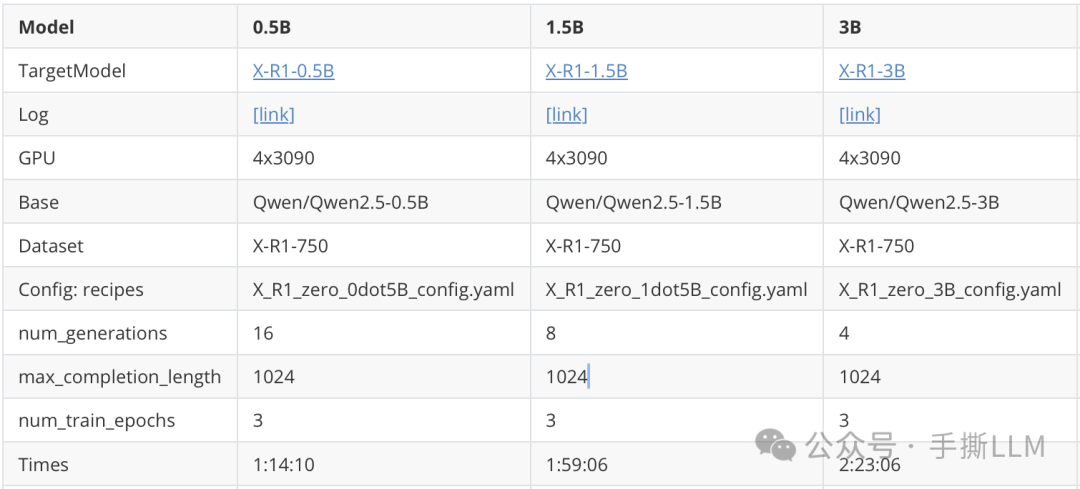
训练配置如下:
X-R1中文推理适配
X-R1 支持中文推理能力训练, 在3B模型非常容易就能得到显著的推理效果
ACCELERATE_LOG_LEVEL=info \
accelerate launch \
--config_file recipes/zero3.yaml \
--num_processes=3 \
src/x_r1/grpo.py \
--config recipes/examples/mathcn_zero_3B_config.yaml \
> ./output/mathcn_3B_sampling.log 2>&1
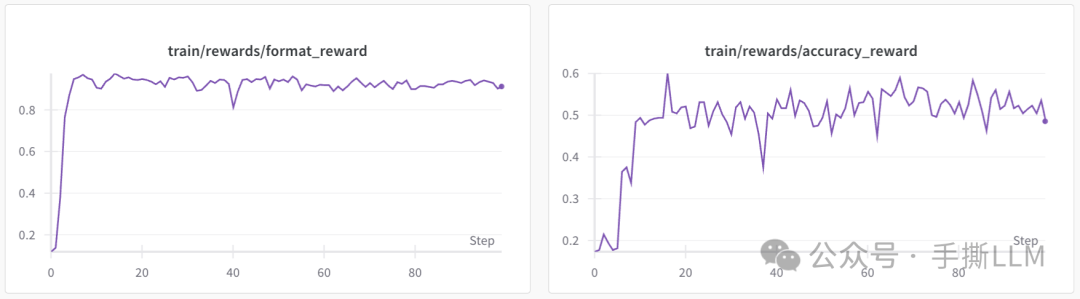
奖励曲线📈
X-R1 使用 4x3090 约16小时训练3B的基础模型,使用包含中文数学题的7500 条训练数据,得到以下训练曲线:
中文推理效果
我们将训练的模型X-R1-3B-CN 已公开,如下为训练过程中的学习推理例子,该推理输出遵循格式,并且成功推理出了答案。


🔥支持LoRA训练
为了进一步减少训练显存需求,X-R1支持LoRA训练,目前可以支持单卡3090(24G)显卡做7B模型的GRPO训练。我们提供一个简易的运行例子:
ACCELERATE_LOG_LEVEL=info \
accelerate launch \
--config_file recipes/zero1.yaml \
--num_processes=1 \
src/x_r1/grpo.py \
--config recipes/X_R1_zero_0dot5B_peft_config.yaml \
> ./output/x_r1_test_sampling.log 2>&1
在*.yaml 配置文件中, 可以增加以下参数,似得训练可以用LoRA微调
-
如下 lora_target_modules可以标识需要增加LoRA适配器的网络层名,示例在Qwen2.5模型上对注意力层的Q、K、V和输出层增加微调参数,在7B模型中可以将embed_tokens改动为lm_head
lora_r: 32
lora_target_modules: ["q_proj","v_proj", "k_proj", "embed_tokens"]
lora_alpha: 8
lora_dropout: 0.0
bias: "none"
use_peft: true
快速开始
配置更加简易,在 cuda>=12.4环境可以快速安装,并且支持flash-attn 训练
conda create -n xr1 python=3.11
conda activate xr1
pip install -r requirements.txt
pip install flash-attn
另外X-R1 也在华为Ascend 910B上运行成功。🚀
其他
-
X-R1将支持LLM-As-a-Judge评判奖励 -
X-R1将提供垂直领域(如医疗)的R1-Zero的复现,进一步赋能业务场景 -
X-R1将增加标准测评集上的结果如MATH500和AIMO
开源仓库
开源地址:
https://github.com/dhcode-cpp/X-R1
(文:PaperAgent)