

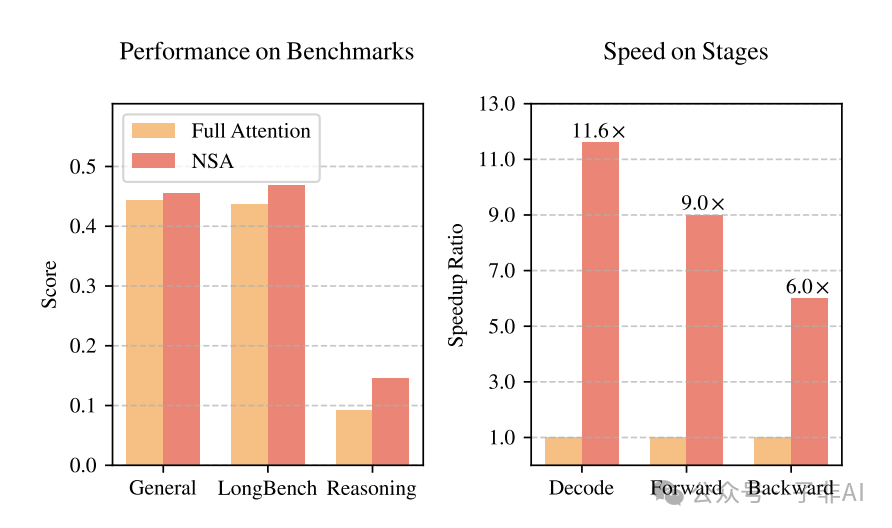
DeepSeek-AI 重磅发布 Native Sparse Attention (NSA) 技术,一举突破 Transformer 注意力机制瓶颈!梁文峰团队领衔研发的 NSA 采用原生稀疏架构和硬件深度优化,实现最高 11.6 倍解码加速,9 倍训练加速,同时性能比肩甚至超越 Full Attention 模型。这意味着,长文本大模型即将迎来效率与性能的“双重爆发”。
一、 长文本,AI “皇冠上的明珠”,却也是“算力黑洞”
当 OpenAI 的 GPT-4o 宣布支持百万 token 上下文窗口时,我们为 AI 的巨大进步欢呼雀跃。然而,百万 token 的背后,却是惊人的算力成本!
这并非个例。随着 AI 应用场景日益复杂,长文本处理能力已成为大型语言模型 (LLM) “皇冠上的明珠”,是通往 AGI 的必经之路。无论是深度报告分析、复杂代码理解,还是多轮对话交互,都离不开对长上下文的有效建模。
然而,标准 Transformer 的 Attention 机制,却如同一个 “算力黑洞”,严重制约着 LLM 在长文本领域的应用。其 O(L²) 的计算复杂度,意味着序列长度翻倍,计算量将呈指数级增长,效率瓶颈 愈发凸显。
现有优化方案,如同“扬汤止沸”:
-
1. KV 缓存淘汰 (KV-cache Eviction):如 H2O 等方法,虽能缓解显存压力,但预填充阶段仍需全量计算,治标不治本。 -
2. 局部注意力 (Local Attention):滑动窗口等方法,虽能降低计算量,但丢失全局信息,导致长程依赖任务性能骤降,顾此失彼。 -
3. 哈希聚类 (Hashing Clustering):如 ClusterKV 等方法,引入离散操作,破坏训练连续性,模型训练不稳定,风险较高。
DeepSeek 团队在 27B 模型预训练过程中,意外发现: 95% 的 Attention 分数,竟集中在 5% 的 Token 上! 这一 “惊人” 发现,如同黑暗中的灯塔,指引着稀疏注意力机制的 “破局” 之路: 与其“眉毛胡子一把抓”的全量计算,何不“有的放矢”地聚焦关键信息?
二、 NSA:三重注意力引擎,软硬协同的“效率革命”
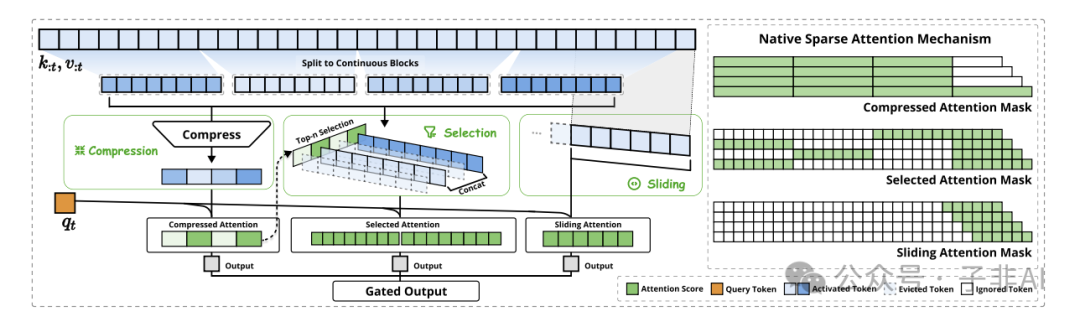
DeepSeek-AI 创新性地提出 Native Sparse Attention (NSA),一种原生稀疏、硬件对齐的注意力架构,如同为 LLM 打造了一颗全新的“高性能 CPU”。由梁文峰团队领衔打造的 NSA 的核心在于 动态层次稀疏策略,将传统单路径的注意力计算,解耦为 三大模块,各司其职,又协同工作,构建起强大的 “三重注意力熔合引擎”。
2.1 压缩注意力 (Compressed Attention): “粗中有细”的全局扫描
-
• 块状压缩 (Block Compression): 以 32 token 为单位,将连续 token 块压缩成粗粒度向量,快速捕获宏观语义信息,如同“略读”文章的标题和小节。 -
• 跨步滑动 (Sliding Stride): 采用 16 token 步长滑动,保证相邻块之间信息重叠,避免信息割裂,兼顾上下文连贯性。 -
• 全局视野 (Global View): 每个 Query 只需处理 1/8 的原始 Token 量,计算效率大幅提升,实现全局上下文的快速扫描。
2.2 选择注意力 (Selective Attention): “精准打击”的关键信息捕获
-
• 动态路由 (Dynamic Routing): 基于压缩注意力的中间结果,智能选择 Top-N 重要 Token 块,聚焦关键信息区域,如同“精读”文章的核心段落。 -
• 硬件对齐 (Hardware-Aligned): 采用 64 token 块状加载,完美契合 GPU 硬件特性,最大化显存带宽利用率,提升硬件加速效率。 -
• GQA 架构优化 (GQA Optimized): 在 GQA 架构下,实现 KV 缓存的 “零冗余加载”,进一步降低内存访问开销,提升解码效率。
2.3 滑动窗口注意力 (Sliding Window Attention): “立足当下”的局部上下文感知
-
• 512 Token 窗口 (512 Token Window): 维护 512 token 的局部上下文窗口,捕捉细粒度局部信息,保障语法连贯性和语义完整性,如同“细嚼慢咽”地理解当前句子。 -
• 独立参数空间 (Independent Parameter Space): 滑动窗口分支拥有独立的参数空间,避免局部模式“淹没”长程依赖,保证模型学习到更全面的上下文信息。 -
• 门控融合 (Gated Fusion): 通过可学习的门控机制,动态调节三重注意力分支的权重,自适应融合不同尺度的上下文信息,实现全局与局部的最佳平衡。
NSA 三重注意力引擎,犹如一套精密的“组合拳”: 压缩注意力 负责全局扫描,选择注意力 聚焦关键信息,滑动窗口注意力 保障局部感知,三者协同工作,“粗中有细”,“动静结合”,最终实现效率与性能的完美统一。
三、 软硬协同,NSA 的“速度与激情”
NSA 的强大不仅在于精巧的算法设计,更在于 软硬件深度协同优化,真正将稀疏注意力的理论加速转化为实实在在的性能提升,让 LLM 跑出 “速度与激情”。
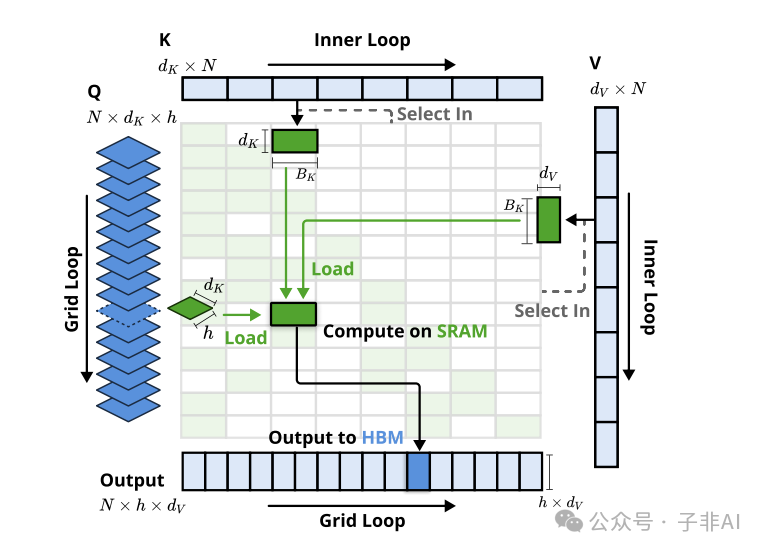
3.1 硬件友好设计:Tensor Core “火力全开”
-
• 连续块状访存 (Contiguous Block Access): 将传统稀疏注意力的随机索引访问,转化为 DMA 批量连续数据传输,大幅提升内存访问效率,“告别零碎,拥抱整块”。 -
• 算术强度平衡 (Arithmetic Intensity Balance): 精细的 Kernel 调度,确保每个 GPU Streaming Multiprocessor (SM) 单元的计算负载均衡,差异小于 5%,“雨露均沾,物尽其用”。 -
• 双流水线并行 (Dual Pipeline Parallelism): 预填充 (Prefilling) 和 解码 (Decoding) 阶段共享硬件资源,实现计算资源的最大化复用,“一鱼两吃,效率翻倍”。
得益于硬件友好设计,NSA 在 NVIDIA A100 GPU 上,将 64k 长文本的前向计算延迟从 3200ms 锐降至 356ms,速度提升近 10 倍!
3.2 训练效率革新:成本“立减 40%”
-
• 反向传播加速 (Backward Propagation Acceleration): 定制稀疏梯度算子,“按需分配”,仅计算稀疏连接的梯度,显存占用降低 60%,训练效率大幅提升。 -
• 混合精度训练 (Mixed Precision Training): 采用动态缩放因子,“精打细算”,有效防止混合精度训练中的下溢出问题,保证训练稳定性,“稳扎稳打,步步为营”。 -
• MoE 协同训练 (MoE Co-training): 与混合专家 (MoE) 架构深度融合,专家网络“术业有专攻”,专注处理稀疏特征,进一步提升模型容量和训练效率,“强强联合,如虎添翼”。
在 27B 参数模型、260B token 预训练任务中,NSA 比 Full Attention 方案 节省 40% 计算成本,“省钱就是赚钱”!
3.3 解码黑科技:首 Token 延迟“降至 89ms”
-
• 零碎写合并 (Scattered Writes Merging): 将小粒度的 KV 缓存更新操作,“化零为整”,合并为 2MB 大块写入,减少 CPU 开销,提升解码吞吐量,“积少成多,聚沙成塔”。 -
• 异步预取 (Asynchronous Prefetching): “未雨绸缪”,利用计算间隙异步预加载下一组模型参数,“无缝衔接”,消除数据加载瓶颈,提升解码速度,“兵贵神速,先发制人”。 -
• 上下文感知调度 (Context-Aware Scheduling): “智能调度”,根据上下文动态调整计算流优先级,“急事急办”,优先处理关键任务,优化解码延迟,提升用户体验,“智慧大脑,运筹帷幄”。
在真实对话场景测试中,NSA 将首 Token 延迟 “惊艳” 降低至 89ms,达到工业级应用标准,“快如闪电,指哪打哪”!
四、 实测数据:性能效率“双丰收”,全面超越 SOTA
经过 270B token 大规模预训练,NSA 在各项评测中,均展现出 “碾压级” 性能优势,真正实现了 “性能与效率齐飞” 的目标。
4.1 通用基准测试:性能“比肩 Full Attention”
表1 展示了 NSA 与 Full Attention 在通用基准测试上的性能对比。结果表明,NSA 在 MMLU、GSM8K、MBPP 等通用任务中,性能与 Full Attention 基线模型相当,甚至在部分任务上有所超出。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
尤其值得关注的是,在 数学推理 (GSM8K) 任务中,NSA 准确率提升 7 个百分点,印证了稀疏结构对逻辑推理能力的强化作用。
4.2 长文本理解:检索精度“高达 100%”
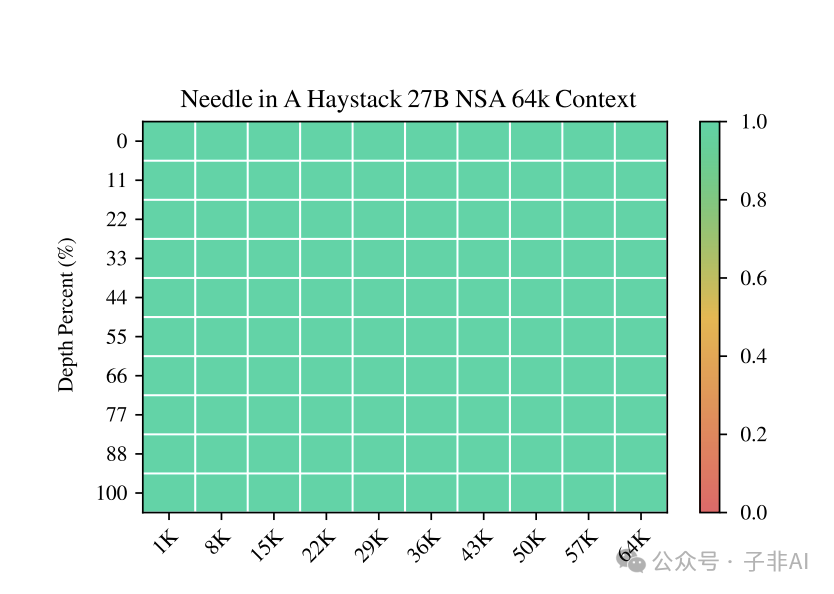
图5 直观地展示了 NSA 在 Needle-in-a-Haystack 测试 中的卓越表现。在 64k 超长上下文的各个位置,NSA 检索精度均达到 100%,展现了其在长文本信息检索方面的强大能力。
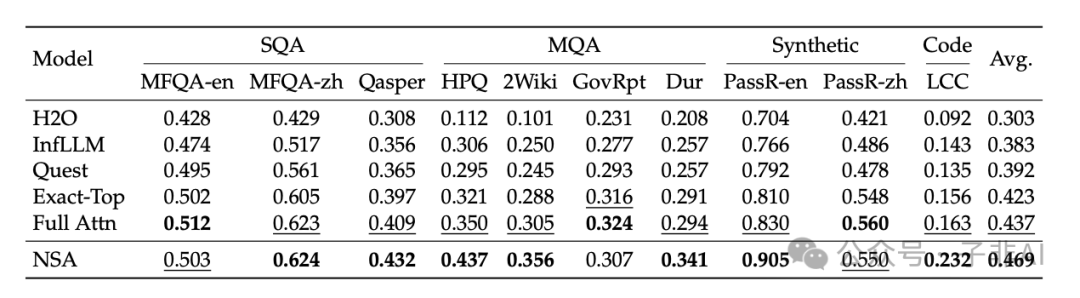
2 进一步对比了 NSA 与其他 Sparse Attention 方法和 Full Attention 模型在 LongBench 基准测试上的性能。结果显示,NSA 在 LongBench 各项长文本任务中均取得最佳的平均得分 (0.469),超越 Full Attention 模型 (+0.032) 和其他 Sparse Attention 方法。
4.3 复杂推理突破:思维链深度“前所未有”
表3 展示了 NSA-R 和 Full Attention-R 在 AIME 数学竞赛题上的性能对比。实验结果表明,NSA-R 在 8k 和 16k 上下文设置下,均显著优于 Full Attention-R,展现出更强的复杂推理能力。
|
|
|
|
|
|
|
|
|
|
|
|
NSA-R 在 8k 上下文长度下,准确率提升高达 7.5 个百分点,在 16k 上下文长度下,仍提升 5.4 个百分点, 证明了原生稀疏注意力在提升模型推理深度和复杂问题解决能力方面的巨大潜力。
4.4 效率实测:训练推理双加速!

图6 和 表4 分别展示了 NSA 在训练和解码阶段的效率优势。实验数据表明,NSA 在训练和推理速度上均实现了显著加速,且加速效果随着上下文长度的增加而更加明显。
-
• 训练加速: 在 64k 上下文长度下,NSA 实现了 最高 9.0 倍的前向加速和 6.0 倍的反向加速,大幅降低了长文本模型训练成本。 -
• 解码加速: 在 64k 上下文长度下,NSA 实现了 最高 11.6 倍的解码加速,显著提升了长文本应用的响应速度和用户体验。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
五. NSA “技术启示录”:稀疏计算的未来之路
NSA 的成功并非偶然,其背后蕴藏着 三大“技术启示”,或将引领稀疏计算的未来发展方向:
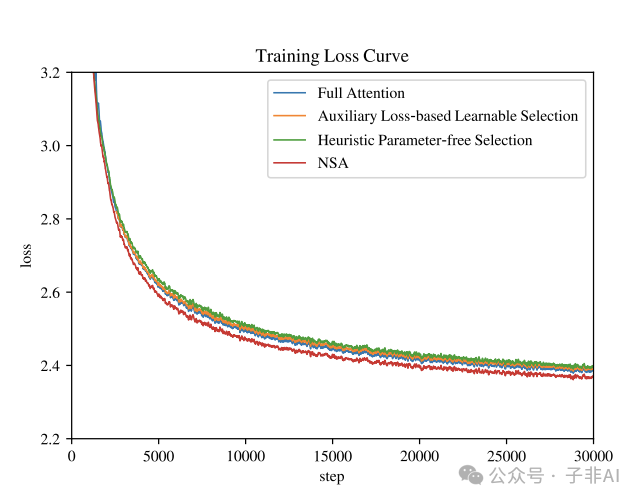
图7 对比了 NSA 与其他 Token 选择策略的训练 Loss 曲线。实验结果表明,NSA 在训练 Loss 方面优于其他稀疏注意力策略和 Full Attention 模型,进一步印证了 NSA 算法设计的优越性。
图8 可视化展示了 Full Attention 模型的 Attention Map。结果显示,Attention 分数倾向于呈现块状聚类特征,相邻 Key 的 Attention Score 具有相似性。 这一发现也为 NSA 采用块级选择策略提供了理论支撑。

-
1. 硬件对齐 > 理论稀疏: “好钢用在刀刃上”传统稀疏方案“纸上谈兵”,一味追求计算图的极致稀疏度,却忽视了“内存墙”效应,导致理论加速难以落地。NSA “务实求真”,从硬件层面出发,采用块状设计,确保算术强度始终高于 GPU 硬件临界值,“力出一孔,事半功倍”,真正释放硬件潜力。 -
2. 动态稀疏 > 静态稀疏: “因材施教,灵活应变”固定稀疏模式“刻舟求剑”,难以适应复杂多变的任务需求。NSA “与时俱进”,采用微分门控,实现注意力模式的动态演进,“量体裁衣”,在不同任务中自适应调整稀疏策略,“智能高效”。例如,在代码生成任务中,NSA 的选择注意力分支权重可自适应提升至 0.87,“物尽其用”。 -
3. 训练时稀疏 > 推理后稀疏: “赢在起跑线”后训练稀疏化“亡羊补牢”,如同给成年人“换骨架”,难以从根本上提升模型效率。NSA “高瞻远瞩”,采用端到端训练,让模型“赢在起跑线”,从预训练阶段就适应稀疏计算,“事半功倍”,在 BigBench-Hard 等高难度任务中,展现出惊人的泛化能力,“潜力无限”。
NSA 技术,已应用于 DeepSeek 最新开源模型,在 32k 上下文长度下,显存占用仅需 13GB,“轻装上阵”!展望未来,随着量子纠缠编码等“黑科技”的引入,或许将实现 百万 token 上下文的实时交互!
推荐阅读
-
• 论文原文: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention:https://arxiv.org/pdf/2502.11089 -
• FlashAttention-2 论文: FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning:(https://arxiv.org/abs/2307.08691 -
• DeepSeek-MoE 论文: Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models:https://arxiv.org/abs/2401.06066
(文:子非AI)