
腾讯在集成 DeepSeek-R1 模型的道路上越走越远。
2月17日,腾讯文档官宣已为旗下的“AI文档助手”接入 DeepSeek-R1 模型。
这意味着,腾讯已为商业生态内的5个版块接入了 DeepSeek-R1 模型,它们分别是:
-
AI 智能工作台ima -
腾讯元宝 -
QQ音乐 -
微信 -
腾讯文档
这一次,腾讯真的是全面拥抱 DeepSeek-R1!毕竟,用户体验好才是第一位的。
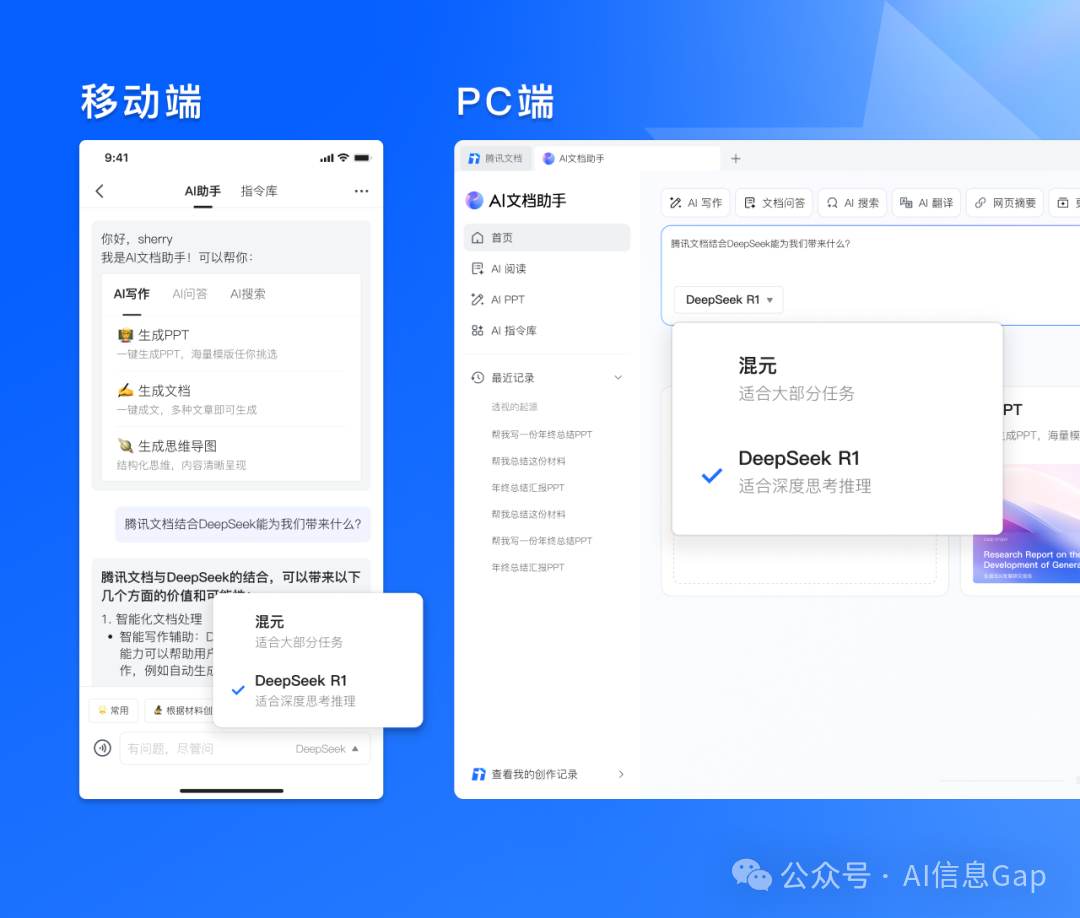
接入了 DeepSeek-R1 的腾讯文档实现了全客户端支持:微信小程序、网页端、移动app、PC端全部覆盖。
以网页端为例,腾讯文档的“AI文档助手”地址是这个。
https://docs.qq.com/ai
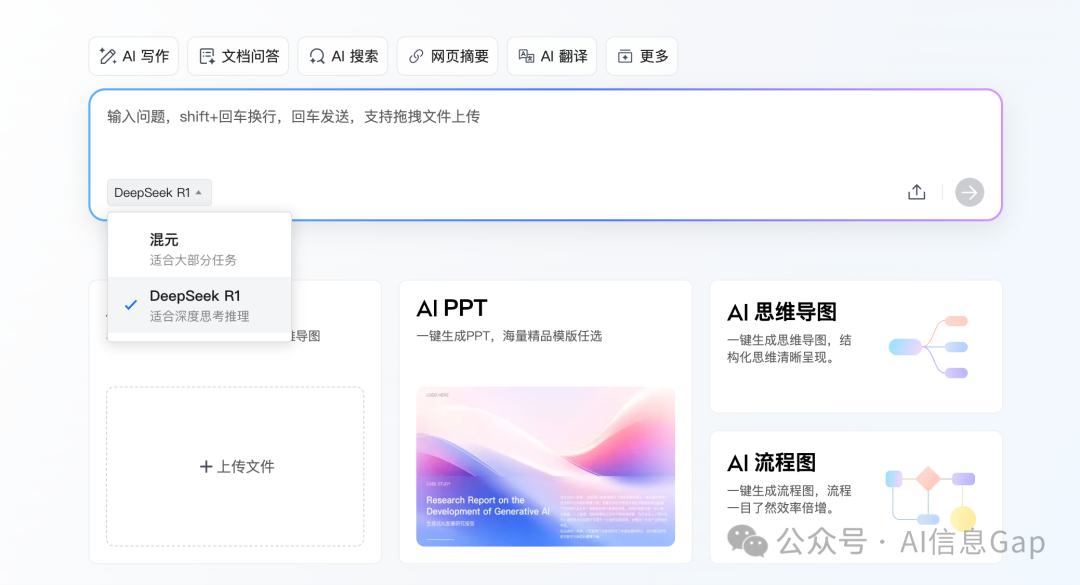
和腾讯元宝、微信里的“AI搜索”一样,腾讯AI文档助手也支持2个模型切换:腾讯自家的 混元大模型 以及 DeepSeek-R1。其中,混元大模型 是一个不会思考的通用模型,建议上点强度的任务还是选择 DeepSeek-R1 吧。
腾讯AI文档助手的核心功能都是围绕“知识服务”展开。比如 文档问答。
点击首页的 文档问答 进入基于文档的问答模式。
比如让它帮我读财报。以英伟达25财年Q3的最新财报为例。
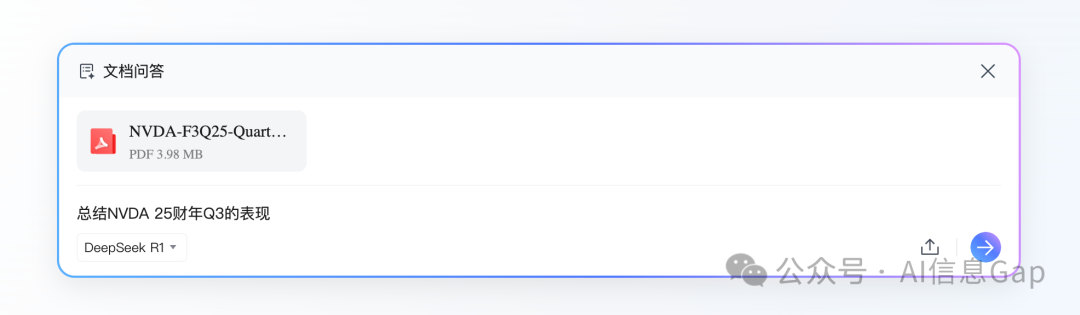
我先让它总结一下。DeepSeek-R1 在思考了41秒后,给出了下面这个答案。总体来说表现不错。

而这是 DeepSeek-R1 的思考过程,总体来看也没什么问题。然而在测试过程中,个人感觉腾讯文档里的 DeepSeek-R1 思考和回答过程中都有非常明显的卡顿和延迟,输出很不流畅,猜测可能是因为用户量太大的原因。

接下来是 AI写作。因为腾讯文档的 DeepSeek-R1 和元宝、微信AI搜索一样,都带有“联网搜索功能”,所以我让它写一篇关于“Grok 3”的文章。理论上说,它应该能搜索到相关信息,然后整合成一篇文章。
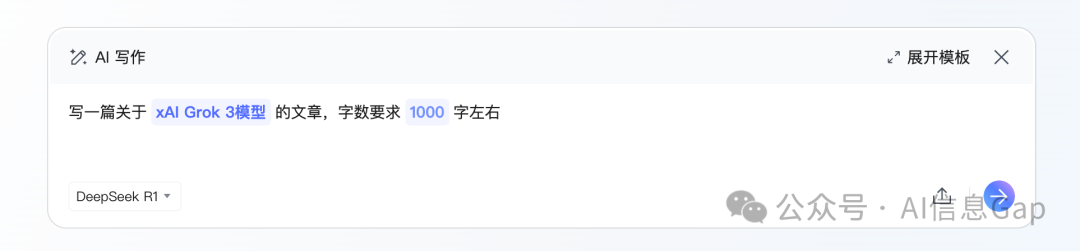
结果,虽然看上去 DeepSeek-R1 洋洋洒洒写了一堆内容,但是,有价值的却不多。确实是联网搜索了,但仅仅引用了3篇资料;另外对比发现,腾讯文档的 DeepSeek-R1 生成的内容可以说和查找到的资料毫不相关,所以生成的文章里出现了大量的“莫须有”的描述。

这是它的思考过程。合理推测 DeepSeek-R1 的思考和生成过程受到了引用源和系统提示词的影响。

当我尝试用 DeepSeek-R1 + 联网搜索功能时,被告知“本场景不支持DeepSeek”。
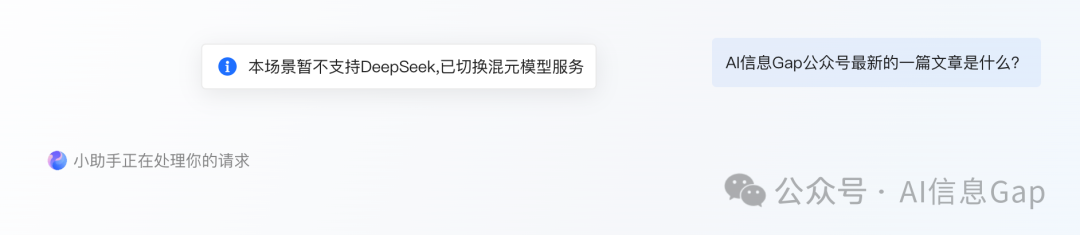
腾讯文档里的 DeepSeek-R1 综合体验不是很好,让我不禁怀疑这是不是满血版,虽然腾讯文档官方一再强调集成的是满血版的 DeepSeek-R1。
从“鸡你太美”这个测试来看,确实是满血版无疑。虽然第一次它竟然还回答错了。
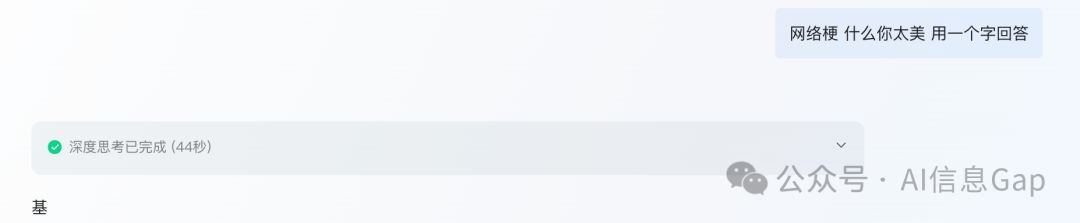
又问了一遍,回答正确。

奇怪的是,当我在问题后面加上“禁止搜索”后,就会自动切换为“混元模型”(表现为:不思考了),以至于得到很离谱的错误回答。

结语
在有这么多满血版 DeepSeek-R1 可以使用的当下,腾讯文档的这个版本不是很推荐使用。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)